Работа с различными поисковыми системами. SEO-дебри, или Как работают поисковые системы? Поисковая система, что это такое
Многие хотят оказаться в ТОПе, но далеко не все понимают, как работают поисковые системы. А к рубежу 2017 года требования к сайтам со стороны поисковых систем ещё более ужесточились (более подробнее в статье ). Поэтому, чтобы постоянно быть в топе, для начала нужно, как минимум разобраться как работают поисковые алгоритмы.
Дочитав эту статью до конца, Вы разберётесь в том, на каких принципах строится работа Яндекс и Google, узнаете чуть больше о mail, rambler и bing. При этом мы не будем касаться факторов ранжирования сайтов, т.к. это очень объёмный материал, требующий отдельной публикации.
Ну, или если хотите цель, назначение или даже миссия поисковой системы это дать максимально точный ответ пользователю на его запрос в виде перечня ссылок на различные ресурсы.
Для того чтобы сформировать качественный список из сайтов, поисковая система создаёт базу данных. То есть, если Ваш сайт или новая страница сайта не проиндексирован Яндексом или Гуглом, значит их не будет в результатах поиска. Базу данных из сайтов формируют поисковые роботы, которые сообщаются информацию о сайтах своему «боссу» , а тот заносит данные в реестр. Например, если вы зарегистрировали свой сайт в или , там можно найти информацию о том, какое количество страниц Вашего сайта проиндексировала поисковая система.
Далее, весь реестр данных из страниц многочисленных сайтов ранжируется по определённым параметрам: регион, релевантность запросу, популярность ресурса, качества контента и так далее. Как я уже и сказал, весь список факторов ранжирования мы разберём в отдельной публикации. Основной задачей при продвижения сайта, становится как раз влияние на эти факторы, с целью поднятия сайта в ТОП.
Особенности и характеристики поисковых систем в 2018
Все мы видели рекламу Google о том, как поисковая система вступает в неравную схватку с бабушкой на предмет поиска ближайшей аптеки. О чём это говорит? О том, что поисковые системы обучаются и в скором времени полностью перестанут работать с ключевыми словами и будут работать только со смыслами. Т.к. это и является их основной задачей не выдать произвольный список сайтов, а помочь пользователю в поиске места, товара или услуги.
В нашей стране доля голосового поиска ещё очень незначительно, но в США она занимает около 50% мобильного трафика. А значит эта тенденция скоро коснётся России. Соответственно, вырастет количество информационных запросов (как, где, куда ) и запросов, которые невозможно предсказать, т.к. они будут не шаблонными и продиктованы ситуацией, в которой находится человек. Например, он стоит на перекрёстке и запрашивает, куда мне повернуть, чтобы найти кафе, где есть бизнес-лачни стоимостью до 300 рублей. Это Google.
Что касается Яндекса, который так же в конце 2016 представили . Это алгоритм, который так же будет работать прежде всего со смыслами.
Какая поисковая система лучше или чем отличается Яндекс от Google?
На своём личном опыте могу сказать, что обе поисковые системы хорошие по-своему. Отличие разумеется в том, что Яндекс — это российский поисковик, а Google это крупнейшая в мире поисковая система. Разумеется нас не интересует внешнее отличие сайтов этих поисковых систем и сервисов, которые они предоставляют, а то, как они формируют результаты поисковой выдачи, так как они очень сильно разнятся.
В Яндексе в большей степени уделено внимание региональному поиску. То есть, если Вы находитесь во Владивостоке и вводите запрос без указания города или региона, например «окна», в первую очередь Яндекс покажет сайты тех компаний, который находятся во Владивостоке и каким-то образом связаны с окнами.
Для Google в большей степени важно популярность, цитируемость ресурса (не только ссылки на Ваш сайт), на основе этого он делает вывод, является ли Ваш сайт полезным.
Что касается других поисковых систем, то mail.ru является оболочкой поисковой выдачи Гугла, т.е. сам mail.ru ничего не анализирует, а просто показывает то, что показал бы Гугл. Rambler.ru по тому же принципу является оболочкой Яндекса.
По определению, интернет-поисковик это система поиска информации, которая помогает нам найти информацию во всемирной паутине. Это облегчает глобальный обмен информацией. Но интернет является неструктурированной базой данных. Он растет в геометрической прогрессии, и стал огромным хранилищем информации. Поиск информации в интернете, является трудной задачей. Существует необходимость иметь инструмент для управления, фильтра и извлечения этой океанической информации. Поисковая система служит для этой цели.
Как работает поисковая система?
Поисковые системы интернета являются двигателями, поиска и извлечения информации в интернете. Большинство из них используют гусеничную архитектуру индексатора. Они зависят от их гусеничных модулей. Сканеры также называют пауками это небольшие программы, которые просматривают веб-страницы.
Сканеры посещают первоначальный набор URL-адресов. Они добывают URL-адреса, которые появляются на просканированных страницах и отправляют эту информацию в модуль гусеничный управления. Гусеничный модуль решает, какие страницы посетить в следующий раз и дает эти URL-адреса сканерам.
Темы, охватываемые различными поисковыми системами, варьируются в зависимости от алгоритмов, которые они используют. Некоторые поисковые системы запрограммированы на поисковые сайты по конкретной теме, в то время как сканеры других могут посещать столько мест, сколько возможно.
Модуль индексации извлекает информацию из каждой страницы, которую он посещает и вносит URL в базу. Это приводит к образованию огромной таблицы поиска, из списка URL-адресов указывающих на страницы с информацией. В таблице приведены те страницы, которые были покрыты в процессе обхода.
Модуль анализа является еще одной важной частью архитектуры поисковой системы. Он создает индекс полезности. Индекс утилита может предоставить доступ к страницам заданной длины или страниц, содержащих определенное количество картинок на них.
В процессе сканирования и индексирования, поисковик сохраняет страницы, которые он извлекает. Они временно хранятся в хранилище страницы. Поисковые системы поддерживают кэш страниц которые они посещают, чтобы ускорить извлечение уже посещенных страниц.
Модуль запроса поисковой системы получает поисковый запросов от пользователей в виде ключевых слов. Модуль ранжирования сортирует результаты.
Архитектура гусеничного индексатора имеет много вариантов. Они изменяются в распределенной архитектуре поисковой системы. Эти архитектуры состоят из собирателей и брокеров. Собиратели собирают информацию индексации с веб-серверов в то время как брокеры дают механизм индексирования и интерфейс запросов. Брокеры индексируют обновление на основе информации, полученной от собирателей и других брокеров. Они могут фильтровать информацию. Многие поисковые системы сегодня используют этот тип архитектуры.
Поисковые системы и ранжирования страниц
Когда мы создаем запрос в поисковой системе, результаты отображаются в определенном порядке. Большинство из нас, как правило, посещают страницы верхнего порядка и игнорируют последние. Это потому, что мы считаем, что верхние несколько страниц несут большую актуальность для нашего запроса. Так что все заинтересованы в рейтинге своих страниц в первых десяти результатов в поисковой системе.
Слова, указанные в интерфейсе запроса поисковой системы являются ключевыми словами, которые запрашивались в поисковых системах. Они представляют собой список страниц, имеющих отношение к запрашиваемым ключевым словам. Во время этого процесса, поисковые системы извлекают те страницы, которые имеют частые вхождений этих ключевых слов. Они ищут взаимосвязи между ключевыми словами. Расположение ключевых слов также считается, как и рейтинг страницы, содержащие их. Ключевые слова, которые встречаются в заголовках страниц или в URL, приведены в больший вес. Страницы, имеющие ссылки, указывающие на них, делают их еще более популярными. Если многие другие сайты, ссылаются на какую либо страницу, она рассматривается как ценная и более актуальная.
Существует алгоритм ранжирования, который использует каждая поисковая система. Алгоритм представляет собой компьютеризированную формулу разработанную, чтобы предоставлять соответствующие страницы по запросу пользователя. Каждая поисковая система может иметь различный алгоритм ранжирования, который анализирует страницы в базе данных двигателя, чтобы определить соответствующие ответы на поисковые запросы. Различные сведения поисковые системы индексируют по-разному. Это приводит к тому, что конкретный запрос, поставленный двум различным поисковым машинам, может принести страницы в различных порядках или извлечь разные страницы. Популярность веб-сайта являются факторами, определяющими актуальность. Клик-через популярность сайта является еще одним фактором, определяющим его ранг. Это мера того, насколько часто посещают сайт.
Веб-мастера пытаются обмануть алгоритмы поисковой системы, чтобы поднять позиции своего сайта в поисковой выдаче. Заполняют страницы сайта ключевыми словами или используют мета теги, чтобы обмануть стратегии рейтинга поисковой системы. Но поисковые системы достаточно умны! Они совершенствуют свои алгоритмы так, чтобы махинации веб-мастеров не влияли на поисковую выдачу.
Нужно понимать, что даже страницы после первых нескольких в списке могут содержать именно ту информацию, которую вы искали. Но будьте уверены, что хорошие поисковые системы всегда принесут вам высоко релевантные страницы в верхнем порядке!
Для того чтобы осуществить продвижение сайта, необходимо понимать как работают поисковые системы и что нужно делать, чтобы попасть в позиции поиска по ключевым словам.
Что такое поисковые системы, и какие их задачи
Поисковые системы представляют собой компьютерных роботов, предоставляющих посетителям самую актуальную и наиболее полезную информацию по их запросам.
Чем более правильный ответ дает поисковик, тем более высокий уровень доверия к нему возникает у пользователей сети Интернет.
Это важно для самой системы из-за того, что она из этого получает выгоду в виде прибыли за размещения , которую видят все, кто ею пользуются.
Для того чтобы предоставить правильные ответы, тем самым увеличив количество , поисковики работают по определенному принципу, заключающемуся в сборе данных о постоянно появляющихся сайтах и индексации их страниц.
Принцип работы поисковиков
 Многие пользователи сети Интернет считают, что поисковые системы выдают им информацию обо всех сайтах, которые существуют. Но на самом деле это совершенно не так, ведь они ориентируются только на те страницы, которые находятся в базе данных машины поиска. Если сайта в поисковых систем нет, то ни Google, ни Яндекс не выдадут его в поиске.
Многие пользователи сети Интернет считают, что поисковые системы выдают им информацию обо всех сайтах, которые существуют. Но на самом деле это совершенно не так, ведь они ориентируются только на те страницы, которые находятся в базе данных машины поиска. Если сайта в поисковых систем нет, то ни Google, ни Яндекс не выдадут его в поиске.
Когда сайта появляется базе данных, роботы поисковика сканируют его, выявляя все внутренние страницы, а также ссылки, размещенные на данном Интернет-портале. Таким образом, происходит сбор полной информации, как о конкретном сайте, так и других ресурсах, которые он популяризует.
Происходить процесс поимки и систематизации информации посредством . В некоторых случаях это не происходит достаточно долгое время, поэтому необходимо понимать, что это за функция поисковой системы и каким образом она работает.
Какая роль правильного оформления текста на сайте, читайте в нашей .
Итоги
Для того чтобы раскрутить сайт, необходимо учитывать все аспекты работы популярных поисковиков, подстраивая показатели своего Интернет-ресурса под требования данных систем. Если все будет сделано в соответствии с правилами, установленными Google и Яндекс, в скором времени можно будет увидеть свой сайт на первых позициях поиск по ключевым словам.
С уважением, Настя ЧеховаПоисковая система - это программно-аппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу). Наиболее крупные международные поисковые системы: «Google» , «Yahoo» , «MSN» . В русском Интернете это – «Яндекс» , «Рамблер» , «Апорт» .
Опишем основные характеристики поисковых систем:
Полнота
Полнота - одна из основных характеристик поисковой системы, представляющая собой отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу. К примеру, если в Интернете имеется 100 страниц, содержащих словосочетание «как выбрать автомобиль», а по соответствующему запросу было найдено всего 60 из них, то полнота поиска будет 0,6. Очевидно, что чем полнее поиск, тем меньше вероятность того, что пользователь не найдет нужный ему документ, при условии, что он вообще существует в Интернете.
Точность
Точность - еще одна основная характеристика поисковой машины, которая определяется степенью соответствия найденных документов запросу пользователя. Например, если по запросу «как выбрать автомобиль» находится 100 документов, в 50 из них содержится словосочетание «как выбрать автомобиль», а в остальных просто наличествуют эти слова («как правильно выбрать магнитолу и установить в автомобиль»), то точность поиска считается равной 50/100 (=0,5). Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу.
Актуальность
Актуальность - не менее важная составляющая поиска, которая характеризуется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу поисковой системы. Например, на следующий день после появления интересной новости, большое количество пользователей обратились к поисковым системам с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток, однако основные документы уже были проиндексированы и доступны для поиска, благодаря существованию у крупных поисковых систем так называемой «быстрой базы», которая обновляется несколько раз в день.
Скорость поиска
Скорость поиска тесно связана с его устойчивостью к нагрузкам. Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов.
Наглядность
Наглядность представления результатов является важным компонентом удобного поиска. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости составления запросов или неточности поиска, даже первые страницы выдачи не всегда содержат только нужную информацию. Это означает, что пользователю зачастую приходится производить свой собственный поиск внутри найденного списка. Различные элементы страницы выдачи поисковой системы помогают ориентироваться в результатах поиска.одробные пояснения по странице результатов поиска, например у «Яндекса» можно посмотреть по ссылке http://help.yandex.ru/search/?id=481937 .
4. Краткая история развития поисковых систем
В начальный период развития Интернет, число его пользователей было невелико, а объем доступной информации сравнительно небольшим. В большинстве своем, доступ к сети Интернет имели лишь сотрудники научно-исследовательской сферы. В это время задача поиска информации в Интернете не была столь актуальной, как в настоящее время.
Одним из первых способов организации доступа к информационным ресурсам сети стало создание открытых каталогов сайтов, ссылки на ресурсы в которых группировались согласно тематике. Первым таким проектом стал сайт Yahoo.com, открывшийся весной 1994 года. После того, как количество сайтов в каталоге Yahoo значительно увеличилось, была добавлена возможность поиска нужной информации по каталогу. В полном смысле это еще не было поисковой системой, так как поисковая область была ограничена только ресурсами, присутствующими в каталоге, а не всеми Интернет ресурсами.
Каталоги ссылок широко использовались ранее, однако практически полностью утратили свою популярность в настоящее время. Так как даже современные, огромные по своему объему каталоги, содержат информацию лишь о ничтожно малой части сети Интернет. Самый большой каталог сети DMOZ (его еще называют Open Directory Project) содержит информацию о 5 миллионах ресурсов, тогда как база поисковой системы Google состоит из более чем 8 миллиардов документов.
Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
В 1995 году появились поисковые системы Lycos и AltaVista. Последняя долгие годы была лидером в области поиска информации в сети Интернет.
В 1997 году Сергей Брин и Ларри Пейдж создали поисковую машину Google в рамках исследовательского проекта в Стэндфордском университете. В настоящий момент Google - самая популярная поисковая система в мире!
В сентябре 1997 года была официально анонсирована поисковая система Yandex, являющаяся самой популярной в русскоязычном Интернете.
В настоящее время существуют три основные международные поисковые системы – Google, Yahoo и MSN, имеющих собственные базы и алгоритмы поиска. Большинство остальных поисковых систем (коих насчитывается большое количество) использует в том или ином виде результаты трех перечисленных. Например, поиск AOL (search.aol.com) использует базу Google, а AltaVista, Lycos и AllTheWeb – базу Yahoo.
5. Состав и принципы работы поисковой системы
В России основной поисковой системой является «Яндекс», далее - Rambler.ru, Google.ru, Aport.ru, Mail.ru. Причем, на данный момент, Mail.ru использует механизм и базу поиска «Яндекса».
Практически все крупные поисковые системы имеют свою собственную структуру, отличную от других. Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Модуль индексирования
Модуль индексирования состоит из трех вспомогательных программ (роботов):
Spider (паук) – программа, предназначенная для скачивания веб-страниц. «Паук» обеспечивает скачивание страницы и извлекает все внутренние ссылки с этой страницы. Скачивается html-код каждой страницы. Для скачивания страниц роботы используют протоколы HTTP. Работает «паук» следующим образом. Робот на сервер передает запрос “get/path/document” и некоторые другие команды HTTP-запроса. В ответ робот получает текстовый поток, содержащий служебную информацию и непосредственно сам документ.
URL страницы
дата, когда страница была скачана
http-заголовок ответа сервера
тело страницы (html-код)
Crawler («путешествующий» паук) – программа, которая автоматически проходит по всем ссылкам, найденным на странице. Выделяет все ссылки, присутствующие на странице. Его задача - определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Indexer (робот- индексатор) - программа, которая анализирует веб-страницы, скаченные пауками. Индексатор разбирает страницу на составные части и анализирует их, применяя собственные лексические и морфологические алгоритмы. Анализу подвергаются различные элементы страницы, такие как текст, заголовки, ссылки структурные и стилевые особенности, специальные служебные html-теги и т.д.
Таким образом, модуль индексирования позволяет обходить по ссылкам заданное множество ресурсов, скачивать встречающиеся страницы, извлекать ссылки на новые страницы из получаемых документов и производить полный анализ этих документов.
База данных
База данных, или индекс поисковой системы - это система хранения данных, информационный массив, в котором хранятся специальным образом преобразованные параметры всех скачанных и обработанных модулем индексирования документов.
Поисковый сервер
Поисковый сервер является важнейшим элементом всей системы, так как от алгоритмов, которые лежат в основе ее функционирования, напрямую зависит качество и скорость поиска.
Поисковый сервер работает следующим образом:
Полученный от пользователя запрос подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе (которое и будет впоследствии отображено в виде сниппета, то есть соответствующей запросу текстовой информации на странице выдачи результатов поиска).
Полученные данные передаются в качестве входных параметров специальному модулю ранжирования. Происходит обработка данных по всем документам, в результате чего, для каждого документа рассчитывается собственный рейтинг, характеризующий релевантность запроса, введенного пользователем, и различных составляющих этого документа, хранящихся в индексе поисковой системы.
В зависимости от выбора пользователя этот рейтинг может быть скорректирован дополнительными условиями (например, так называемый «расширенный поиск»).
Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются.
Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов.
Как видно, все эти компоненты тесно связаны друг с другом и работают во взаимодействии, образовывая четкий, достаточно сложный механизм работы поисковой системы, требующий огромных затрат ресурсов.
Ни одна поисковая система не охватывает все ресурсы Интернет.
Каждая поисковая система собирает сведения о ресурсах Интернет, применяя свои уникальные методы, и формирует собственную периодически обновляемую базу данных. Доступ к этой базе предоставляется пользователю.
Поисковые системы реализуют два способа поиска ресурса:
Поиск по тематическим каталогам - информация представляется в виде иерархической структуры. На верхнем уровне - общие категории (“Интернет”, “Бизнес”, “Искусство”, “Образование” и т.д.), на следующем уровне категории делятся на разделы и т.д. Самый нижний уровень - ссылки на конкретные веб-страницы или другие информационные ресурсы.
Поиск по ключевым словам (индексный поиск или детальный) - пользователь отправляет поисковой системе запрос , состоящий из ключевых слов. Система возвращает пользователю перечень найденных по запросу ресурсов.
Большинство поисковых систем сочетают оба способа поиска.
Поисковые системы могут быть локальными, глобальными, региональными и специализированными.
В русской части Интернет (Рунет) наиболее популярны сейчас поисковые системы общего назначения Rambler (www.rambler.ru), Яндекс (www.yandex.ru), Апорт (www.aport.ru), Гугл (www.google.ru).
Большинство поисковых систем реализовано в виде порталов.
Портал (от англ. portal - главный вход, ворота) -это веб-сайт, который интегрирует различные сервисы Интернет: средства поиска, почту, новости, словари и т.д.
Порталы могут быть специализированными (как, www . museum . ru ) и общими (например, www . km . ru ).
Поиск по ключевым словам
Набор ключевых слов, по которым ведется поиск, называют также критерием поиска или темой поиска.
Запрос может состоять как из одного слова, так и из сочетания слов, объединенных операторами - символами, по которым система определяет, какое действие ей нужно произвести. Например: запрос “Москва Питер” содержит оператор И (так воспринимается пробел), который указывает, что надо искать документы, в которых есть оба слова - и Москва, и Питер.
Для того, чтобы поиск был релевантным (от англ. relevant -уместный, относящийся к делу), следует учитывать несколько общих правил:
Независимо от того, в какой форме употреблено слово в запросе, поиск учитывает все его словоформы по правилам русского языка. Например, по запросу “билет” будут найдены и слова “билетом”, “билету” и т.д.
Заглавные буквы следует использовать только в именах собственных, чтобы не просматривать лишние ссылки. По запросу “кузнецов”, например, будут найдены документы, где говорится и о кузнецах, и о Кузнецовых.
Желательно сужать круг поиска, используя несколько ключевых слов.
Если нужного адреса нет среди первой двадцатки найденных адресов, следует изменить запрос.
Каждая поисковая система использует свой язык запросов. Для знакомства с ним, пользуйтесь встроенной справкой поисковой системы
Крупные сайты могут иметь встроенные системы поиска информации в пределах своих веб-страниц.
Запросы в подобных системах поиска, как правило, строятся по тем же правилам, что и в глобальных поисковых системах, однако знакомство со справкой и здесь не будет лишним.
Расширенный поиск
Поисковые системы могут предоставлять в распоряжение пользователя механизм, позволяющий формировать сложный запрос. Переход по ссылке Расширенный поиск дает возможность редактировать параметры поиска, указывать дополнительные параметры и выбирать наиболее удобную форму показа результатов поиска. Ниже описаны параметры, которые могут быть заданы при расширенном поиске в системах Япс1ех и Rambler.
Описание параметра
Название в Яндекс
Название в Rambler
Где искать ключевые слова (заголовок документа, основной текст и т.д.)
Словарный фильтр
Поиск по тексту...
Какие слова должны или не должны присутствовать в документе и насколько точным должно быть совпадение
Словарный фильтр
Искать слова запроса... Исключить документы, содержащие следующие слова...
На каком расстоянии друг от друга должны располагаться ключевые слова
Словарный фильтр
Расстояние между словами запроса...
Ограничение на дату документа
Дата документа...
Ограничение поиска пределами одного или нескольких сайтов
Сайт/Вершина
Искать документы только на следующих сайтах...
Ограничение поиска по языку документа
Язык документа...
Поиск документов, содержащих картинку с определенным именем или подписью
Изображение
Поиск страниц, содержащих объекты
Специальные объекты
Форма представления результатов поиска
Формат выдачи
Вывод результатов поиска
Некоторые поисковые системы (например, Яндекс) позволяют вводить запросы на естественном языке. Вы пишите, что нужно найти (например: заказ билетов на поезд из Москвы в Питер). Система анализирует запрос и выдает результат. Если он Вас не устраивает, переходите на язык запросов.
Зачем маркетологу знать базовые принципы поисковой оптимизации? Все просто: органический трафик — это прекрасный источник входящего потока целевой аудитории для вашего корпоративного сайта и даже лендингов.
Встречайте серию образовательных постов на тему SEO.
Что такое поисковая система?
Поисковая система представляет собой большую базу документов (контента). Поисковые роботы обходят ресурсы и индексируют разный тип контента, именно эти сохраненные документы и ранжируют в поиске.
По факту, Яндекс — это «слепок» Рунета (еще Турция и немного англоязычных сайтов), а Google — мирового интернета.
Поисковый индекс — структура данных, содержащая информацию о документах и расположении в них ключевых слов.
По принципу работы поисковые системы схожи между собой, различия заключаются в формулах ранжирования (упорядочивание сайтов в поисковой выдаче), которые строятся на основе машинного обучения.
Ежедневно миллионы пользователей задают запросы поисковым системам.
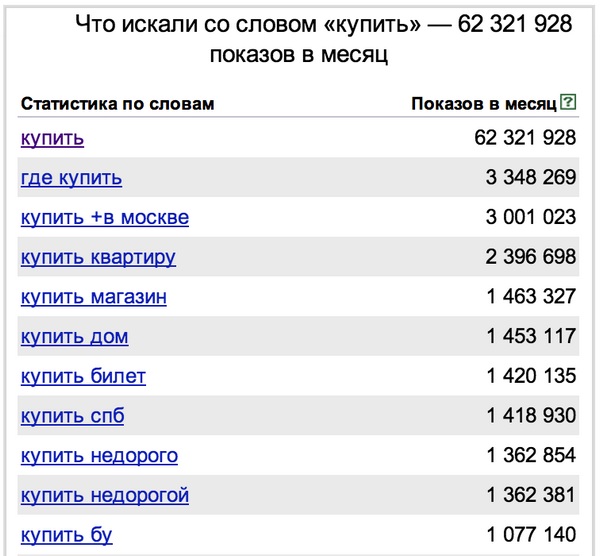
«Реферат написать»:
«Купить»:
Но больше всего интересуются…
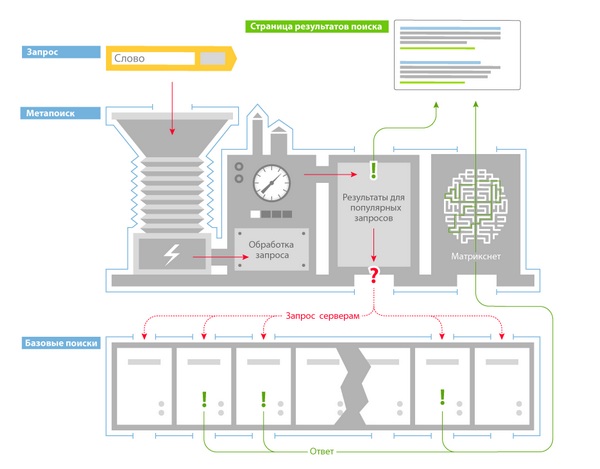
Как устроена поисковая система?
Чтобы предоставлять пользователям быстрые ответы, архитектуру поиска разделили на 2 части:
- базовый поиск,
- метапоиск.
Базовый поиск
Базовый поиск — программа, которая производит поиск по своей части индекса и предоставляет все соответствующие запросу документы.
Метапоиск — программа, которая обрабатывает поисковый запрос, определяет региональность пользователя, и если запрос популярный, то выдает уже готовый вариант выдачи, а если запрос новый, то выбирает базовый поиск и отдает команду на подбор документов, далее методом машинного обучения ранжирует найденные документы и предоставляет пользователю.
Классификация поисковых запросов
Чтобы дать релевантный ответ пользователю, поисковик сначала пытается понять, что ему конкретно нужно. Происходит анализ поискового запроса и параллельный анализ пользователя.
Поисковые запросы анализируются по параметрам:
- Длина;
- четкость;
- популярность;
- конкурентность;
- синтаксис;
- география.
Тип запроса:
- навигационный;
- информационный;
- транзакционный;
- мультимедийный;
- общий;
- служебный.
После разбора и классификации запроса происходит подбор функции ранжирования.
Обозначение типов запросов является конфиденциальной информацией и предложенные варианты — это догадка специалистов по поисковому продвижению.
Если пользователь задает общий запрос, то поисковая система выдает разные типы документов. И стоит понимать, что продвигая коммерческую страницу сайта в ТОП-10 по общему запросу, вы претендуете попасть не на одно из 10 мест, а в число мест
для коммерческих страниц, которое выделяется формулой ранжирования. И следовательно, вероятность вывода в топ по таким запросам ниже.Машинное обучение МатриксНет — алгоритм, введенный в 2009 году Яндексом, подбирающий функцию ранжирования документов по определенным запросам.
МатриксНет используется не только в поиске Яндекса, но и в научных целях. К примеру, в Европейском Центре ядерных исследований его используют для редких событий в больших объемах данных (ищут бозон Хиггса).
Первичные данные для оценки эффективности формулы ранжирования собирает отдел асессоров. Это специально обученные люди, которые оценивают выборку сайтов по экспериментальной формуле по следующим критериям.
Оценка качества сайта
Витальный — официальный сайт (Сбербанк, LPgenerator). Поисковому запросу соответствует официальный сайт, группы в социальных сетях, информация на авторитетных ресурсах.
Полезный (оценка 5) — сайт, который предоставляет расширенную информацию по запросу.
Пример — запрос: баннерная ткань.
Сайт, соответствующий оценке «полезный», должен содержать информацию:
- что такое баннерная ткань;
- технические характеристики;
- фотографии;
- виды;
- прайс-лист;
- что-то еще.
Примеры запроса в топе:
Релевантный+ (оценка 4) — это оценка означает, что страница соответствует поисковому запросу.
Релевантный- (оценка 3) — страница не точно соответствует поисковому запросу.
Допустим, по запросу «стражи галактики сеансы» выводится страница о фильме без сеансов, страница прошедшего сеанса, страница трейлера на youtube.
Нерелевантный (оценка 2) — страница не соответствует запросу.
Пример: по названию отеля выводится название другого отеля.Чтобы продвинуть ресурс по общему или информационному запросу, нужно создавать страницу соответствующую оценке «полезный».
Для четких запросов достаточно соответствовать оценке «релевантный+».
Релевантность достигается за счет текстового и ссылочного соответствия страницы поисковым запросам.
Выводы
- Не по всем запросам можно продвинуть коммерческую целевую страницу;
- Не по всем информационным запросам можно продвинуть коммерческий сайт;
- Продвигая общий запрос, создавайте полезную страницу.
Частой причиной, почему сайт не выходит в топ, является несоответствие контента продвигаемой страницы, поисковому запросу.
Об этом поговорим в следующей статье «Чек-лист по базовой оптимизации сайта».