Какие бывают поисковые системы. Какие существуют поисковые системы
Доброго всем времени суток, мои дорогие друзья и читатели моего блога. Сегодня я вам хочу рассказать про самые известные поисковые системы в интернете на русском языке. Ресурсы сети Интернет используются для каждодневной работы и отдыха огромного количества людей.
А для того, чтобы получить то, что нужно или интересно используются поисковые системы, которые представляют собой аппаратно-программный комплекс для быстрого поиска необходимой пользователю информации, хранящейся на серверах (специальных компьютерах) Интернета.
Частота использования поисковой системы определяется, во-первых, тем насколько актуальные данные она предоставляет, а во-вторых, как быстро она это делает. Основными критериями для выбора являются:
- полнота и точность найденных результатов;
- актуальность данных;
- скорость нахождения;
- наглядность интерфейса.
В России наиболее востребованы такие поисковики, как Yandex, Mail, Rambler и некоторые другие. Но я хотел бы вам предоставить более подробный список этих систем, чтобы вы имели более полное представление обо всем этом.
Yandex.ru – наиболее популярна в пределах русскоязычного Интернета. Поисковые запросы можно писать как на английском, так и на русском языке. Девиз сайта Яндекс «Найдется все!» и действительно, им обеспечивается качественное и быстрое предоставление информации.
Лично я этим поисковиком пользуюсь же более 10 лет по умолчанию и мне он безумно нравится. А для любого веб-мастера он имеет просто огромное значение, так как любой из них в лепешку расшибается ради того, чтобы его сайт находили именно в этой системе.
Он обладает огромной индексной базой, а значит, может найти практически все. Вывод найденной информации отличается рациональностью. Яндекс непрерывно развивается. Он предлагает все больше востребованных сервисов, например, новости, карты, прогноз погоды, электронная почта, Яндекс. деньги. Кстати я тут писал , так что если вас это интересует, то обязательно почитайте.
На сегодняшний момент доля использования яндекса в России составляет около 56 процентов . То есть большая часть населения страны предпочитает использовать именно этот обозреватель.
А вот и главный конкурент вышеупомянутого Яши. Да, система эта конечно не русская, но зато один из ее основателей — это наш соотечественник Сергей Брин. Правда его увезли в штаты еще будучи ребенком, поэтому врядли его можно назвать русским. Если вам интересно, то вы можете почитать , которые я для вас собрал.
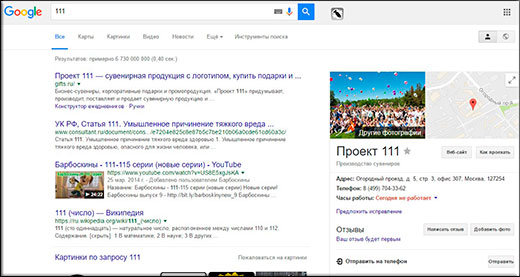
Как бы то ни было, гугл является самой популярной системой в мире и пока еще второй по популярности в России.
На сегодняшний 38 процентов всех поисковых запросов России проходит именно через гугл
Поиск Mail.ru
У русскоязычных пользователей сети очень популярна почта mail.ru. Но не очень многие используют одноименный поисковик. Сам по себе он обычный и ничем не примечательный, поэтому против таких конкурентов, как вышеупомянутые яндекс и гугл, ему пока не выстоять. Хотя я сомневаюсь, что он будет пытаться покорять вершины поисковых систем. Ему вполне достаточно, что у него самая популярная почта России. Но всё же свои 5 процентов от общего числа запросов он имеет.

Кроме того сайт содержит огромное количество приложений, интересных игр, а также имеет собственную социальную сеть. Разработаны приложения позволяющие производить поиск по голосу.
Rambler.ru
Rambler – это один из наиболее ранних вариантов и раньше это была одна из самых популярных поисковых систем на русском языке, наравне с яндексом. И первые пару лет я активно использовал его в качестве поисковой системы по умолчанию, пока не перешел на Яндекс. Сейчас он используется не очень активно (я бы даже сказал совсем не активно), хотя он обладает неплохим качеством и отличной скоростью.

Он является также популярным медийным порталом Рунета, на котором можно использовать почту, узнать последние новости о самых разных сферах жизни. Кстати именно какмедийно-новостной портал он зарекомендовал себя вполне неплохо и я знаю многих людей, которые специально идут именно на рамблер, чтобы почитать последние новости.
Несмотря на свою былую популярность, рамблеру сегодня принадлежит меньше 0,5 процентов от общего количества запросов в интернете.
WebAlta.ru
WebAlta — один из новых российских поисковиков. Он неплохо развивается и уже отражает более 1 миллиарда документов, что является хорошим результатом. Он легко настраивается в соответствии с предпочтениями пользователей. Настройка визуализирована, и смена запроса сразу же отражается на результатах.

Но как же он меня раздражал пару лет назад, когда после установки какого-либо приложения вебальта вставала в качестве домашней страницы и поисковика по умолчанию. Я вообще думал, что это вирус какой-то. Поэтому еще раз скажу: « ».
Ну а насчет доли поискового трафика даже и говорить не буду, так как он ничтожно мал.
Nigma.ru
Nigma – это современная российская интеллектуальная метапоисковая система. Она использует современный кластерный подход, что улучшает качество и полноту процесса. Сайт включает математическую и химическую подсистемы для решения самых разных задач и стандартные пользовательские сервисы.

Но пока это наверное наименее популярный сервис из всех представленных выше. Хотя можете попробовать его в деле. Быть может вам всё понравится). Ну и насколько вы поняли, трафик тут также настолько низкий, что его можно даже не включать.
Скажите пожалуйста, какими поисковыми системами вы пользуетесь? Я спрашиваю не просто так. Дело в том, что недавно я узнал, что один мой знакомый пользуется рамблером. И если честно, то я был удивлен, что кто-то из моих знакомых пользуется не яндексом или гуглом. Я просто еще с середины нулевых подсел на яндекс и именно он является моим любимым поисковиком.
Ну вот теперь в принципе я думаю, что вы в принципе знаете все основные поисковые системы на русском языке, и сделаете выводы, какая из них вам интереснее. Но правда с двумя гигантами остальным будет сложно конкурировать
Ну а на этом я пожалуй свою сегодняшнюю статью закончу. Надеюсь, что она вам пришлась по вкусу. Если это так, то обязательно заходите ко мне снова. Удачи вам. Пока!
С уважением Дмитрий Костин.
Здравствуйте, уважаемые читатели блога сайт. , то его немногочисленным пользователям было достаточно собственных закладок. Однако, как вы помните, происходил в геометрической прогрессии, и совсем скоро ориентироваться во всем ее многообразии стало сложнее.
Тогда появились каталоги (Яху, Дмоз и другие), в которых их авторы добавляли и сортировали по категориям различные сайты. Это сразу же облегчило жизнь тогдашним, еще не очень многочисленным пользователям глобальной сети. Многие из этих каталогов живы и до сих пор.
Но через некоторое время размеры их баз стали настолько большими, что разработчики сначала задумались о создании поиска внутри них, а потом уже и о создании автоматизированной системы индексации всего содержимого интернета, чтобы сделать его доступным всем желающим.
Основные поисковики русскоязычного сегмента интернета
Как вы понимаете, идея эта реализовалась с ошеломительным успехом, но, правда, все сложилось хорошо только для горстки избранных компаний, которым удалось не сгинуть на просторах интернета. Почти все поисковые системы, которые появились на первой волне, сейчас либо исчезли, либо прозябают, либо были куплены более удачными конкурентами.
Поисковая система представляет из себя очень сложный и, что немаловажно, очень ресурсоемкий механизм (имеются в виду не только материальные ресурсы, но и людские). За внешне простой , или ее аскетичным аналогом от Гугла, стоят тысячи сотрудников, сотни тысяч серверов и многие миллиарды вложений, которые необходимы для того, чтобы эта махина продолжала работать и оставалась конкурентоспособной.
Выйти на этот рынок сейчас и начать все с нуля — это скорее утопия, чем реальный бизнес проект. Например, одна из богатейших в мире корпораций Микрософт десятилетиями пыталась закрепиться на рынке поиска, и только сейчас их поисковик Бинг начинает потихоньку оправдывать их ожидания. А до этого была целая череда провалов и неудач.
Что уж говорить о том, чтобы выйти на этот рынок без особых финансовых влияний. К примеру, наша отечественная поисковая система Нигма имеет много чего полезного и инновационного в своем арсенале, но их посещаемость в тысячи раз уступает лидерам рынка России. Для примера взгляните на суточную аудиторию Яндекса:

В связи с этим можно считать, что список основных (лучших и самых удачливых) поисковиков рунета и всего интернета уже сформировался и вся интрига заключается только в том, кто кого в итоге сожрет, ну или каким образом распределится их процентная доля, если все они уцелеют и останутся на плаву.
Рынок поисковых систем России очень хорошо просматривается и тут, наверное, можно выделить двух или трех основных игроков и парочку второстепенных. Вообще, в рунете сложилась достаточно уникальная ситуация, которая повторилась, как я понимаю, только еще в двух странах в мире.
Я говорю о том, что поисковик Google, придя в Россию в 2004 году, не смог до сих пор захватить лидерства. На самом деле, они пытались примерно в этот период купить Яндекс, но что-то там не сложилось и сейчас «наша Раша» вместе с Чехией и Китаем являются теми местами, где всемогущий Гугл, если не потерпел поражение, то, во всяком случае, встретил серьезное сопротивление.
На самом деле, увидеть текущее положение дел среди лучших поисковиков рунета может любой желающий. Достаточно будет вставить этот Урл в адресную строку вашего браузера:
Http://www.liveinternet.ru/stat/ru/searches.html?period=month;total=yes
Дело в том, что большая часть использует на своих сайтах , а данный Урл позволяет увидеть статистику захода посетителей с различных поисковых систем на все сайты, которые принадлежат доменной зоне RU.
После ввода приведенного Урла вы увидите не очень приглядную и презентабельную, но зато хорошо отражающую суть дела картинку. Обратите внимание на первую пятерку поисковых систем, с которых сайты на русском языке получают трафик:

Да, конечно же, не все ресурсы с русскоязычным контентом размещаются в этой зоне. Есть еще и SU, и РФ, да и общих зонах типа COM или NET полно интернет проектов ориентированных на рунет, но все же, выборка получается довольно-таки репрезентативная.
Эту зависимость можно оформить и более красочно, как, например, сделал кто-то в сети для своей презентации:

Сути это не меняет. Есть пара лидеров и несколько сильно и очень сильно отстающих поисковых систем. Кстати, о многих из них я уже писал. Иногда бывает довольно занимательно окунуться в историю успеха или, наоборот, покопаться в причинах неудач когда-то перспективных поисковиков.
Итак, в порядке значимости для России и рунета в целом, перечислю их и дам им краткие характеристики:
Поиск в Гугле стал для многих жителей планеты уже нарицательным — о том, вы можете прочитать по ссылке. Мне в этом поисковике нравился вариант «перевод результатов», когда ответы вы получали со всего мира, но на своем родном языке, однако сейчас он, к сожалению, не доступен (во всяком случае на google.ru).

Так же в последнее время меня озадачивает и качество их выдачи (Search Engine Result Page). Лично я всегда сначала использую поисковую систему зеркала рунете (там есть , ну и привык я к ней) и только не найдя там вразумительного ответа обращаюсь к Гуглу.
Обычно их выдача меня радовала, но последнее время только озадачивает — порой такой бред вылазит. Возможно, что их борьба за повышение дохода с контекстной рекламы и постоянная перетасовка выдачи с целью дискредитировать Seo продвижение могут привести к обратному результату. Во всяком случае в рунете конкурент у этого поисковика имеется, да еще какой.
Думаю, что вряд ли кто-то специально будет заходить на Go.mail.ru для поиска в рунете. Поэтому трафик на развлекательных проектах с этой поисковой системы может быть существенно больше, чем десять процентов. Владельцам таких проектов стоит обратить внимание на эту систему.
Однако, кроме ярко выраженных лидеров на рынке поисковых систем русскоязычного сегмента интернета, существует еще несколько игроков, доля которых довольно низка, но тем не менее сам факт их существования заставляет сказать о них пару слов.
Поисковые системы рунета из второго эшелона

Поисковые системы масштаба всего интернета
По большому счету в масштабах всего интернета серьезный игрок только один — Гугл . Это безусловный лидер, однако некоторая конкуренция у него все же имеется.
Во-первых, это все тот же Бинг , который, например, на американском рынке имеет очень хорошие позиции, особенно, если учитывать, что его движок используется так же и на всех сервисах Яху (почти треть от всего рынка поиска США).

Ну, а во-вторых, в силу огромной доли, которую составляют пользователи из Китая в общем числе пользователей интернета, их главный поисковик под названием Baidu вклинивается в распределение мест на мировом олимпе. Он появился на свет в 2000 году и сейчас его доля составляет около 80% процентов от всей национальной аудитории Китая.
Трудно о Байду сказать еще что-то вразумительное, но на просторах интернета встречаются суждения, что места в его Топе занимают не только наиболее релевантные запросу сайты, но и те, кто за это заплатил (напрямую поисковику, а не Сео конторе). Конечно же, это относится в первую очередь к коммерческой выдаче.

В общем-то, глядя на статистику становится понятно, почему Google там легко идет на то, чтобы ухудшать свою выдачу в обмен на увеличение прибыли с контекстной рекламы. Фактически они не боятся оттока пользователей, ибо в большинстве случаев им уходить особо и некуда. Такая ситуация несколько печалит, но посмотрим, что будет дальше.
К слову сказать, чтобы еще больше усложнить жизнь оптимизаторам, а может быть, чтобы поддержать спокойствие пользователей этого поисковика, Google с недавних пор применяет шифрование при передаче запросов из браузера пользователей в поисковую строку. Скоро уже нельзя будет увидеть в статистике счетчиков посетителей, по каким запросам приходили к вам пользователи с Гугла.
Конечно же, кроме озвученных в этой публикации поисковых систем, существует еще не одна тысяча других — региональных, специализированных, экзотических и т.д. Пытаться их все перечислить и описать в рамках одной статьи будет не возможно, да и, наверное, не нужно. Давайте лучше скажу пару слов о том, как не легко создать поисковик и как не просто и не дешево его поддерживать в актуальном состоянии.
Подавляющее большинство систем работают по схожим принципам (читайте о том, и про ) и преследуют одну и ту же цель — дать пользователям ответ на их вопрос. Причем ответ этот должен быть релевантным (соответствующим вопросу), исчерпывающим и, что не маловажно, актуальным (первой свежести).
Решить эту задачу не так-то уж и просто, особенно учитывая, что поисковой системе нужно будет налету проанализировать содержимое миллиардов интернет страниц, отсеять лишние, а из оставшихся сформировать список (выдачу), где вначале будут идти наиболее подходящие под вопрос пользователя ответы.
Эта сверхсложная задача решается предварительным сбором информации с этих страниц с помощью различных индексирующих роботов . Они собирают ссылки с уже посещенных страниц и загружают с них информацию в базу поисковой системы. Бывают боты индексирующие текст (обычный и быстробот, который живет на новостных и часто обновляемых ресурсах, чтобы в выдаче всегда были представлены самые свежие данные).
Кроме этого бывают роботы индексаторы изображений (для последующего их вывода в ), фавиконок, зеркал сайтов (для их последующего сравнения и возможной склейки), боты проверяющие работоспособность интернет страниц, которые пользователи или же через инструменты для вебмастеров (тут можете почитать про , и ).
Сам процесс индексации и следующий за ним процесс обновления индексных баз довольно времязатратный. Хотя Гугл делает это значительно быстрее конкурентов, во всяком случае Яндекса, которому на это дело требует неделя-другая (читайте про ).
Обычно текстовое содержимое интернет страницы поисковик разбивает на отдельные слова, которые приводит к базовым основам, чтобы потом можно было давать правильные ответы на вопросы, заданные в разных морфологических формах. Весь лишний обвес в виде Html тегов, пробелов и т.п. вещей удаляется, а оставшиеся слова сортируются по алфавиту и рядом с ними указывается их позиция в данном документе.
Такая шняга называется обратным индексом и позволяет искать уже не по вебстраницам, а по структурированным данным, находящимся на серверах поисковой системы.
Число таких серверов у Яндекса (который ищет в основном только по русскоязычным сайтам и чуток по украинским и турецким) исчисляется десятками или даже сотнями тысяч, а у Google (который ищет на сотнях языков) — миллионами.
Многие сервера имеют копии, которые служат как для повышения сохранности документов, так и помогают увеличить скорость обработки запроса (за счет распределения нагрузки). Оцените расходы на поддержание всего этого хозяйства.
Запрос пользователя будет направляться балансировщиком нагрузки на тот серверный сегмент, который менее всего сейчас нагружен. Потом проводится анализ региона, откуда пользователь поисковой системы отправил свой запрос, и делается его морфологически разбор. Если аналогичный запрос недавно вводили в поисковой строке, то пользователю подсовываются данные из кеша, чтобы лишний раз не грузить сервера.
Если запрос еще не был закеширован, то его передают в область, где расположена индексная база поисковика. В ответ будет получен список всех интернет страниц, которые имеют хоть какое-то отношение к запросу. Учитываются не только прямые вхождения, но и другие морфологические формы, а так же , и т.п. вещи.
Их нужно отранжировать, и на этом этапе в дело вступает алгоритм (искусственный интеллект). Фактически запрос пользователя размножается за счет всех возможных вариантов его интерпретации и ищутся одновременно ответы на множество запросов (за счет использования операторов языка запросов, некоторые из которых доступны и обычным пользователям).
Как правило, в выдаче присутствует по одной странице от каждого сайта (иногда больше). сейчас очень сложны и учитывают множество факторов. К тому же, для их корректировки используются и , которые вручную оценивают реперные сайты, что позволяет скорректировать работу алгоритма в целом.
В общем, дело ясное, что дело темное. Говорить об этом можно долго, но и так понято, что удовлетворенность пользователей поисковой системой достигается, ох как не просто. И всегда найдутся те, кому что-то не нравится, как, например, нам с вами, уважаемые читатели.
Удачи вам! До скорых встреч на страницах блога сайт
посмотреть еще ролики можно перейдя на");">

Вам может быть интересно
Яндекс Пипл - как искать людей по социальным сетям
Апометр - бесплатный сервис по отслеживанию изменений выдачи и апдейтов поисковых систем
DuckDuckGo - поисковая система, которая не следит за тобой
 Как проверить скорость интернета - онлайн тест соединения на компьютере и телефоне, SpeedTest, Яндекс и другие измерители
Как проверить скорость интернета - онлайн тест соединения на компьютере и телефоне, SpeedTest, Яндекс и другие измерители
 Яндекс и Гугл картинки, а так же поиск по файлу изображения в Tineye (тинай) и Google
Яндекс и Гугл картинки, а так же поиск по файлу изображения в Tineye (тинай) и Google
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».

Если уж разбираться в чем-то, то основательно. И если вы подписаны на наш блог, значит наверняка хотите стать крутым специалистом или желаете знать больше о поиске в сети. Чтобы достичь желаемого - фишечек и лайфхаков недостаточно. Нужно расширять кругозор.
Поисковая система - это большая и сложная программа предназначенная для поиска информации в интернете.
Вы вообще задумывались как появилось то, чем мы пользуемся каждый день, какие в интернете существуют и почему все студии работают только с и ? Не стоит откладывать такие вопросы в долгий ящик. Всего 10 минут и вот еще одна тема для разговора, которые вы с легкостью сможете поддержать.
Как появились поисковики
Давным-давно, когда интернет был молод и зелен...
Пользователям, которых, надо сказать, было очень немного, хватало собственных закладок. Но это продолжалось недолго: вскоре человеку стало сложно ориентироваться в том многообразии, которое появилось в сети за короткий срок.
И чтобы как-то упорядочить хаос были придуманы каталоги Yahoo, DMOZ и прочие (некоторые существуют и по сей день), в которые авторы добавляли и сортировали по категориям появляющиеся сайты. На какое-то время жить стало проще.
Но интернет продолжал расширяться и вскоре размеры каталогов превратились в нечто умопомрачительно гигантское. Тогда разработчики впервые задумались о поиске внутри каталогов, а уже потом и о создании автоматизированной системы индексации всего, что находится в интернете, чтобы упростить работу всем пользователям.
Так и появились первые поисковые роботы.
Какая поисковая система была первой
Первой поисковой системой считается Wandex (ну путать с Yandex!). Этот и другие первые сервисы, конечно же, были далеки от совершенства. На поисковой запрос они выдавали совсем не то, что мы привыкли видеть сейчас, т.е. не наиболее релевантные страницы, а все подряд, игнорируя ранжирование. Первого января 2012 года Wandex был возобновлен.
Так свою работу начала первая ПС. Какие есть поисковые системы в современном интернете? Прилагаю список.
Какие бывают поисковые системы: короли танцпола
Удивительно, но есть те, кто спорят, как поисковая система лучше . Я бы этого делать не стала, просто по той причине, что они разные и вообще все зависит от цели и от того, какой вы пользователь.
Яндекс
Это самый популярный поисковик в нашей стране. LiveInternet утверждает, что Яндексом пользуются 50,9 %, в то время, как на Google приходится 40,6 % (данные от июня 2015).
Есть такой миф, мол, коммерческих запросов в Яндексе в разы больше, чем у ближайшего конкурента. Натыкалась пару раз на мысли о том, что благодаря отточенной годами региональности, тип аудитории или ее количество может различаться - в этом и заключается причина первенства Яндекса по коммерческим запросам. Так вот не верьте в это. Врут.
Поисковая система Google - самая популярная везде, кроме России:) Имеет кучу возможностей разной направленности. В общем, бесспорный мировой лидер среди поисковых роботов.
Сам Google появился примерно вместе с Яндексом, а к нам в Россию пришел лишь в 2004, когда компания Yandex укрепила свои позиции.
Процесс поиска в Google стал для многих землян уже нарицательным. Но когда я говорю своей маме “Загугли”, она все равно идет искать нужную ей информацию в Яндексе:) Она вообще не в курсе какие поисковые системы существуют в интернете.
Какие есть поисковые системы: список малоизвестных ПС
Большинство интернет-пользователей даже не в курсе, какие есть поисковые системы кроме Яндекса и Гугла. Так вот они есть;) Знакомьтесь!
Поисковую долю этого поисковика сложно назвать крупной, но показатели потихонечку растут. Хотя не стоит упускать тот факт, что цифры эти напрямую зависят от “Одноклассников”, почты Майл.ру и других штук от Mail корпорации.

Это настоящий олдскул. Только представьте: когда появилась эта поисковая система, некоторые сеошники еще только учились ходить. Вообще, у Рамблера был шанс править балом в , но этого не произошло по целому ряду причин. В настоящее время это уже не совсем поисковик, а своего рода набор сервисов, на которых в качестве поиска используется движок Yandex - например, есть свой . Посещаемость, кстати, довольно приличная: за день главную страницу Rambler посещают чуть больше миллиона пользователей.
Также у Рамблера есть версия Rambler Lite (все то же самое, только без погоды, новостей, рекламы и прочего) и XRambler , на котором объединены сразу 15 поисковых систем.

Сколько имен сменил это поисковик! За 8 лет он успел поносить имя MSN Search, затем Windows Live Search, потом сократил предыдущее название до Live Search и вот сейчас пришел к названию Bing. Многие утверждают, что качество поиска близко к заложенному стандарту Google.

Теперь сложно назвать Яху поисковой системой, так как по договору на всех площадках, принадлежащих Яху, используется поисковый движок Бинга. Последнюю новость про договор можно узнать на Searchengines .
Webalta
Наверняка этот, так называемый, поисковик вам знаком. Приходилось выковыривать его, словно клеща, из вашего браузера? Уже давно всем известно о темных делишках этого поисковика. Увы, никого эта ПС не интересует. Пользователи ищут лишь статьи о том, как удалить эту дрянь со своего компьютера.
Нигма
Это поисковая система значительно отличается от остальных. И если и индексной базой других поисковиков никого не удивишь, то вот способность решать задачи по химии и математике отличает Нигму от прочих ПС. Также Nigma предлагает поиск по музыке, книгам, играм и торрентам.

Поисковик, созданный по заказу правительства России, считается первым в мире государственным поисковиком. Предлагает отдельный медицинский поиск (поиск аптек, лекарств и статей о заболеваниях). Весьма удобная тема с “Удобной страной”, где в одном месте собраны все рекомендации, помогающие гражданину. Вот, например, раздел “Документы”.

Эта ПС значительно отличается от того, какие бывают поисковые системы в интернете . DuckDuckGo - поисковая система с открытым исходным кодом и интересной политикой, которая заключается в отказе от использования “пузыря фильтров”. Для тех, кто не знает: “пузырь фильтров” - это когда поисковик показывает в выдаче только те результаты поиска, которые она же (эта ПС) посчитает необходимыми конкретному пользователю. При этом мнение самого пользователя никого не интересует. DuckDuckGo уверяет, что использование их поисковика гарантирует то, что вы получите всю информацию, которая есть у поисковой системы.
“УткаУткаИди” набирает обороты. Уже этим летом (2015 г.) создатель ПС сообщил о трех млрд запросов в годовом выражении.
Во время написания статьи у меня возникло несколько вопросов. В таких случаях на выдачу я не полагаюсь, да, и зачем, если рядом со мной сидит человек, который знает все об интернете? Мини-интервью с Игорем Ивановым.

Игорь Иванов
Руководитель студии SEMANTICA
Если мой сайт в Google и Yandex, то будет ли мой сайт на вершине выдачи в других, менее крупных поисковиках?
Есть очень большая вероятность, что так и будет. Яндекс и Google развивают свои алгоритмы в правильном направлении и другие поисковые системы берут с них пример. Был случай, когда специалисты Google заметили, что поисковая система Bing не только копирует их алгоритмы, но результаты поиска.
Почему вероятность, а не полная уверенность? Потому, что другие поисковые системы не успеют подогнать свои алгоритмы ранжирования под эталон, которые задали их более успешные конкуренты.
Стоит ли вообще продвигаться в Спутнике, Майл и других “наших” поисковиках? Какая поисковая система лучше?
Поисковые системы (ПС) уже приличное время являются обязательной частью интернета. Сегодня они громадные и сложнейшие механизмы, которые представляют собой не только инструмент для нахождения любой необходимой информации, но и довольно увлекательные сферы для бизнеса.
Многие пользователи поиска никогда не думали о принципах их работы, о способах обработки пользовательских запросов, о том, как построены и функционируют данные системы. Данный материал поможет людям, которые занимаются оптимизацией и , понять устройство и основные функции поисковых машин.
Функции и понятие ПС
Поисковая система – это аппаратно-программный комплекс, который предназначен для осуществления функции поиска в интернете, и реагирующий на пользовательский запрос который обычно задают в виде какой-либо текстовой фразы (или точнее поискового запроса), выдачей ссылочного списка на информационные источники, осуществляющейся по релевантности. Самые распространенные и крупные системы поиска: Google, Bing, Yahoo, Baidu. В Рунете – Яндекс, Mail.Ru, Рамблер.Рассмотрим поподробнее само значение запроса для поиска, взяв для примера систему Яндекс.
Запрос обязан быть сформулирован пользователем в полном соответствии с предметом его поиска, максимально просто и кратко. К примеру, мы желаем найти информацию в данном поисковике: «как выбрать автомобиль для себя». Чтобы сделать это, открываем главную страницу и вводим запрос для поиска «как выбрать авто». Потом наши функции сводятся к тому, чтобы зайти по предоставленным ссылкам на информационные источники в сети.

Но даже действуя таким образом, можно и не получить необходимую нам информацию. Если мы получили подобный отрицательный результат, нужно просто переформировать свой запрос, или же в базе поиска действительно нет никакой полезной информации по данному виду запроса (такое вполне возможно при заданных «узких» параметров запроса, как, к примеру, «как выбрать автомобиль в Анадыри»).
Самая основная задача каждой поисковой системы – доставить людям именно тот вид информации, который им нужен. А приучить пользователей создавать «правильный» вид запросов к поисковым системам, то есть фразы, которые будут соответствовать их принципам работы, практически, невозможно.
Именно поэтому специалисты-разработчики поисковиков делают такие принципы и алгоритмы их работы, которые бы давали пользователям находить интересующие их сведения. Это означает, что система, должна «думать» так же, как мыслит человек при поиске необходимой информации в интернете.
Когда он вводит свой запрос в поисковую машину, он желает найти то, что ему надо, как можно проще и быстрее. Получив результат, пользователь составляет свою оценку работе системы, руководствуясь несколькими критериями. Получилось ли у него найти нужную информацию? Если нет, то сколько раз ему пришлось переформатировать текст запроса, чтобы найти ее? Насколько актуальная информация была им получена? Как быстро поисковая система обработала его запрос? Насколько удобно были предоставлены поисковые результаты? Был ли нужный результат первым, или находился на 30-ом месте? Сколько «мусора» (ненужной информации) было найдено вместе с полезными сведениями? Найдется ли актуальная для него информация, при использовании ПС, через неделю, либо через месяц?

Для того чтобы получить правильные ответы на подобные вопросы, разработчики поиска постоянно улучшают принципы ранжирования и его алгоритмы, добавляют им новые возможности и функции и любыми средствами пытаются сделать быстрее работу системы.
Основные характеристики поисковых систем
Обозначим главные характеристики поиска:Полнота.
Полнота является одной из главнейших характеристик поиска, она представляет собой отношение цифры найденных по запросу информационных документов к их общему числу в интернете, относящихся к данному запросу. Например, в сети есть 100 страниц имеющих словосочетание «как выбрать авто», а по такому же запросу было отобрано всего 60 из общего количества, то в данном случае полнота поиска составит 0,6. Понятно, что чем полнее сам поиск, тем больше вероятность, что пользователь найдет именно тот документ, который ему необходим, конечно, если он вообще существует.Точность.
Еще одна основная функция поисковой системы – точность. Она определяет степень соответствия запросу пользователя найденных страниц в Сети. К примеру, если по ключевой фразе «как выбрать автомобиль» найдется сотня документов, в половине из них содержится данное словосочетание, а в остальных просто есть в наличии такие слова (как грамотно выбрать автомагнитолу, и установить ее в автомобиль»), то поисковая точность равна 50/100 = 0,5.Чем поиск точнее, тем скорее пользователь найдет необходимую ему информацию, тем меньше разнообразного «мусора» будет встречаться среди результатов, тем меньше найденных документов будут не соответствовать смыслу запроса.
Актуальность.
Это значимая составляющая поиска, которую характеризует время, проходящее с момента опубликования информации в интернете до занесения ее в индексную базу поисковика.К примеру, на следующий день после возникновения информации о выходе нового iPad, множество пользователей обратилась к поиску с соответствующими видами запросов. В большинстве случаев информация об этой новости уже доступна в поиске, хотя времени с момента ее появления прошло очень мало. Это происходит благодаря наличию у крупных поисковых систем «быстрой базы», которая обновляется несколько раз за день.
Скорость поиска.
Такая функция как скорость поиска теснейшим образом связана с так называемой «устойчивостью к нагрузкам». Ежесекундно к поиску обращается огромное количество людей, подобная загруженность требует значительного сокращения времени для обработки одного запроса. Тут интересы, как поисковой системы, так и пользователя целиком совпадают: посетитель хочет получить результаты как можно быстрее, а поисковая система должна отработать его запрос тоже максимально быстро, чтобы не притормозить обработку последующих запросов.Наглядность.
Наглядное представление результатов является важнейшим элементом удобства поиска. По множеству запросов поисковая система находит тысячи, а в некоторых случаях и миллионы разных документов. Вследствие нечеткости составления ключевых фраз для поиска или его не точности, даже самые первые результаты запроса не всегда имеют только нужные сведения.Это значит, что человеку часто приходится осуществлять собственный поиск среди предоставленных результатов. Разнообразные компоненты страниц выдачи ПС помогают ориентироваться в поисковых результатах.
История развития поисковых систем
Когда интернет только начал развиваться, число его постоянных пользователей было небольшим, и объем информации для доступа был сравнительно невеликим. В основном доступ к этой сети имели лишь специалисты научно-исследовательских сфер. В то время, задача нахождения информации не была столь актуальна как сейчас.Одним из самых первых методов организации широкого доступа к ресурсам информации стало создание каталогов сайтов, причем ссылки на них начали группировать по тематике. Таким первым проектом стал ресурс Yahoo.com, который открылся весной 1994-ого года. Впоследствии когда количество сайтов в Yahoo-каталоге существенно увеличилось, была добавлена опция поиска необходимых сведений по каталогу. Это еще не было в полной мере поисковой системой, так как область такого поиска была ограничена только сайтами, входящими в данный каталог, а не абсолютно всеми ресурсами в интернете. Каталоги ссылок весьма широко использовались раньше, однако в настоящее время, практически в полной мере утратили свою популярность.
Ведь даже сегодняшние, громадные по своим объемам каталоги имеют информацию о незначительно части сайтов в интернете. Самый известный и большой каталог в мире имеет информацию о пяти миллионах сайтов, когда база Google содержит информацию о более чем 25 миллиардов страниц.

Самой первой настоящей поисковой системой стала WebCrawler, возникшая еще в 1994-ом году.
В следующем году появились AltaVista и Lycos. Причем первая была лидером по поиску информации очень длительное время.

В 1997-ом году Сергей Брин вместе с Ларри Пейджем создал машину поисковую Google как исследовательский проект в Стэндфордском университете. Сегодня именно Google, самая востребованная и популярная поисковая система в мире.

В сентябре 1997-ом году была анонсирована (официально) ПС Yandex, которая в настоящий момент является самой популярной системой поиска в Рунете.

По данным на сентябрь 2015 года , доли поисковых систем в мире распределены следующим образом:
- Google - 69,24 %;
- Bing - 12,26 %;
- Yahoo! - 9,19 %;
- Baidu - 6,48 %;
- AOL - 1,11 %;
- Ask - 0,23 %;
- Excite - 0,00 %

По данным на декабрь 2016 года , доли поисковых систем в Рунете:
- Яндекс - 48,40%
- Google - 45,10%
- Search.Mail.ru - 5,70%
- Rambler - 0,40%
- Bing - 0,30%
- Yahoo - 0,10%

Принципы работы поисковой системы
В России главной системой поиска является Яндекс, затем Google, а потом Поиск@Mail.ru. Все большие системы поиска имеют свою структуру, которая весьма отличается от других. Но все-таки можно выделить общие для всех поисковиков основные элементы.Модуль индексирования.
Данный компонент состоит из трех программ-роботов:Spider (по англ. паук) – программа которая предназначена для того чтобы скачивать веб-страницы. «Паук» скачивает определенную страницу, одновременно извлекая из нее все ссылки. Скачивается код html практически с каждой страницы. Для этого роботы используют HTTP-протоколы.

«Паук» функционирует следующим образом. Робот передает запрос на сервер “get/path/document” и иные команды запроса HTTP. В ответ программа-робот получает поток текста, который содержит информацию служебного вида и, естественно, сам документ.
- URL скаченной страницы;
- дата, когда осуществлялось скачивание страницы;
- заголовок http-ответа сервера;
- html-код, «тела» страницы.
Indexer (робот-индексатор) – это программа, анализирующая страницы, которые скачали пауки.

Индексатор полностью разбирает страницу на составные элементы и проводит их анализ, применяя свои морфологические и лексические виды алгоритмов.
Анализ проводится над разнообразными частями страницы, такими как заголовки, текст, ссылки, стилевые и структурные особенности, теги html и др.
Таким образом, модуль индексирования дает возможность проходить по ссылкам заданного количества ресурсов, скачивать страницы, извлекать ссылочную массу на новые страницы из полученных документов и делать подробный их анализ.
База данных
База данных (или индекс поисковика) - комплекс хранения данных, массив информации в котором сохраняются определенным образом переделанные параметры каждого обработанного модулем индексации и скачанного документа.Поисковый сервер
Это самый важный элемент всей системы, потому что от алгоритмов, лежащих в основе ее функциональности, прямо зависит скорость и, конечно же, качество поиска.Поисковый сервер работает следующим образом:
- Запрос, который идет от пользователя подвергается морфологическому анализу. Информационное окружение любого документа, имеющегося в базе, генерируется (оно и будет в дальнейшем отображаться как сниппет, т.е. информационное поле текста соответствующего данному запросу).
- Полученные данные передают как входные параметры специализированному модулю ранжирования. Они обрабатываются по всем документам, и в итоге для каждого такого документа рассчитывается свой рейтинг, который характеризует релевантность такого документа запросу пользователя, и иных составляющих.
- В зависимости от условий заданных пользователем этот рейтинг вполне может быть подкорректирован дополнительными.
- Затем генерируется сам сниппет, т.е. для любого найденного документа из соответствующей таблицы извлекают заголовок, аннотацию, наиболее отвечающую запросу, и ссылка на этот документ, при этом найденные словоформы и слова подсвечивают.
- Результаты полученного поиска передаются осуществившему его человеку в виде страницы, на которую выдают поисковые результаты (SERP).
Для профессионального поиска в Интернете необходимы специализированный софт, а также специализированные поисковики и поисковые сервисы.
ПРОГРАММЫ
http://dr-watson.wix.com/home – программа предназначена для исследования массивов текстовой информации с целью выявления сущностей и связей между ними. Результат работы – отчет об исследуемом объекте.
http://www.fmsasg.com/ - одна из лучших в мире программ по визуализации связей и отношений Sentinel Vizualizer . Компания полностью русифицировала свои продукты и подключил горячую линию на русском.
http://www.newprosoft.com/ – “Web Content Extractor” является наиболее мощным, простым в использовании ПО извлечения данных из web сайтов. Имеет также эффективный Visual Web паук.
SiteSputnik – не имеющий в мире аналогов программный комплекс, позволяющий вести поиск и обработку его результатов в Видимом и Невидимом Интернете, используя все необходимые пользователю поисковики.
WebSite-Watcher – позволяет проводить мониторинг веб-страниц, включая защищенные паролем, мониторинг форумов, RSS каналов, групп новостей, локальных файлов. Обладает мощной системой фильтров. Мониторинг ведется автоматически и поставляется в удобном для пользователя виде. Программа с расширенными функциями стоит 50 евро. Постоянно обновляется.
http://www.scribd.com/ – наиболее популярная в мире и все более широко применяемая в России платформа размещения различного рода документов, книг и т.п. для свободного доступа с очень удобным поисковиком по названиям, темам и т.п.
http://www.atlasti.com/ – представляет собой самый мощный и эффективный из доступных для индивидуальных пользователей, небольшого и даже среднего бизнеса инструмент качественного анализа информации. Программа многофункциональная и потому полезная. Совмещает в себе возможности создания единой информационной среды для работы с различными текстовыми, табличными, аудио и видеофайлами, как единым целым, а также инструменты качественного анализа и визуализации.
Ashampoo ClipFinder HD – все возрастающая доля информационного потока приходится на видео. Соответственно, конкурентным разведчикам нужны инструменты, позволяющие работать с этим форматом. Одним из таких продуктов является представляемая бесплатная утилита. Она позволяет осуществлять поиск роликов по заданным критериям на видеофайловых хранилищах типа YouTube. Программа проста в использовании, выводит на одну страницу все результаты поиска с подробными сведениями, названиями, длительностью, временем, когда видео было загружено в хранилище и т.п. Имеется русский интерфейс.
http://www.advego.ru/plagiatus/ – программа сделана seo оптимизаторами, но вполне подходит как инструмент интернет-разведки. Плагиатус показывает степень уникальности текста, источники текста, процент совпадения текста. Также программа проверяет уникальность указанного URL. Программа бесплатная.
http://neiron.ru/toolbar/ – включает надстройку для объединения поиска Google и Yandex, а также позволяет осуществлять конкурентный анализ, базирующийся на оценке эффективности сайтов и контекстной рекламы. Реализован как плагин для FF и GC.
http://web-data-extractor.net/ – универсальное решение для получения любых данных, доступных в интернете. Настройка вырезания данных с любой страницы производится в несколько кликов мыши. Вам нужно просто выбрать область данных, которую вы хотите сохранять и Datacol сам подберет формулу для вырезания этого блока.
CaptureSaver – профессиональный инструмент исследования интернета. Просто незаменимая рабочая программа, позволяющая захватывать, хранить и экспортировать любую интернет информацию, включая не только web страницы, блоги, но и RSS новости, электронную почту, изображения и многое другое. Обладает широчайшим функционалом, интуитивно понятным интерфейсом и смешной ценой.
http://www.orbiscope.net/en/software.html – система веб мониторинга по более чем доступным ценам.
http://www.kbcrawl.co.uk/ – программное обеспечение для работы, в том числе в «Невидимом интернете».
http://www.copernic.com/en/products/agent/index.html – программа позволяет вести поиск, используя более 90 поисковых систем, более чем по 10 параметрам. Позволяет объединять результаты, устранять дубликаты, блокировать нерабочие ссылки, показывать наиболее релевантные результаты. Поставляется в бесплатной, личной и профессиональной версиях. Используется больше чем 20 млн.пользователей.
Maltego – принципиально новое программное обеспечение, позволяющее устанавливать взаимосвязь субъектов, событий и объектов в реале и в интернете.
СЕРВИСЫ
new https://hunter.io/ – эффективный сервис для обнаружения и проверки email.
https://www.whatruns.com/ – простой в использовании, но эффективный сканер, позволяющий обнаружить, что работает и не работает на веб-сайте и каковы дыры в безопасности. Реализован также как плагин к Chrom.
https://www.crayon.co/ – американская бюджетная платформа рыночной и конкурентной разведки в интернете.
http://www.cs.cornell.edu/~bwong/octant/ – определитель хостов.
https://iplogger.ru/ – простой и удобный сервис для определения чужого IP .
http://linkurio.us/ – новый мощный продукт для работников экономической безопасности и расследователей коррупции. Обрабатывает и визуализирует огромные массивы неструктурированной информации из финансовых источников.
http://www.intelsuite.com/en – англоязычная онлайн платформа для конкурентной разведки и мониторинга.
http://yewno.com/about/ – первая действующая система перевода информации в знания и визуализации неструктурированной информации. В настоящее время поддерживает английский, французский, немецкий, испанский и португальский языки.
https://start.avalancheonline.ru/landing/?next=%2F – прогнозно-аналитические сервисы Андрея Масаловича.
https://www.outwit.com/products/hub/ – полный набор автономных программ для профессиональной работы в web 1.
https://github.com/search?q=user%3Acmlh+maltego – расширения для Maltego.
http://www.whoishostingthis.com/ – поисковик по хостингу, IP адресам и т.п.
http ://appfollow .ru / – анализ приложений на основе отзывов, ASO оптимизации, позиций в топах и поисковых выдачах для App Store , Google Play и Windows Phone Store .
http://spiraldb.com/ – сервис, реализованный как плагин к Chrom , позволяющий получить множество ценной информации о любом электронном ресурсе.
https://millie.northernlight.com/dashboard.php?id=93 - бесплатный сервис, собирающий и структурирующий ключевую информацию по отраслям и компаниям. Есть возможность использования информационных панелей основанных на текстовом анализе.
http://byratino.info/ – сбор фактографических данных из общедоступных источников в сети Интернет.
http://www.datafox.co/ – CI платформа собирающая и анализирующая информацию по интересующим клиентов компаниям. Есть демо.
https://unwiredlabs.com/home - специализированное приложение с API для поиска по геолокации любого устройства, подключенного к интернету.
http://visualping.io/ – сервис мониторинга сайтов и в первую очередь имеющихся на них фотографий и изображений. Даже если фотография появилась на секунду, она будет в электронной почте подписчика. Имеет плагин для G oogleC hrome.
http://spyonweb.com/ – исследовательский инструмент, позволяющий осуществить глубокий анализ любого интернет-ресурса.
http://bigvisor.ru/ – сервис позволяет отслеживать рекламные компании по определенным сегментам товаров и услуг, либо конкретным организациям.
http://www.itsec.pro/2013/09/microsoft-word.html – инструкция Артема Агеева по использованию программ Windows для нужд конкурентной разведки.
http://granoproject.org/ – инструмент с открытым исходным кодом для исследователей, которые отслеживают сети связей между персонами и организациями в политике, экономике, криминале и т.п. Позволяет соединять, анализировать и визуализировать сведения, полученные из различных источников, а также показывать существенные связи.
http://imgops.com/ – сервис извлечения метаданных из графических файлов и работы с ними.
http://sergeybelove.ru/tools/one-button-scan/ – маленький он-лайн сканер для проверки дыр безопасности сайтов и других ресурсов.
http://isce-library.net/epi.aspx – сервис поиска первоисточников по фрагменту текста на английском языке
https://www.rivaliq.com/ – эффективный инструмент для ведения конкурентной разведки на западных, в первую очередь, европейских и американских рынках товаров и услуг.
http://watchthatpage.com/ – сервис, который позволяет автоматически собирать новую информацию с поставленных на мониторинг ресурсов в интернете. Услуги сервиса бесплатные.
http://falcon.io/ – своего рода Rapportive для Web. Он не является заменой Rapportive, а дает дополнительные инструменты. В отличие от Rapportive дает общий профиль человека, как бы склеенный из данных из социальных сетей и упоминаний в web.http://watchthatpage.com/ – сервис, который позволяет автоматически собирать новую информацию с поставленных на мониторинг ресурсов в интернете. Услуги сервиса бесплатные.
https://addons.mozilla.org/ru/firefox/addon/update-scanner/ – дополнение для Firefox. Следит за обновлениями web-страниц. Полезно для web-сайтов, которые не имеют лент новостей (Atom или RSS).
http://agregator.pro/ – агрегатор новостных и медийных порталов. Используется маркетологами, аналитиками и т.п. для анализа новостных потоков по тем или иным темам.
http://price.apishops.com/ – автоматизированный веб-сервис мониторинга цен по выбранным товарным группам, конкретным интернет-магазинам и другим параметрам.
http://www.la0.ru/ – удобный и релевантный сервис анализа ссылок и бэклинков на интернет-ресурс.
www.recordedfuture.com – мощный инструмент анализа данных и их визуализации, реализованный как он-лайн сервис, построенный на «облачных» вычислениях.
http://advse.ru/ – сервис под слоганом «Узнай все про своих конкурентов». Позволяет в соответствии с поисковыми запросами получить сайты конкурентов, анализировать рекламные компании конкурентов в Google и Yandex.
http://spyonweb.com/ – сервис позволяет определить сайты с одинаковыми характеристиками, в том числе, использующими одинаковые идентификаторы сервиса статистики Google Analytics, IP адреса и т.п.
http://www.connotate.com/solutions – линейка продуктов для конкурентной разведки, управления информационными потоками и преобразования сведений в информационные активы. Включает как сложные платформы, так и простые дешевые сервисы, позволяющие эффективно вести мониторинг вместе с компрессией информации и получением только нужных результатов.
http://www.clearci.com/ – платформа конкурентной разведки для бизнеса различных размеров от стартапов и маленьких компаний до компаний из списка Fortune 500. Решена как saas.
http://startingpage.com/ – надстройка на Google, позволяющая вести поиск в Google без фиксации вашего IP адреса. Полностью поддерживает все поисковые возможности Google, в том числе и а русском языке.
http://newspapermap.com/ – уникальный сервис, очень полезный для конкурентного разведчика. Соединяет геолокацию с поисковиком он-лайн медиа. Т.е. вы выбираете интересующий вас регион или даже город, или язык, на карте видите место и список он-лайн версий газет и журналов, нажимаете на соответствующую кнопку и читаете. Поддерживает русский язык, очень удобный интерфейс.
http://infostream.com.ua/ – очень удобная отличающаяся первоклассной выборкой, вполне доступная для любого кошелька система мониторинга новостей «Инфострим» от одного из классиков интернет-поиска Д.В.Ландэ.
http://www.instapaper.com/ – очень простой и эффективный инструмент для сохранения необходимых веб-страниц. Может использоваться на компьютерах, айфонах, айпадах и др.
http://screen-scraper.com/ – позволяет автоматически извлекать всю информацию с веб-страниц, скачивать подавляющее большинство форматов файлов, автоматически вводить данные в различные формы. Скачанные файлы и страницы сохраняет в базах данных, выполняет множество других чрезвычайно полезных функций. Работает под всеми основными платформами, имеет полнофункциональную бесплатную и очень мощные профессиональные версии.
http://www.mozenda.com/- имеющий несколько тарифных планов и доступный даже для малого бизнеса веб сервис многофункционального веб мониторинга и доставки с избранных сайтов необходимой пользователю информации.
http://www.recipdonor.com/ - сервис позволяет осуществлять автоматический мониторинг всего происходящего на сайтах конкурентов.
http://www.spyfu.com/ – а это, если у вас конкуренты иностранные.
www.webground.su – созданный профессионалами Интернет-поиска сервис для мониторинга Рунета, включающий всех основных поставщиков информации, новостей и т.п., способен к индивидуальным настройкам мониторинга под нужды пользователя.
ПОИСКОВИКИ
https ://www .idmarch .org / – лучший по качеству выдачи поисковик мирового архива pdf документов. В настоящее время проиндексировано более 18 млн. pdf документов, начиная от книг, заканчивая секретными отчетами.
http://www.marketvisual.com/ – уникальный поисковик, позволяющий вести поиск собственников и топ-менеджмента по ФИО, наименованию компании, занимаемой позиции или их комбинации. В поисковой выдаче содержатся не только искомые объекты, но и их связи. Рассчитана прежде всего на англоязычные страны.
http://worldc.am/ – поисковик по фотографиям в свободном доступе с привязкой к геолокации.
https://app.echosec.net/ – общедоступный поисковик, который характеризует себя как самый продвинутый аналитический инструмент для правоохранительных органов и профессионалов безопасности и разведки. Позволяет вести поиск фотографий, размещенных на различных сайтах, социальных платформах и в социальных сетях в привязке к конкретным геолокационным координатам. В настоящее время подключено семь источников данных. До конца года их число составит более 450. За наводку спасибо Дементию.
http://www.quandl.com/ – поисковик по семи миллионам финансовых, экономических и социальных баз данных.
http://bitzakaz.ru/ – поисковик по тендерам и госзаказам с дополнительными платными функциями
Website-Finder – дает возможность найти сайты, которые плохо индексирует Google. Единственным ограничением является то, что для каждого ключевого слова он ищет только 30 веб-сайтов. Программа проста в использовании.
http://www.dtsearch.com/ – мощнейший поисковик, позволяющий обрабатывать терабайты текста. Работает на рабочем столе, в интернете и в интранете. Поддерживает как статические, так и динамические данные. Позволяет искать во всех программах MS Office. Поиск ведется по фразам, словам, тегам, индексам и многому другому. Единственная доступная система федеративного поиска. Имеет как платную, так и бесплатную версии.
http://www.strategator.com/ – осуществляет поиск, фильтрацию и агрегацию информации о компании из десятка тысяч веб-источников. Ищет по США, Великобритании, основным странам ЕЭС. Отличается высокой релевантностью, удобностью для пользователя, имеет бесплатные и платный вариант (14$ в месяц).
http://www.shodanhq.com/ – необычный поисковик. Сразу после появления получил кличку «Гугл для хакеров». Ищет не страницы, а определяет IP адреса, типы роутеров, компьютеров, серверов и рабочих станций, размещенных по тому или иному адресу, прослеживает цепочки DNS серверов и позволяет реализовать много других интересных функций для конкурентной разведки.
http://search.usa.gov/ – поисковик по сайтам и открытым базам всех государственных учреждений США. В базах находится много практической полезной информации, в том числе и для использования в нашей стране.
http://visual.ly/ – сегодня все шире для представления данных используется визуализация. Это первый поисковик инфографики в Вебе. Одновременно с поисковиком на портале есть мощные инструменты визуализации данных, не требующие навыков программирования.
http://go.mail.ru/realtime –поиск по обсуждениям тем, событий, объектов, субъектов в режиме реального, либо настраиваемого времени. Ранее крайне критикуемый поиск в Mail.ru работает очень эффективно и дает интересную релевантную выдачу.
Zanran – только что стартовавший, но уже отлично работающий первый и единственный поисковик для данных, извлекающий их из файлов PDF, таблиц EXCEL, данных на страницах HTML.
http://www.ciradar.com/Competitive-Analysis.aspx – одна из лучших в мире систем поиска информации для конкурентной разведки в «глубоком вебе». Извлекает практически все виды файлов во всех форматах по интересующей теме. Реализована как веб-сервис. Цены более чем приемлемые.
http://public.ru/ – Эффективный поиск и профессиональный анализ информации, архив СМИ с 1990 года. Интернет-библиотека СМИ предлагает широкий спектр информационных услуг: от доступа к электронным архивам публикаций русскоязычных СМИ и готовых тематических обзоров прессы до индивидуального мониторинга и эксклюзивных аналитических исследований, выполненных по материалам печати.
Cluuz – молодой поисковик с широкими возможностями для конкурентной разведки, особенно, в англоязычном интернете. Позволяет не только находить, но и визуализировать, устанавливать связи между людьми, компаниями, доменами, e-mail, адресами и т.п.
www.wolframalpha.com – поисковик завтрашнего дня. На поисковый запрос выдает имеющуюся по объекту запроса статистическую и фактологическую информацию, в том числе, визуализированную.
www.ist-budget.ru – универсальный поиск по базам данных госзакупок, торгов, аукционов и т.п.