Opbygning af en ikke-lineær regressionsmodel i Excel. Regression i Excel
Regressionslinjen er en grafisk afspejling af forholdet mellem fænomener. Du kan meget tydeligt konstruere en regressionslinje ind Excel program.
For at gøre dette skal du bruge:
1. Åbn Excel
2.Opret datakolonner. I vores eksempel vil vi bygge en regressionslinje eller et forhold mellem aggressivitet og selvtvivl hos elever i første klasse. 30 børn deltog i eksperimentet, dataene er præsenteret i Excel-tabellen:
1 kolonne - emnenummer
2 kolonne - aggressivitet i point
3 kolonne - diffidence i point

3.Så skal du vælge begge kolonner (uden kolonnenavnet), klik på fanen indsætte , vælge få øje på , og vælg den allerførste blandt de foreslåede layouts prik med markører .

4. Så vi har en skabelon for regressionslinjen - den såkaldte - scatter plot. For at gå til regressionslinjen skal du klikke på den resulterende figur og trykke på tab konstruktør, finde på panelet diagramlayout og vælg M EN ket9 , står der også f(x)

5. Så vi har en regressionslinje. Grafen viser også dens ligning og kvadratet af korrelationskoefficienten

6. Tilbage er blot at tilføje navnet på grafen og navnet på akserne. Hvis det ønskes, kan du også fjerne forklaringen, reducere antallet vandrette linjer gitter (tab layout , derefter net ). Grundlæggende ændringer og indstillinger foretages i fanen Layout

Regressionslinjen blev konstrueret i MS Excel. Nu kan du tilføje det til værkets tekst.
Statistisk databehandling kan også udføres ved hjælp af en add-on ANALYSEPAKKE(Fig. 62).
Fra de foreslåede elementer skal du vælge elementet " REGRESSION" og klik på den med venstre museknap. Klik derefter på OK.
Et vindue vises som vist i fig. 63.

Analyseværktøj " REGRESSION» bruges til at tilpasse en graf til et sæt observationer ved hjælp af mindste kvadraters metode. Regression bruges til at analysere indvirkningen på en individuel afhængig værdi variabel en eller flere uafhængige variable. For eksempel påvirker flere faktorer en atlets atletiske præstationer, herunder alder, højde og vægt. Det er muligt at beregne i hvilken grad hver af disse tre faktorer påvirker en atlets præstation, og derefter bruge disse data til at forudsige en anden atlets præstation.
Regressionsværktøjet bruger funktionen LINJEST.
REGRESSION Dialogboks
Etiketter Marker afkrydsningsfeltet, hvis den første række eller første kolonne i inputområdet indeholder overskrifter. Fjern markeringen i dette afkrydsningsfelt, hvis der ikke er nogen overskrifter. I dette tilfælde passende overskrifter for outputtabel vil data blive oprettet automatisk.
Pålidelighedsniveau Marker afkrydsningsfeltet for at inkludere et ekstra niveau i outputoversigtstabellen. I det relevante felt skal du indtaste det konfidensniveau, du vil anvende, ud over standardniveauet på 95 %.
Konstant - nul Marker afkrydsningsfeltet for at tvinge regressionslinjen til at passere gennem origo.
Output interval Indtast link til venstre øverste celle outputområde. Angiv mindst syv kolonner til outputoversigtstabellen, som vil omfatte: ANOVA-resultater, koefficienter, standardfejl for Y-beregningen, standardafvigelser, antal observationer, standardfejl for koefficienter.
Nyt regneark Indstil kontakten til denne position for at åbne nyt blad i projektmappen og indsæt analyseresultaterne startende i celle A1. Indtast om nødvendigt et navn til det nye ark i feltet, der er placeret ud for den tilsvarende alternativknap.
Ny arbejdsbog Indstil kontakten til denne position for at oprette en ny projektmappe, hvor resultaterne føjes til et nyt ark.
Residualer Marker afkrydsningsfeltet for at inkludere rester i outputtabellen.
Standardiserede rester Marker afkrydsningsfeltet for at inkludere standardiserede rester i outputtabellen.
Residual Plot Marker afkrydsningsfeltet for at plotte residualerne for hver uafhængig variabel.
Tilpas plot Marker afkrydsningsfeltet for at plotte de forudsagte versus observerede værdier.
Normalt sandsynlighedsplot Marker afkrydsningsfeltet for at plotte en normal sandsynlighedsgraf.
Fungere LINJEST
For at udføre beregninger, vælg med markøren den celle, hvori vi ønsker at vise gennemsnitsværdien, og tryk på tasten = på tastaturet. Angiv derefter i feltet Navn den ønskede funktion, For eksempel GENNEMSNIT(Fig. 22).
Fungere LINJEST beregner statistik for en serie ved hjælp af mindste kvadrater til at beregne en ret linje, der den bedste måde tilnærmer de tilgængelige data og returnerer derefter en matrix, der beskriver den resulterende rette linje. Du kan også kombinere funktionen LINJEST med andre funktioner til at beregne andre typer modeller, der er lineære i ukendte parametre (hvis ukendte parametre er lineære), herunder polynomielle, logaritmiske, eksponentielle og potensrækker. Fordi en matrix af værdier returneres, skal funktionen angives som en matrixformel.
Ligningen for en ret linje er:
y=m 1 x 1 +m 2 x 2 +...+b (i tilfælde af flere intervaller af x-værdier),
hvor den afhængige værdi y er en funktion af den uafhængige værdi x, er m-værdierne de koefficienter, der svarer til hver uafhængig variabel x, og b er en konstant. Bemærk at y, x og m kan være vektorer. Fungere LINJEST returnerer array(mn;mn-1;…;m 1 ;b). LINJEST kan også returnere yderligere regressionsstatistik.
LINJEST(kendte_værdier_y; kendte_værdier_x; konst; statistik)
Kendte_y_værdier - et sæt af y-værdier, der allerede er kendt for forholdet y=mx+b.
Hvis arrayet kendte_y_værdier har én kolonne, behandles hver kolonne i arrayet kendt_x_værdier som en separat variabel.
Hvis arrayet known_y_values har én række, behandles hver række i arrayet known_x_values som en separat variabel.
Kendte_x-værdier er et valgfrit sæt af x-værdier, der allerede er kendt for forholdet y=mx+b.
Arrayet kendte_x_værdier kan indeholde et eller flere sæt af variabler. Hvis der kun bruges én variabel, så kan arrayerne kendte_y_værdier og kendte_x_værdier have enhver form - så længe de har samme dimension. Hvis der bruges mere end én variabel, skal kendte_y_værdier være en vektor (dvs. et interval med én række højt eller én kolonne bred).
Hvis array_known_x_values er udeladt, antages arrayet (1;2;3;...) at have samme størrelse som array_known_values_y.
Const er en boolesk værdi, der angiver, om konstanten b skal være lig med 0.
Hvis argumentet "const" er SAND eller udeladt, så evalueres konstanten b som normalt.
Hvis "const"-argumentet er FALSK, så sættes værdien af b til 0, og værdierne af m vælges på en sådan måde, at relationen y=mx er opfyldt.
Statistik - En boolesk værdi, der angiver, om yderligere regressionsstatistik skal returneres.
Hvis statistik er SAND, returnerer LINEST yderligere regressionsstatistik. Det returnerede array vil se sådan ud: (mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid).
Hvis statistik er FALSK eller udeladt, returnerer LINEST kun koefficienterne m og konstanten b.
Ekstra regressionsstatistikker.(Tabel 17)
| Størrelse | Beskrivelse |
| se1,se2,...,sen | Standard fejlværdier for koefficienter m1,m2,...,mn. |
| seb | Standardværdi fejl for konstant b (seb = #N/A hvis "const"-argumentet er FALSK). |
| r2 | Determinismekoefficient. De faktiske værdier af y og værdierne opnået fra linjens ligning sammenlignes; Baseret på sammenligningsresultaterne beregnes determinismekoefficienten, normaliseret fra 0 til 1. Hvis den er lig med 1, er der en fuldstændig korrelation med modellen, dvs. der er ingen forskel mellem de faktiske og estimerede værdier af y. I det modsatte tilfælde, hvis bestemmelseskoefficienten er 0, er der ingen mening i at bruge regressionsligningen til at forudsige værdierne af y. For mere information om, hvordan man beregner r2, se "Noter" i slutningen dette afsnit. |
| sey | Standard fejl at estimere y. |
| F | F-statistisk eller F-observeret værdi. F-statistikken bruges til at bestemme, om den observerede sammenhæng mellem en afhængig og uafhængig variabel skyldes tilfældigheder. |
| df | Grader af frihed. Frihedsgrader er nyttige til at finde F-kritiske værdier i den statistiske tabel. For at bestemme konfidensniveauet for modellen, sammenligner du værdierne i tabellen med F-statistikken returneret af funktionen LINJEST. For mere information om beregning af df, se "Noter" i slutningen af dette afsnit. Dernæst viser eksempel 4 brugen af F- og df-værdier. |
| ssreg | Regressionssum af kvadrater. |
| ssresid | Restsum af kvadrater. For mere information om beregning af ssreg og ssresid, se "Noter" i slutningen af dette afsnit. |
Figuren nedenfor viser den rækkefølge, som yderligere regressionsstatistik returneres i (Figur 64).

Bemærkninger:
Enhver ret linje kan beskrives ved dens hældning og skæringspunkt med y-aksen:
Hældning (m): For at bestemme hældningen af en linje, normalt betegnet med m, skal du tage to punkter på linjen (x 1 ,y 1) og (x 2 ,y 2); hældningen vil være lig med (y 2 -y 1)/(x 2 -x 1).
Y-skæringspunkt (b): Y-skæringspunktet for en linje, normalt betegnet med b, er y-værdien for det punkt, hvor linjen skærer y-aksen.
Ligningen for den rette linje er y=mx+b. Hvis værdierne af m og b er kendte, kan ethvert punkt på linjen beregnes ved at erstatte værdierne af y eller x i ligningen. Du kan også bruge TREND-funktionen.
Hvis der kun er én uafhængig variabel x, kan du få hældningen og y-skæringspunktet direkte ved hjælp af følgende formler:
Hældning: INDEX(LINEST(kendte_y_værdier; kendte_x_værdier); 1)
Y-skæringspunkt: INDEX(LINEST(kendte_y_værdier; kendte_x_værdier); 2)
Nøjagtigheden af tilnærmelsen ved hjælp af den rette linje beregnet af funktionen LINJEST afhænger af graden af dataspredning. Jo tættere dataene er på en lige linje, jo mere nøjagtig er den model, der bruges af LINEST-funktionen. Funktionen LINEST bruger mindste kvadrater til at bestemme den bedste tilpasning til dataene. Når der kun er én uafhængig variabel, beregnes x, m og b ved hjælp af følgende formler:

hvor x og y er stikprøvemidler, for eksempel x = AVERAGE(kendte_x'er) og y = AVERAGE(kendte_y'er).
Tilpasningsfunktionerne LINEST og LGRFPRIBL kan beregne den rette linje eller eksponentielle kurve, der passer bedst til dataene. De besvarer dog ikke spørgsmålet om, hvilket af de to resultater, der er bedst egnet til at løse problemet. Du kan også evaluere TREND(kendte_y_værdier; kendte_x_værdier)-funktionen for en ret linje eller GROWTH(kendte_y_værdier; kendte_x_værdier)-funktionen for en eksponentiel kurve. Disse funktioner returnerer, medmindre new_x-værdier er angivet, en matrix af beregnede y-værdier for de faktiske x-værdier langs en linje eller kurve. Du kan derefter sammenligne de beregnede værdier med de faktiske værdier. Du kan også oprette diagrammer til visuel sammenligning.
Dirigent regressions analyse, Microsoft Excel beregner for hvert punkt kvadratet af forskellen mellem den forudsagte y-værdi og den faktiske y-værdi. Summen af disse kvadratiske forskelle kaldes restsummen af kvadrater (ssresid). Microsoft Excel beregner derefter den samlede sum af kvadrater (sstotal). Hvis const = TRUE eller værdien af dette argument ikke er angivet, total beløb kvadrater vil være lig med summen af kvadraterne af forskellene mellem de reelle værdier af y og gennemsnitsværdierne af y. Når const = FALSK, vil den samlede sum af kvadrater være lig med summen af kvadrater af de reelle y-værdier (uden at trække den gennemsnitlige y-værdi fra den partielle y-værdi). Regressionssummen af kvadrater kan så beregnes som følger: ssreg = sstotal - ssresid. Jo mindre restsummen af kvadrater er, jo større er værdien af bestemmelseskoefficienten r2, som viser, hvor godt ligningen opnået ved hjælp af regressionsanalyse forklarer sammenhængene mellem variable. Koefficienten r2 er lig med ssreg/sstotal.
I nogle tilfælde har en eller flere X-kolonner (lad Y- og X-værdier være i kolonner) ingen yderligere prædikativ værdi i andre X-kolonner. Med andre ord kan fjernelse af en eller flere X-kolonner resultere i Y-værdier beregnet med samme præcision. I dette tilfælde vil de redundante X-kolonner blive udelukket fra regressionsmodellen. Dette fænomen kaldes "kollinearitet", fordi de redundante kolonner af X kan repræsenteres som summen af flere ikke-redundante kolonner. Funktionen LINEST kontrollerer for kollinearitet og fjerner eventuelle redundante X-kolonner fra regressionsmodellen, hvis den detekterer dem. Fjernede X-kolonner kan identificeres i LINEST-output med en faktor på 0 og en se-værdi på 0. Fjernelse af en eller flere kolonner som overflødige ændrer værdien af df, fordi den afhænger af antallet af X-kolonner, der faktisk bruges til forudsigelsesformål. For mere information om beregning af df, se eksempel 4 nedenfor. Når df ændres på grund af fjernelse af redundante kolonner, ændres værdierne for sey og F også. Det anbefales ikke at bruge collinearitet ofte. Det skal dog bruges, hvis nogle X-kolonner indeholder 0 eller 1 som en indikator, der angiver, om forsøgets emne indgår i separat gruppe. Hvis const = TRUE eller en værdi for dette argument ikke er angivet, indsætter LINEST en ekstra X-kolonne for at modellere skæringspunktet. Hvis der er en kolonne med værdierne 1 for mænd og 0 for kvinder, og der er en kolonne med værdierne 1 for kvinder og 0 for mænd, fjernes den sidste kolonne, fordi dens værdier kan opnås fra kolonnen "mandlig indikator".
Beregningen af df for tilfælde, hvor X kolonner ikke er fjernet fra modellen på grund af kollinearitet, sker som følger: hvis der er k kendte_x kolonner og værdien const = TRUE eller ikke angivet, så er df = n – k – 1. Hvis const = FALSK, så df = n - k. I begge tilfælde øges df-værdien med 1, hvis X-kolonnerne fjernes på grund af kollinearitet.
Formler, der returnerer arrays, skal indtastes som array-formler.
Når du indtaster en matrix af konstanter som et argument, for eksempel kendte_x_værdier, skal du bruge et semikolon til at adskille værdier på den samme linje og et kolon til at adskille linjer. Separatortegnene kan variere afhængigt af indstillingerne i vinduet Sprog og indstillinger i Kontrolpanel.
Det skal bemærkes, at y-værdierne forudsagt af regressionsligningen muligvis ikke er korrekte, hvis de falder uden for intervallet for de y-værdier, der blev brugt til at definere ligningen.
Grundlæggende algoritme brugt i funktionen LINJEST, adskiller sig fra hovedfunktionsalgoritmen HÆLDE Og LINJESTYKKE. Forskellen mellem algoritmer kan føre til forskellige resultater med usikre og kolineære data. For eksempel, hvis de kendte_y_values-argumentdatapunkter er 0 og de kendte_x_values-argumentdatapunkter er 1, så:
Fungere LINJEST returnerer en værdi lig med 0. Funktionsalgoritme LINJEST bruges til at returnere passende værdier for kollineære data, og i I dette tilfælde mindst ét svar kan findes.
Funktionerne SLOPE og LINE returnerer #DIV/0!-fejlen. Algoritmen for SLOPE- og INTERCEPT-funktionerne bruges til kun at finde ét svar, men i dette tilfælde kan der være flere.
Udover at beregne statistik for andre typer af regression, kan LINJE bruges til at beregne intervaller for andre typer af regression ved at indtaste funktioner af x- og y-variablerne som serier af x- og y-variablerne for LINJE. For eksempel følgende formel:
LINJE(y_værdier, x_værdier^KOLUMNE($A:$C))
fungerer ved at have en kolonne med Y-værdier og en kolonne med X-værdier til at beregne en terningtilnærmelse (3. grads polynomium) af følgende form:
y=m 1 x+m 2 x 2 + m 3 x 3 +b
Formlen kan ændres til at beregne andre typer regression, men i nogle tilfælde skal outputværdierne og anden statistik muligvis justeres.
Efter min mening er økonometri som studerende en af de mest anvendte videnskaber, som jeg har kunnet stifte bekendtskab med inden for mit universitets mure. Med dens hjælp er det faktisk muligt at løse anvendte problemer på en virksomhedsskala. Hvor effektive disse beslutninger vil være, er det tredje spørgsmål. Den nederste linje er, at det meste af viden forbliver teori, men økonometri og regressionsanalyse er stadig værd at studere med særlig opmærksomhed.
Hvad forklarer regression?
Før vi begynder at overveje funktionerne i MS Excel, der giver os mulighed for at løse disse problemer, vil jeg gerne forklare dig i detaljer, hvad regressionsanalyse i bund og grund involverer. Dette vil gøre det lettere for dig at bestå eksamen, og vigtigst af alt bliver det mere interessant at studere emnet.
Forhåbentlig er du bekendt med begrebet en funktion fra matematikken. En funktion er forholdet mellem to variable. Når en variabel ændres, sker der noget med en anden. Vi ændrer X, og Y ændrer sig tilsvarende. Funktioner beskriver forskellige love. Når vi kender funktionen, kan vi erstatte vilkårlige værdier af X og se, hvordan Y ændrer sig.
Det har stor betydning, da regression er et forsøg på at forklare vha specifik funktion tilsyneladende usystematiske og kaotiske processer. For eksempel er det muligt at identificere forholdet mellem dollarkursen og arbejdsløsheden i Rusland.
Hvis dette mønster kan opdages, vil vi ved hjælp af den funktion, vi opnåede under beregningerne, være i stand til at lave en prognose for, hvad arbejdsløshedsraten vil være ved den N. dollarkurs i forhold til rublen.
Dette forhold vil blive kaldt korrelation. Regressionsanalyse involverer at beregne en korrelationskoefficient, der vil forklare den tætte sammenhæng mellem de variabler, vi overvejer (dollarkursen og antallet af job).
Denne koefficient kan være positiv eller negativ. Dens værdier varierer fra -1 til 1. Derfor kan vi observere en høj negativ eller positiv korrelation. Hvis det er positivt, vil stigningen i dollarkursen blive fulgt op af skabelse af nye job. Hvis den er negativ, betyder det, at en stigning i valutakursen vil blive efterfulgt af et fald i arbejdspladser.
Der er flere typer regression. Det kan være lineært, parabolsk, magt, eksponentielt osv. Vi vælger en model alt efter hvilken regression der vil svare specifikt til vores case, hvilken model der vil være så tæt som muligt på vores korrelation. Lad os se på dette ved hjælp af et eksempelproblem og løse det i MS Excel.
Lineær regression i MS Excel
For at løse lineære regressionsproblemer skal du bruge dataanalysefunktionaliteten. Det er muligvis ikke aktiveret for dig, så du skal aktivere det.
- Klik på knappen "Filer";
- Vælg punktet "Indstillinger";
- Klik på den næstsidste fane "Tilføjelser" i venstre side;
- Nedenfor vil vi se inskriptionen "Management" og "Go"-knappen. Klik på den;
- Marker boksen for "Analysepakke";
- Klik på "ok".

Prøveopgave
Batchanalysefunktionen er aktiveret. Lad os løse følgende problem. Vi har en stikprøve af data for flere år om antallet af nødsituationer på virksomhedens område og antallet af beskæftigede arbejdere. Vi skal identificere sammenhængen mellem disse to variable. Der er en forklarende variabel X - dette er antallet af arbejdere og en forklarende variabel - Y - dette er antallet af nødhændelser. Lad os fordele kildedataene i to kolonner.

Lad os gå til fanen "data" og vælge "Dataanalyse"
Vælg "Regression" på listen, der vises. Vi vælger de passende værdier i inputintervallerne Y og X.

Klik på "Ok". Analysen er afsluttet, og vi vil se resultaterne i et nyt ark.
De vigtigste værdier for os er markeret i figuren nedenfor.

Multipel R er bestemmelseskoefficienten. Den har en kompleks beregningsformel og viser, hvor meget du kan stole på vores korrelationskoefficient. Jo højere denne værdi er, jo mere tillid, jo mere succesfuld er vores model som helhed.
Y-Intercept og X1-Intercept er vores regressionskoefficienter. Som allerede nævnt er regression en funktion, og den har visse koefficienter. Vores funktion vil således se ud: Y = 0,64*X-2,84.
Hvad giver det os? Dette giver os mulighed for at lave en prognose. Lad os sige, at vi ønsker at ansætte 25 medarbejdere til en virksomhed, og vi er nødt til nogenlunde at forestille os, hvad antallet af nødsituationer vil være. Vi erstatter det i vores funktion givet værdi og vi får resultatet Y = 0,64 * 25 – 2,84. Vi vil have cirka 13 nødsituationer.
Lad os se, hvordan det virker. Tag et kig på billedet nedenfor. Den funktion, vi har fået, indeholder de faktiske værdier for de involverede medarbejdere. Se, hvor tæt værdierne er på rigtige spillere.

Du kan også bygge et korrelationsfelt ved at vælge området for Y'erne og X'erne, klikke på fanen "Indsæt" og vælge spredningsplottet.

Prikkerne er spredte, men bevæger sig generelt opad, som om der er en lige linje i midten. Og du kan også tilføje denne linje ved at gå til fanen "Layout" i MS Excel og vælge "Trend Line"
Dobbeltklik på linjen, der kommer frem, og du vil se, hvad der blev nævnt tidligere. Du kan ændre regressionstypen afhængigt af hvordan dit korrelationsfelt ser ud.
Du føler måske, at punkterne tegner en parabel i stedet for en lige linje, og at det ville være bedre for dig at vælge en anden type regression.

Konklusion
Lad os håbe det denne artikel gav dig en større forståelse af, hvad regressionsanalyse er, og hvorfor det er nødvendigt. Alt dette er af stor praktisk betydning.
Den lineære regressionsmetode giver os mulighed for at beskrive en ret linje, der bedst passer til en række ordnede par (x, y). Ligningen for en ret linje, kendt som lineær ligning, præsenteres nedenfor:
ŷ er den forventede værdi af y for en given værdi af x,
x er en uafhængig variabel,
a er et segment på y-aksen for en ret linje,
b er hældningen af den rette linje.
Nedenstående figur illustrerer dette koncept grafisk:
Ovenstående figur viser linjen beskrevet af ligningen ŷ =2+0,5x. Y-skæringspunktet er det punkt, hvor linjen skærer y-aksen; i vores tilfælde er a = 2. Linjens hældning, b, forholdet mellem linjens stigning og linjens længde, har en værdi på 0,5. En positiv hældning betyder, at linjen stiger fra venstre mod højre. Hvis b = 0, er linjen vandret, hvilket betyder, at der ikke er nogen sammenhæng mellem de afhængige og uafhængige variable. Med andre ord, at ændre værdien af x påvirker ikke værdien af y.
ŷ og y forveksles ofte. Grafen viser 6 ordnede par af punkter og en linje, ifølge den givne ligning

Denne figur viser punktet svarende til det ordnede par x = 2 og y = 4. Bemærk, at den forventede værdi af y ifølge linjen kl. x= 2 er ŷ. Vi kan bekræfte dette med følgende ligning:
ŷ = 2 + 0,5х =2 +0,5(2) =3.
Y-værdien repræsenterer det faktiske punkt, og ŷ-værdien er den forventede værdi af y ved hjælp af en lineær ligning for en given værdi af x.
Det næste trin er at bestemme den lineære ligning, der bedst matcher sættet af ordnede par, det talte vi om i den forrige artikel, hvor vi bestemte ligningstypen ved .
Brug af Excel til at definere lineær regression
For at bruge regressionsanalyseværktøjet indbygget i Excel, skal du aktivere tilføjelsen Analysepakke. Du kan finde den ved at klikke på fanen Fil -> Indstillinger(2007+), i dialogboksen, der vises MulighederExcel gå til fanen Tilføjelser. I marken Styring vælge TilføjelserExcel og klik Gå. Marker afkrydsningsfeltet ud for det vindue, der vises Analysepakke, klik OKAY.

I fanen Data i gruppe Analyse vil dukke op ny knap Dataanalyse.

For at demonstrere tilføjelsens arbejde vil vi bruge data, hvor en fyr og en pige deler et bord på badeværelset. Indtast dataene fra vores badekareksempel i kolonne A og B på det tomme ark.
Gå til fanen Data, i gruppe Analyse klik Dataanalyse. I det vindue, der kommer frem Dataanalyse Vælg Regression som vist på figuren, og klik på OK.

Indstil de nødvendige regressionsparametre i vinduet Regression, som det er vist på billedet:

Klik OKAY. Nedenstående figur viser de opnåede resultater:
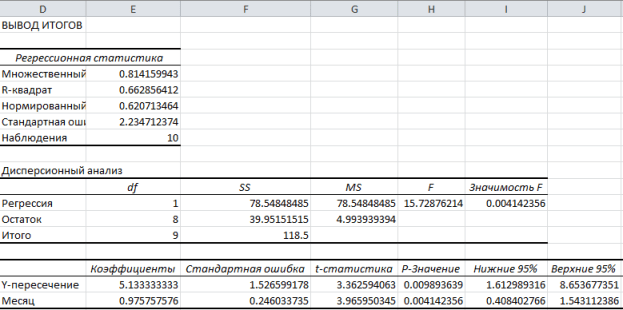
Disse resultater stemmer overens med dem, vi opnåede ved at lave vores egne beregninger i .
Dette er den mest almindelige måde at vise en variabels afhængighed af andre, for eksempel hvordan BNP niveau fra størrelsen udenlandsk investering eller fra Nationalbankens udlånsrente eller fra priser på nøgleenergiressourcer.
Modellering giver dig mulighed for at vise størrelsen af denne afhængighed (koefficienter), takket være hvilken du kan lave en direkte prognose og udføre en form for planlægning baseret på disse prognoser. Baseret på regressionsanalyse er det også muligt at træffe ledelsesbeslutninger med det formål at stimulere prioriterede årsager, der påvirker det endelige resultat; selve modellen vil hjælpe med at identificere disse prioriterede faktorer.
Generelt billede af den lineære regressionsmodel:
Y=a 0 +a 1 x 1 +...+a k x k
Hvor -en - regressionsparametre (koefficienter), x - påvirkningsfaktorer, k - antal modelfaktorer.
Indledende data
Blandt de indledende data har vi brug for et bestemt sæt data, der vil repræsentere flere på hinanden følgende eller indbyrdes forbundne værdier af den endelige parameter Y (for eksempel BNP) og det samme antal værdier af de indikatorer, hvis indflydelse vi studerer ( for eksempel udenlandske investeringer).
Ovenstående figur viser en tabel med de samme startdata, Y er en indikator for den erhvervsaktive befolkning, og antallet af virksomheder, størrelsen af investeringer i kapital og husstandsindkomst er påvirkende faktorer, det vil sige X'er.
Ud fra figuren kan man også drage en fejlagtig konklusion, at modellering kun kan handle om tidsserier, altså momentserier optaget sekventielt i tid, men det er ikke tilfældet, med samme succes kan man modellere i forhold til struktur. , for eksempel kan værdierne angivet i tabellen opdeles ikke efter år, men efter region.
At bygge tilstrækkeligt lineære modeller Det er ønskeligt, at kildedataene ikke har stærke fald eller kollapser; i sådanne tilfælde er det tilrådeligt at udføre udjævning, men vi vil tale om udjævning næste gang.
Analysepakke
Parametrene for en lineær regressionsmodel kan også beregnes manuelt ved hjælp af Ordinary Least Squares Method (OLS), men det er ret tidskrævende. Dette kan udregnes lidt hurtigere ved hjælp af samme metode ved at bruge formler i Excel, hvor programmet selv laver beregningerne, men du skal stadig indtaste formlerne manuelt.
Excel har et tilføjelsesprogram Analysepakke hvilket er smukt kraftfuldt værktøj at hjælpe analytikeren. Dette værktøjssæt kan blandt andet beregne regressionsparametre ved hjælp af den samme mindste kvadraters metode, med blot et par klik. Faktisk, hvordan man bruger dette værktøj vil blive diskuteret yderligere.
Aktiver analysepakken
Som standard er denne tilføjelse deaktiveret, og du finder den ikke i fanemenuen, så vi tager et trin-for-trin-kig på, hvordan du aktiverer det.

I Excel skal du øverst til venstre aktivere fanen Fil, i den menu, der åbnes, skal du kigge efter elementet Muligheder og klik på den.

I vinduet, der åbnes, til venstre skal du kigge efter elementet Tilføjelser og aktiver den, i denne fane nederst vil der være en drop-down kontrolliste, hvor det som standard vil blive skrevet Excel-tilføjelser , vil der være en knap til højre for rullelisten Gå, skal du klikke på den.

Et pop op-vindue vil bede dig om at vælge tilgængelige tilføjelser; i det skal du markere afkrydsningsfeltet Analysepakke og på samme tid, for en sikkerheds skyld, At finde en løsning(også en nyttig ting), og bekræft derefter dit valg ved at klikke på knappen Okay.
Instruktioner til at finde lineære regressionsparametre ved hjælp af analysepakken
Efter aktivering af Analysis Pack-tilføjelsen vil den altid være tilgængelig i hovedmenufanen Data under linket Dataanalyse
I det aktive værktøjsvindue Dataanalyse fra listen over muligheder, vi søger og vælger Regression

Derefter åbnes et vindue til opsætning og valg af kildedata til beregning af parametrene for regressionsmodellen. Her skal du angive intervallerne for de indledende data, nemlig den parameter, der beskrives (Y) og de faktorer, der påvirker den (X), som vist i figuren nedenfor; de resterende parametre er i princippet valgfrie at konfigurere.

Når du har valgt kildedataene og klikket på OK-knappen, producerer Excel beregninger på et nyt ark i den aktive projektmappe (medmindre det er angivet andet i indstillingerne), ser disse beregninger således ud:

Nøglecellerne er fyldt med gult; det er dem, du skal være opmærksom på først og fremmest; de andre parametre af betydning er også vigtige, men deres detaljerede analyse kræver sandsynligvis et separat indlæg.
Så, 0,865 - Det her R 2- Bestemmelseskoefficient, der viser, at 86,5 % af modellens beregnede parametre, det vil sige selve modellen, forklarer afhængigheden og ændringerne i den parameter, der undersøges - Y fra de undersøgte faktorer - X'er. Hvis overdrevet, så dette er en indikator for modellens kvalitet og jo højere den er, jo bedre. Det er klart, at det ikke kan være mere end 1 og anses for godt, når R 2 er over 0,8, og hvis det er mindre end 0,5, så kan rimeligheden af en sådan model stilles spørgsmålstegn ved.
Lad os nu gå videre til modelkoefficienter:
2079,85
- Det her en 0- en koefficient, der viser, hvad Y vil være, hvis alle faktorer anvendt i modellen er lig med 0, det er underforstået, at dette er en afhængighed af andre faktorer, der ikke er beskrevet i modellen;
-0,0056
- en 1- en koefficient, der viser vægten af indflydelsen af faktor x 1 på Y, det vil sige, at antallet af virksomheder inden for en given model påvirker indikatoren for den økonomisk aktive befolkning med en vægt på kun -0,0056 (en ret lille grad af indflydelse ). Minustegnet viser, at denne påvirkning er negativ, det vil sige, jo flere virksomheder, jo mindre økonomisk aktive befolkning, uanset hvor paradoksalt dette måtte have betydning;
-0,0026
- en 2- indflydelseskoefficient for mængden af investeringer i kapital på størrelsen af den økonomisk aktive befolkning; ifølge modellen er denne indflydelse også negativ;
0,0028
- en 3- indflydelseskoefficient for befolkningsindkomst på størrelsen af den erhvervsaktive befolkning, her er påvirkningen positiv, det vil sige, at en stigning i indkomsten ifølge modellen vil bidrage til en stigning i størrelsen af den erhvervsaktive befolkning.
Lad os samle de beregnede koefficienter i modellen:
Y = 2079,85 - 0,0056x 1 - 0,0026x 2 + 0,0028x 3
Faktisk er dette en lineær regressionsmodel, som for de indledende data brugt i eksemplet ser præcis sådan ud.
Model estimater og prognose
Som vi allerede har diskuteret ovenfor, er modellen bygget ikke kun til at vise størrelsen af afhængigheden af den parameter, der undersøges, af påvirkningsfaktorerne, men også således at det, ved at kende disse påvirkningsfaktorer, er muligt at lave en forudsigelse. Det er ret simpelt at lave denne prognose; du skal bare erstatte værdierne af de påvirkende faktorer i stedet for de tilsvarende X'er i den resulterende modelligning. I nedenstående figur er disse beregninger lavet i Excel i en separat kolonne.

De faktiske værdier (dem der fandt sted i virkeligheden) og de beregnede værdier i henhold til modellen i samme figur vises i form af grafer for at vise forskellen og dermed modellens fejl.
Jeg gentager endnu en gang, for at lave en prognose ved hjælp af en model, er det nødvendigt, at der er kendte påvirkningsfaktorer, og hvis vi taler om en tidsserie og dermed en prognose for fremtiden, for eksempel for den næste år eller måned, så er det ikke altid muligt at finde ud af, hvad de påvirkende faktorer bliver i netop denne fremtid. I sådanne tilfælde er det også nødvendigt at lave en prognose for de påvirkende faktorer; oftest gøres dette ved hjælp af en autoregressiv model - en model, hvor de påvirkende faktorer er objektet under undersøgelse og tid, det vil sige afhængigheden af indikatoren efter hvad det var i fortiden er modelleret.
Vi vil se på, hvordan man bygger en autoregressiv model i den næste artikel, men lad os nu antage, at vi ved, hvad værdierne af de påvirkende faktorer vil være i den fremtidige periode (i eksemplet, 2008), og ved at erstatte disse værdier ind i beregningerne får vi vores prognose for 2008.