Nested recursion. Examples of recursive algorithms
Hello Habrahabr!
In this article we'll talk about recursion problems and how to solve them.
Briefly about recursion
Recursion is a fairly common phenomenon that occurs not only in the fields of science, but also in everyday life. For example, the Droste effect, the Sierpinski triangle, etc. One way to see recursion is to point the Web camera at the computer monitor screen, naturally, having first turned it on. Thus, the camera will record the image of the computer screen and display it on this screen, it will be something like a closed loop. As a result, we will observe something similar to a tunnel.In programming, recursion is closely related to functions; more precisely, it is thanks to functions in programming that there is such a thing as recursion or a recursive function. In simple words, recursion is the definition of a part of a function (method) through itself, that is, it is a function that calls itself, directly (in its body) or indirectly (through another function).
A lot has been said about recursion. Here are some good resources:
- Recursion and recursive problems. Areas of application of recursion
Tasks
When learning recursion, the most effective way to understand recursion is to solve problems.How to solve recursion problems?
First of all, you need to understand that recursion is a kind of overkill. Generally speaking, everything that is solved iteratively can be solved recursively, that is, using a recursive function.from the network
Any algorithm implemented in recursive form can be rewritten in iterative form and vice versa. The question remains whether this is necessary and how effective it will be.
The following arguments can be given to justify this.
To begin with, we can recall the definitions of recursion and iteration. Recursion is a way of organizing data processing in which a program calls itself directly or with the help of other programs. Iteration is a way of organizing data processing in which certain actions are repeated many times without leading to recursive program calls.
After which we can conclude that they are mutually interchangeable, but not always with the same costs in terms of resources and speed. To justify this, we can give the following example: there is a function in which, in order to organize a certain algorithm, there is a loop that performs a sequence of actions depending on the current value of the counter (it may not depend on it). Since there is a cycle, it means that the body repeats a sequence of actions - iterations of the cycle. You can move operations into a separate subroutine and pass it the counter value, if any. Upon completion of the execution of the subroutine, we check the conditions for executing the loop, and if it is true, we proceed to a new call to the subroutine; if it is false, we complete the execution. Because We placed all the contents of the loop in a subroutine, which means that the condition for executing the loop is also placed in the subroutine, and it can be obtained through the return value of the function, parameters passed by reference or pointer to the subroutine, as well as global variables. Further, it is easy to show that a call to a given subroutine from a loop can be easily converted into a call or non-call (returning a value or simply completing work) of a subroutine from itself, guided by some conditions (those that were previously in the loop condition). Now, if you look at our abstract program, it roughly looks like passing values to a subroutine and using them, which the subroutine will change when it finishes, i.e. we replaced the iterative loop with a recursive call to a subroutine to solve a given algorithm.
The task of bringing recursion to an iterative approach is symmetrical.
To summarize, we can express the following thoughts: for each approach there is its own class of tasks, which is determined by the specific requirements for a specific task.
You can find out more about this
Just like an enumeration (cycle), recursion must have a stopping condition - Base case (otherwise, just like a cycle, recursion will work forever - infinite). This condition is the case to which the recursion goes (recursion step). At each step, a recursive function is called until the next call triggers the base condition and the recursion stops (or rather, returns to last call functions). The whole solution comes down to solving the base case. In the case where a recursive function is called to solve a complex problem (not the base case), a number of recursive calls or steps are performed in order to reduce the problem to a simpler one. And so on until we get a basic solution.
So the recursive function consists of
- Stopping Condition or Base Case
- A continuation condition or a recursion step is a way to reduce a problem to simpler ones.
Public class Solution ( public static int recursion(int n) ( // exit condition // Base case // when to stop repeating the recursion? if (n == 1) ( return 1; ) // Recursion step / recursive condition return recursion( n - 1) * n; ) public static void main(String args) ( System.out.println(recursion(5)); // call a recursive function ) )
Here the Basic condition is the condition when n=1. Since we know that 1!=1 and to calculate 1! we don't need anything. To calculate 2! we can use 1!, i.e. 2!=1!*2. To calculate 3! we need 2!*3... To calculate n! we need (n-1)!*n. This is the recursion step. In other words, to get the factorial value of a number n, it is enough to multiply the factorial value of the previous number by n.
Tags:
- recursion
- tasks
- java
Hello Habrahabr!
In this article we will talk about recursion problems and how to solve them.
Briefly about recursion
Recursion is a fairly common phenomenon that occurs not only in the fields of science, but also in everyday life. For example, the Droste effect, the Sierpinski triangle, etc. One way to see recursion is to point the Web camera at the computer monitor screen, naturally, having first turned it on. Thus, the camera will record the image of the computer screen and display it on this screen, it will be something like a closed loop. As a result, we will observe something similar to a tunnel.In programming, recursion is closely related to functions; more precisely, it is thanks to functions in programming that there is such a thing as recursion or a recursive function. In simple words, recursion is the definition of a part of a function (method) through itself, that is, it is a function that calls itself, directly (in its body) or indirectly (through another function).
A lot has been said about recursion. Here are some good resources:
- Recursion and recursive problems. Areas of application of recursion
Tasks
When learning recursion, the most effective way to understand recursion is to solve problems.How to solve recursion problems?
First of all, you need to understand that recursion is a kind of overkill. Generally speaking, everything that is solved iteratively can be solved recursively, that is, using a recursive function.from the network
Any algorithm implemented in recursive form can be rewritten in iterative form and vice versa. The question remains whether this is necessary and how effective it will be.
The following arguments can be given to justify this.
To begin with, we can recall the definitions of recursion and iteration. Recursion is a way of organizing data processing in which a program calls itself directly or with the help of other programs. Iteration is a way of organizing data processing in which certain actions are repeated many times without leading to recursive program calls.
After which we can conclude that they are mutually interchangeable, but not always with the same costs in terms of resources and speed. To justify this, we can give the following example: there is a function in which, in order to organize a certain algorithm, there is a loop that performs a sequence of actions depending on the current value of the counter (it may not depend on it). Since there is a cycle, it means that the body repeats a sequence of actions - iterations of the cycle. You can move operations into a separate subroutine and pass it the counter value, if any. Upon completion of the execution of the subroutine, we check the conditions for executing the loop, and if it is true, we proceed to a new call to the subroutine; if it is false, we complete the execution. Because We placed all the contents of the loop in a subroutine, which means that the condition for executing the loop is also placed in the subroutine, and it can be obtained through the return value of the function, parameters passed by reference or pointer to the subroutine, as well as global variables. Further, it is easy to show that a call to a given subroutine from a loop can be easily converted into a call or non-call (returning a value or simply completing work) of a subroutine from itself, guided by some conditions (those that were previously in the loop condition). Now, if you look at our abstract program, it roughly looks like passing values to a subroutine and using them, which the subroutine will change when it finishes, i.e. we replaced the iterative loop with a recursive call to a subroutine to solve a given algorithm.
The task of bringing recursion to an iterative approach is symmetrical.
To summarize, we can express the following thoughts: for each approach there is its own class of tasks, which is determined by the specific requirements for a specific task.
You can find out more about this
Just like an enumeration (cycle), recursion must have a stopping condition - Base case (otherwise, just like a cycle, recursion will work forever - infinite). This condition is the case to which the recursion goes (recursion step). At each step, a recursive function is called until the next call triggers the base condition and the recursion stops (or rather, returns to the last function call). The whole solution comes down to solving the base case. In the case where a recursive function is called to solve a complex problem (not the base case), a number of recursive calls or steps are performed in order to reduce the problem to a simpler one. And so on until we get a basic solution.
So the recursive function consists of
- Stopping Condition or Base Case
- A continuation condition or a recursion step is a way to reduce a problem to simpler ones.
Public class Solution ( public static int recursion(int n) ( // exit condition // Base case // when to stop repeating the recursion? if (n == 1) ( return 1; ) // Recursion step / recursive condition return recursion( n - 1) * n; ) public static void main(String args) ( System.out.println(recursion(5)); // call a recursive function ) )
Here the Basic condition is the condition when n=1. Since we know that 1!=1 and to calculate 1! we don't need anything. To calculate 2! we can use 1!, i.e. 2!=1!*2. To calculate 3! we need 2!*3... To calculate n! we need (n-1)!*n. This is the recursion step. In other words, to get the factorial value of a number n, it is enough to multiply the factorial value of the previous number by n.
Tags: Add tags
Recursion is when a subroutine calls itself. When faced with such an algorithmic construction for the first time, most people experience certain difficulties, but with a little practice, recursion will become clear and very useful tool in your programming arsenal.
1. The essence of recursion
A procedure or function may contain calls to other procedures or functions. The procedure can also call itself. There is no paradox here - the computer only sequentially executes the commands it encounters in the program and, if it encounters a procedure call, it simply begins to execute this procedure. It doesn't matter what procedure gave the command to do this.
Example of a recursive procedure:
Procedure Rec(a: integer); begin if a>
Let's consider what happens if a call, for example, of the form Rec(3) is made in the main program. Below is a flowchart showing the execution sequence of the statements.
Rice. 1. Block diagram of the recursive procedure.
Procedure Rec is called with parameter a = 3. It contains a call to procedure Rec with parameter a = 2. The previous call has not completed yet, so you can imagine that another procedure is created and the first one does not finish its work until it finishes. The calling process ends when parameter a = 0. At this point, 4 instances of the procedure are executed simultaneously. The number of simultaneously performed procedures is called recursion depth.
The fourth procedure called (Rec(0)) will print the number 0 and finish its work. After this, control returns to the procedure that called it (Rec(1)) and the number 1 is printed. And so on until all procedures are completed. The original call will print four numbers: 0, 1, 2, 3.
Another visual image of what is happening is shown in Fig. 2.

Rice. 2. Executing the Rec procedure with parameter 3 consists of executing the Rec procedure with parameter 2 and printing the number 3. In turn, executing the Rec procedure with parameter 2 consists of executing the Rec procedure with parameter 1 and printing the number 2. Etc.
As independent exercise think about what happens when you call Rec(4). Also consider what would happen if you called the Rec2(4) procedure below, with the operators reversed.
Procedure Rec2(a: integer); begin writeln(a); if a>0 then Rec2(a-1); end;
Please note that in the above examples the recursive call is inside conditional operator. This necessary condition in order for the recursion to ever end. Also note that the procedure calls itself with a different parameter than the one with which it was called. If the procedure does not use global variables, then this is also necessary so that the recursion does not continue indefinitely.
A little more possible complex circuit: Function A calls function B, which in turn calls A. This is called complex recursion. It turns out that the procedure described first must call a procedure that has not yet been described. For this to be possible, you need to use .
Procedure A(n: integer); (Forward description (header) of the first procedure) procedure B(n: integer); (Forward description of the second procedure) procedure A(n: integer); ( Full description procedures A) begin writeln(n); B(n-1); end; procedure B(n: integer); (Full description of procedure B) begin writeln(n); if n
A forward declaration of procedure B allows it to be called from a procedure A. A forward declaration of procedure A in in this example not required and added for aesthetic reasons.
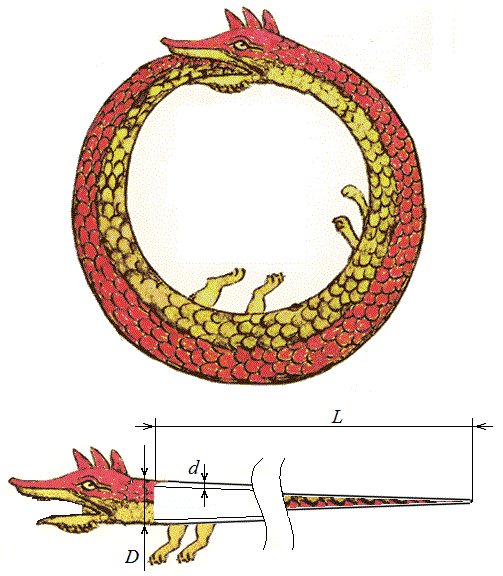
If ordinary recursion can be likened to an ouroboros (Fig. 3), then the image of complex recursion can be drawn from the famous children's poem, where “The wolves were frightened and ate each other.” Imagine two wolves eating each other and you will understand complex recursion.

Rice. 3. Ouroboros - a snake devouring its own tail. Drawing from the alchemical treatise “Synosius” by Theodore Pelecanos (1478).

Rice. 4. Complex recursion.
3. Simulating a loop using recursion
If a procedure calls itself, it essentially causes the instructions it contains to be executed again, similar to a loop. Some programming languages do not contain looping constructs at all, leaving programmers to organize repetitions using recursion (for example, Prolog, where recursion is a basic programming technique).
For example, let's simulate the work for loop. To do this, we need a step counter variable, which can be implemented, for example, as a procedure parameter.
Example 1.
Procedure LoopImitation(i, n: integer); (The first parameter is the step counter, the second parameter is the total number of steps) begin writeln("Hello N ", i); //Here are any instructions that will be repeated if i The result of a call of the form LoopImitation(1, 10) will be the execution of instructions ten times with the counter changing from 1 to 10. In in this case will be printed: Hello N 1 In general, it is not difficult to see that the parameters of the procedure are the limits for changing the counter values. You can swap the recursive call and the instructions to be repeated, as in the following example. Example 2.
Procedure LoopImitation2(i, n: integer); begin if i In this case, a recursive procedure call will occur before instructions begin to be executed. The new instance of the procedure will also, first of all, call another instance, and so on, until we reach the maximum value of the counter. Only after this the last of the called procedures will execute its instructions, then the second to last one will execute its instructions, etc. The result of calling LoopImitation2(1, 10) will be to print greetings in reverse order: Hello N 10 If we imagine a chain of recursively called procedures, then in example 1 we go through it from earlier called procedures to later ones. In example 2, on the contrary, from later to earlier. Finally, a recursive call can be placed between two blocks of instructions. For example: Procedure LoopImitation3(i, n: integer); begin writeln("Hello N ", i); (The first block of instructions may be located here) if i Here, the instructions from the first block are first executed sequentially, then the instructions from the second block are executed in reverse order. When calling LoopImitation3(1, 10) we get: Hello N 1 It would take two loops to do the same thing without recursion. You can take advantage of the fact that the execution of parts of the same procedure is spaced out over time. For example: Example 3: Converting a number to binary.
Obtaining the digits of a binary number, as is known, occurs by dividing with a remainder by the base of the number system 2. If there is a number, then its last digit in its binary representation is equal to Taking the whole part of division by 2: we get a number that has the same binary representation, but without the last digit. Thus, it is enough to repeat the above two operations until the next division field receives an integer part equal to 0. Without recursion it will look like this: While x>0 do begin c:=x mod 2; x:=x div 2; write(c); end; The problem here is that the digits of the binary representation are calculated in reverse order (latest first). To print a number in normal form, you will have to remember all the numbers in the array elements and print them in a separate loop. Using recursion, it is not difficult to achieve output in the correct order without an array and a second loop. Namely: Procedure BinaryRepresentation(x: integer); var c, x: integer; begin (First block. Executed in order of procedure calls) c:= x mod 2; x:= x div 2; (Recursive call) if x>0 then BinaryRepresentation(x); (Second block. Executed in reverse order) write(c); end; Generally speaking, we did not receive any winnings. The digits of the binary representation are stored in local variables, which are different for each running instance of the recursive procedure. That is, it was not possible to save memory. On the contrary, we waste extra memory storing many local variables x. However, this solution seems beautiful to me. A sequence of vectors is said to be given by a recurrence relation if the initial vector and the functional dependence of the subsequent vector on the previous one are given A simple example of a quantity calculated using recurrence relations is the factorial The next factorial can be calculated from the previous one as: By introducing the notation , we obtain the relation: The vectors from formula (1) can be interpreted as sets of variable values. Then the calculation of the required element of the sequence will consist of repeated updating of their values. In particular for factorial: X:= 1; for i:= 2 to n do x:= x * i; writeln(x); Each such update (x:= x * i) is called iteration, and the process of repeating iterations is iteration. Let us note, however, that relation (1) is a purely recursive definition of the sequence and the calculation of the nth element is actually the repeated taking of the function f from itself: In particular, for factorial one can write: Function Factorial(n: integer): integer; begin if n > 1 then Factorial:= n * Factorial(n-1) else Factorial:= 1; end; It should be understood that calling functions entails some additional overhead, so the first option for calculating the factorial will be slightly faster. In general, iterative solutions work faster than recursive ones. Before moving on to situations where recursion is useful, let's look at one more example where it should not be used. Let's consider special case recurrent relationships, when the next value in a sequence depends not on one, but on several previous values at once. An example is the famous Fibonacci sequence, in which each next element is the sum of the previous two: With a “frontal” approach, you can write: Function Fib(n: integer): integer; begin if n > 1 then Fib:= Fib(n-1) + Fib(n-2) else Fib:= 1; end; Each Fib call creates two copies of itself, each copy creates two more, and so on. The number of operations increases with the number n exponentially, although with an iterative solution linear in n number of operations. In fact, the above example teaches us not WHEN recursion should not be used, otherwise HOW it should not be used. After all, if there is a fast iterative (loop-based) solution, then the same loop can be implemented using a recursive procedure or function. For example: // x1, x2 – initial conditions (1, 1) // n – number of the required Fibonacci number function Fib(x1, x2, n: integer): integer; var x3: integer; begin if n > 1 then begin x3:= x2 + x1; x1:= x2; x2:= x3; Fib:= Fib(x1, x2, n-1); end else Fib:= x2; end; Still, iterative solutions are preferable. The question is, when should recursion be used in this case? Any recursive procedures and functions that contain just one recursive call to themselves can be easily replaced by iterative loops. To get something that doesn't have a simple non-recursive counterpart, you need to resort to procedures and functions that call themselves two or more times. In this case, the set of called procedures no longer forms a chain, as in Fig. 1, but a whole tree. There are wide classes of problems when the computational process must be organized in this way. Just for them, recursion will be the simplest and in a natural way solutions. The theoretical basis for recursive functions that call themselves more than once is the branch of discrete mathematics that studies trees. Definition:
we will call the finite set T, consisting of one or more nodes such that: This definition is recursive. In short, a tree is a set consisting of a root and subtrees attached to it, which are also trees. A tree is defined through itself. However this definition makes sense, since the recursion is finite. Each subtree contains fewer nodes than its containing tree. In the end, we come to subtrees containing only one node, and this is already clear what it is. Rice. 3. Tree. In Fig. Figure 3 shows a tree with seven nodes. Although ordinary trees grow from bottom to top, it is customary to draw them the other way around. When drawing a diagram by hand, this method is obviously more convenient. Because of this inconsistency, confusion sometimes arises when one node is said to be above or below another. For this reason, it is more convenient to use the terminology used when describing family trees, calling nodes closer to the root ancestors, and more distant ones descendants. A tree can be depicted graphically in some other ways. Some of them are shown in Fig. 4. According to the definition, a tree is a system of nested sets, where these sets either do not intersect or are completely contained in one another. Such sets can be depicted as regions on a plane (Fig. 4a). In Fig. 4b, the nested sets are not located on a plane, but are elongated into one line. Rice. 4b can also be viewed as a diagram of some algebraic formula containing nested parentheses. Rice. 4b gives one more popular way tree structure images in the form of a stepped list. Rice. 4. Other ways to represent tree structures: (a) nested sets; (b) nested parentheses; (c) concession list. The staggered list has obvious similarities to the formatting method program code. Indeed, a program written within the framework of the structured programming paradigm can be represented as a tree consisting of nested structures. You can also draw an analogy between a ledge list and appearance tables of contents in books where sections contain subsections, which in turn contain subsections, etc. Traditional way The numbering of such sections (section 1, subsections 1.1 and 1.2, subsection 1.1.2, etc.) is called the Dewey decimal system. Applied to the tree in Fig. 3 and 4 this system will give: 1. A; 1.1B; 1.2 C; 1.2.1 D; 1.2.2 E; 1.2.3 F; 1.2.3.1 G; In all algorithms related to tree structures, the same idea invariably appears, namely the idea passing or tree traversal. This is a way of visiting tree nodes in which each node is traversed exactly once. This results in a linear arrangement of tree nodes. In particular, there are three ways: you can go through the nodes in forward, reverse and end order. Forward traversal algorithm: This algorithm is recursive, since the traversal of a tree contains the traversal of subtrees, and they, in turn, are traversed using the same algorithm. In particular, for the tree in Fig. 3 and 4, direct traversal gives a sequence of nodes: A, B, C, D, E, F, G. The resulting sequence corresponds to a sequential left-to-right enumeration of nodes when representing a tree using nested parentheses and in decimal system Dewey, as well as the top-down passage when presented as a stepped list. When implementing this algorithm in a programming language, getting to the root corresponds to the procedure or function performing some actions, and going through subtrees corresponds to recursive calls to itself. In particular, for a binary tree (where each node has at most two subtrees), the corresponding procedure would look like this: // Preorder Traversal – English name for direct order procedure PreorderTraversal((Arguments)); begin //Passing the root DoSomething((Arguments)); //Transition of the left subtree if (There is a left subtree) then PreorderTransversal((Arguments 2)); //Transversal of the right subtree if (There is a right subtree) then PreorderTransversal((Arguments 3)); end; That is, first the procedure performs all actions, and only then all recursive calls occur. Reverse traversal algorithm: That is, all subtrees are traversed from left to right, and the return to the root is located between these traversals. For the tree in Fig. 3 and 4 this gives the sequence of nodes: B, A, D, C, E, G, F. In a corresponding recursive procedure, the actions will be located in the spaces between the recursive calls. Specifically for a binary tree: // Inorder Traversal – English name for reverse order procedure InorderTraversal((Arguments)); begin //Traveling the left subtree if (There is a left subtree) then InorderTraversal((Arguments 2)); //Passing the root DoSomething((Arguments)); //Traverse the right subtree if (A right subtree exists) then InorderTraversal((Arguments 3)); end; End-order traversal algorithm: For the tree in Fig. 3 and 4 this will give the sequence of nodes: B, D, E, G, F, C, A. In a corresponding recursive procedure, the actions will be located after the recursive calls. Specifically for a binary tree: // Postorder Traversal – English name for the end order procedure PostorderTraversal((Arguments)); begin //Traveling the left subtree if (There is a left subtree) then PostorderTraversal((Arguments 2)); //Traveling the right subtree if (There is a right subtree) then PostorderTraversal((Arguments 3)); //Passing the root DoSomething((Arguments)); end; If some information is located in tree nodes, then you can use the corresponding dynamic structure data. In Pascal this is done using variable type a record containing pointers to subtrees of the same type. For example, a binary tree where each node contains an integer can be stored using a variable of type PTree, which is described below: Type PTree = ^TTree; TTree = record Inf: integer; LeftSubTree, RightSubTree: PTree; end; Each node has a PTree type. This is a pointer, meaning each node must be created by calling the New procedure on it. If the node is a leaf node, then its LeftSubTree and RightSubTree fields are assigned the value nil. Otherwise, the LeftSubTree and RightSubTree nodes are also created by the New procedure. One such record is shown schematically in Fig. 5. Rice. 5. Schematic representation of a TTree type record. The record has three fields: Inf – a number, LeftSubTree and RightSubTree – pointers to records of the same TTree type. An example of a tree made up of such records is shown in Figure 6. Rice. 6. A tree made up of TTree type records. Each entry stores a number and two pointers that can contain either nil, or addresses of other records of the same type. If you have not previously worked with structures consisting of records containing links to records of the same type, we recommend that you familiarize yourself with the material about. Let's consider the algorithm for drawing the tree shown in Fig. 6. If each line is considered a node, then this image fully satisfies the definition of a tree given in the previous section. Rice. 6. Tree. The recursive procedure would obviously draw one line (the trunk up to the first branch), and then call itself to draw the two subtrees. Subtrees differ from the tree containing them in the coordinates of their starting point, rotation angle, trunk length, and the number of branches they contain (one less). All these differences should be made parameters of the recursive procedure. An example of such a procedure, written in Delphi, is presented below: Procedure Tree(Canvas: TCanvas; //Canvas on which the tree will be drawn x,y: extended; //Root coordinates Angle: extended; //Angle at which the tree grows TrunkLength: extended; //Trunk length n: integer / /Number of branches (how many more //recursive calls remain)); var x2, y2: extended; //Trunk end (branch point) begin x2:= x + TrunkLength * cos(Angle); y2:= y - TrunkLength * sin(Angle); Canvas.MoveTo(round(x), round(y)); Canvas.LineTo(round(x2), round(y2)); if n > 1 then begin Tree(Canvas, x2, y2, Angle+Pi/4, 0.55*TrunkLength, n-1); Tree(Canvas, x2, y2, Angle-Pi/4, 0.55*TrunkLength, n-1); end; end; To obtain Fig. 6 this procedure was called with the following parameters: Tree(Image1.Canvas, 175, 325, Pi/2, 120, 15); Note that drawing is carried out before recursive calls, that is, the tree is drawn in direct order. According to legend in the Great Temple of Banaras, under the cathedral marking the middle of the world, there is a bronze disk on which 3 diamond rods are fixed, one cubit high and thick as a bee. A long time ago, at the very beginning of time, the monks of this monastery committed offense before the god Brahma. Angry, Brahma erected three high rods and placed 64 pure gold discs on one of them, so that each smaller disk lies on more. As soon as all 64 disks are transferred from the rod on which God Brahma placed them when creating the world, to another rod, the tower along with the temple will turn into dust and the world will perish under thunderclaps. Independently of Brahma, this puzzle was proposed at the end of the 19th century by the French mathematician Edouard Lucas. The sold version usually used 7-8 disks (Fig. 7). Rice. 7. Towers of Hanoi puzzle. Suppose there is a solution for n-1 disk. Then for shifting n disks, proceed as follows: 1) Shift n-1 disk. Because for the case n= 1 the rearrangement algorithm is obvious, then by induction, using actions (1) – (3), we can rearrange an arbitrary number of disks. Let's create a recursive procedure that prints the entire sequence of shifts for a given number of disks. Each time such a procedure is called, it must print information about one shift (from point 2 of the algorithm). For rearrangements from points (1) and (3), the procedure will call itself with the number of disks reduced by one. //n – number of disks //a, b, c – pin numbers. Shifting is done from pin a, //to pin b with auxiliary pin c. procedure Hanoi(n, a, b, c: integer); begin if n > 1 then begin Hanoi(n-1, a, c, b); writeln(a, " -> ", b); Hanoi(n-1, c, b, a); end else writeln(a, " -> ", b); end; Note that the set of recursively called procedures in this case forms a tree traversed in reverse order. Task parsing is to calculate the value of the expression using an existing line containing an arithmetic expression and the known values of the variables included in it. The process of calculating arithmetic expressions can be represented as a binary tree. Indeed, each of the arithmetic operators (+, –, *, /) requires two operands, which will also be arithmetic expressions and, accordingly, can be considered as subtrees. Rice. Figure 8 shows an example of a tree corresponding to the expression: Rice. 8. Syntax tree corresponding arithmetic expression (6). In such a tree, the end nodes will always be variables (here x) or numeric constants, and all internal nodes will contain arithmetic operators. To execute an operator, you must first evaluate its operands. Thus, the tree in the figure should be traversed in terminal order. Corresponding sequence of nodes called reverse Polish notation arithmetic expression. When constructing a syntax tree, you should pay attention to the following feature. If, for example, there is an expression and we will read the operations of addition and subtraction from left to right, then the correct syntax tree will contain a minus instead of a plus (Fig. 9a). In essence, this tree corresponds to the expression. It is possible to make the creation of a tree easier if you analyze expression (8) in reverse, from right to left. In this case, the result is a tree with Fig. 9b, equivalent to tree 8a, but not requiring replacement of signs. Similarly, from right to left, you need to analyze expressions containing multiplication and division operators. Rice. 9. Syntax trees for expression a – b + c when reading from left to right (a) and from right to left (b). This approach does not completely eliminate recursion. However, it allows you to limit yourself to only one call to a recursive procedure, which may be sufficient if the motive is to maximize performance. The idea of this approach is to replace recursive calls with a simple loop that will be executed as many times as there are nodes in the tree formed by the recursive procedures. What exactly will be done at each step should be determined by the step number. Match the step number and necessary actions– the task is not trivial and in each case it will have to be solved separately. For example, let's say you want to do k nested loops n steps in each: For i1:= 0 to n-1 do for i2:= 0 to n-1 do for i3:= 0 to n-1 do … If k is unknown in advance, it is impossible to write them explicitly, as shown above. Using the technique demonstrated in Section 6.5, you can obtain the required number of nested loops using a recursive procedure: Procedure NestedCycles(Indexes: array of integer; n, k, depth: integer); var i: integer; begin if depth To get rid of recursion and reduce everything to one cycle, note that if you number the steps in the radix number system n, then each step has a number consisting of the numbers i1, i2, i3, ... or the corresponding values from the Indexes array. That is, the numbers correspond to the values of the cycle counters. Step number in regular decimal notation: There will be a total of steps n k. By going through their numbers in the decimal number system and converting each of them to the radix system n, we get the index values: M:= round(IntPower(n, k)); for i:= 0 to M-1 do begin Number:= i; for p:= 0 to k-1 do begin Indexes := Number mod n; Number:= Number div n; end; DoSomething(Indexes); end; Let us note once again that the method is not universal and you will have to come up with something different for each task. 1. Determine what the following recursive procedures and functions will do. (a) What will the following procedure print when Rec(4) is called? Procedure Rec(a: integer); begin writeln(a); if a>0 then Rec(a-1); writeln(a); end; (b) What will be the value of the function Nod(78, 26)? Function Nod(a, b: integer): integer; begin if a > b then Nod:= Nod(a – b, b) else if b > a then Nod:= Nod(a, b – a) else Nod:= a; end; (c) What will be printed by the procedures below when A(1) is called? Procedure A(n: integer); procedure B(n: integer); procedure A(n: integer); begin writeln(n); B(n-1); end; procedure B(n: integer); begin writeln(n); if n (d) What will the procedure below print when calling BT(0, 1, 3)? Procedure BT(x: real; D, MaxD: integer); begin if D = MaxD then writeln(x) else begin BT(x – 1, D + 1, MaxD); BT(x + 1, D + 1, MaxD); end; end; 2. Ouroboros - a snake devouring its own tail (Fig. 14) when unfolded has a length L, diameter around the head D, abdominal wall thickness d. Determine how much tail he can squeeze into himself and how many layers will the tail be laid in after that? Rice. 14. Expanded ouroboros. 3. For the tree in Fig. 10a indicate the sequence of visiting nodes in forward, reverse and end traversal order. 4. Graphically depict the tree defined using nested brackets: (A(B(C, D), E), F, G). 5. Graphically depict the syntax tree for the following arithmetic expression: Write this expression in reverse Polish notation. 6. For the graph below (Fig. 15), write down the adjacency matrix and the incidence matrix. 1. Having calculated the factorial sufficiently large number times (a million or more), compare the effectiveness of recursive and iterative algorithms. How much will the execution time differ and how will this ratio depend on the number whose factorial is being calculated? 2. Write a recursive function that checks the correct placement of parentheses in a string. If the arrangement is correct, the following conditions are met: (a) the number of opening and closing parentheses is equal. Examples of incorrect placement:)(, ())(, ())((), etc. 3. The line may contain both parentheses and square brackets. Each opening parenthesis has a corresponding closing parenthesis of the same type (round - round, square - square). Write a recursive function that checks whether the parentheses are placed correctly in this case. Example of incorrect placement: ([) ]. 4. The number of regular bracket structures of length 6 is 5: ()()(), (())(), ()(()), ((())), (()()). Note: Correct parenthesis structure of minimum length "()". Structures of longer length are obtained from structures of shorter length in two ways: (a) if the smaller structure is taken into brackets, 5. Create a procedure that prints all possible permutations for integers from 1 to N. 6. Create a procedure that prints all subsets of the set (1, 2, ..., N). 7. Create a procedure that prints all possible representations of the natural number N as the sum of other natural numbers. 8. Create a function that calculates the sum of the array elements using the following algorithm: the array is divided in half, the sums of the elements in each half are calculated and added. The sum of the elements in half the array is calculated using the same algorithm, that is, again by dividing in half. Divisions occur until the resulting pieces of the array contain one element each and calculating the sum, accordingly, becomes trivial. Comment: This algorithm is an alternative. In the case of real-valued arrays, it usually allows for smaller rounding errors. 10. Create a procedure that draws the Koch curve (Figure 12). 11. Reproduce the figure. 16. In the figure, at each subsequent iteration the circle is 2.5 times smaller (this coefficient can be made a parameter). 1. D. Knuth. The art of computer programming. v. 1. (section 2.3. “Trees”). Recursions are interesting events in their own right, but in programming they are especially important in specific cases. When encountering them for the first time, quite a significant number of people have problems understanding them. This is due to the huge scope of potential applications of the term itself, depending on the context in which “recursion” is used. But we can hope that this article will help avoid any possible misunderstanding or misunderstanding. The word "recursion" has a whole range of meanings, which depend on the field in which it is applied. The universal designation is as follows: recursions are definitions, images, descriptions of objects or processes in the objects themselves. They are possible only in cases where the object is part of itself. Mathematics, physics, programming and a number of other scientific disciplines define recursion in their own way. Practical Application she found at work information systems and physical experiments. Recursive situations, or recursion in programming, are moments when a program procedure or function calls itself. No matter how strange it may sound for those who started learning programming, there is nothing strange here. It should be remembered that recursions are not difficult, and in some cases they replace loops. If the computer is correctly instructed to call a procedure or function, it will simply start executing it. Recursion can be finite or infinite. In order for the first one to stop causing itself, it must also contain conditions for termination. This can be to decrease the value of a variable and, when a certain value is reached, to stop the call and terminate the program/proceed to subsequent code, depending on the needs to achieve certain goals. By infinite recursion we mean that it will be called as long as the computer or program in which it runs is running. It is also possible to organize complex recursion using two functions. Let's say there are A and B. Function A has a call to B in its code, and B, in turn, indicates to the computer the need to execute A. Complex recursions are a way out of a number of complex logical situations for computer logic. If the reader of these lines has studied program loops, then he has probably already noticed the similarity between them and recursion. In general, they can indeed perform similar or identical tasks. Using recursion it is convenient to simulate the operation of a loop. This is especially useful where the cycles themselves are not very convenient to use. The software implementation scheme does not differ much between different high-level programming languages. But still, recursion in Pascal and recursion in C or another language have their own characteristics. It can be successfully implemented in low-level languages like Assembly, but this is more problematic and time-consuming. What is a "tree" in programming? This is a finite set consisting of at least one node that: In other words: trees contain subtrees, which contain more trees, but in smaller numbers than the previous tree. This continues until one of the nodes can no longer move forward, and this will mark the end of the recursion. There is one more nuance about the schematic representation: ordinary trees grow from bottom to top, but in programming they are drawn the other way around. Nodes that have no continuation are called leaf nodes. For ease of designation and convenience, genealogical terminology (ancestors, children) is used. Recursion in programming has found its application in solving a number of complex tasks. If it is necessary to make only one call, then it is easier to use an integration loop, but with two or more repetitions, in order to avoid building a chain and make their execution in the form of a tree, recursive situations are used. For a wide class of tasks, organization computing process This method is the most optimal in terms of resource consumption. So, recursion in Pascal or any other high level language programming is a call to a function or procedure until the conditions are met, regardless of the number of external calls. In other words, a program can have only one call to a subroutine, but it will occur until a predetermined moment. In some ways, this is an analogue of a cycle with its own specifics of use. Despite general scheme implementations and specific application in each individual case, recursion in programming has its own characteristics. This may cause difficulty during searching required material. But you should always remember: if a programming language calls functions or procedures, then calling recursion is feasible. But its most significant differences appear when using low and high languages programming. This is especially true for software implementation capabilities. Execution ultimately depends on what task is posed, and recursion is written in accordance with it. The functions and procedures used are different, but their goal is always the same - to force them to call themselves. For beginners, understanding it may be difficult at first, so you need examples of recursion, or at least one. Therefore, we should give a small example from everyday life that will help to understand the very essence of this mechanism for achieving goals in programming. Take two or more mirrors, place them so that all the others are displayed in one. You can see that the mirrors reflect themselves multiple times, creating an infinity effect. Recursions are, figuratively speaking, reflections (there will be many of them). As you can see, it’s not difficult to understand, if only you have the desire. And by studying programming materials, you can further understand that recursion is also a very easy task to complete. Application programming always deals with solving applied problems by applying the efforts of the programmer to achieve results under non-ideal conditions. It is precisely because of the imperfection of this world and the limited resources that the need for programmers arises: someone needs to help theorists push their harmonious and beautiful theory into practice. Def fib(n): if n<0: raise Exception("fib(n) defined for n>=0") if n> @memoized def fib(n): if n<0: raise Exception("fib(n) defined for n>=0") if n>1: return fib(n-1) + fib(n-2) return n Def fib(n): if n<0: raise Exception("fib(n) defined for n>=0") n0 = 0 n1 = 1 for k in range(n): n0, n1 = n1, n0+n1 return n0 tex \begin(tikzpicture) \node (is-root) (+) child ( node (2) ) child ( node (2) ); \path (is-root) +(0,+0.5\tikzleveldistance) node (\textit(Tree 1)); \end(tikzpicture) \begin(tikzpicture) \node (is-root) (*) child ( node (+) child (node(2)) child (node(2)) ) child ( node (+) child (node (2)) child (node(2)) ); \path (is-root) +(0,+0.5\tikzleveldistance) node (\textit(Tree 2)); \end(tikzpicture) As you can easily see, the task turns into a simple “depth-first traversal of the tree”: for each node we display the contents of all its children, after which we display the node itself. That is, the code will be: Class TreeNode(object): def __init__(self, value=None, children=): self.value = value self.children = children def printTree(node): for child in node.children: printTree(child) print node.value , def main(): tree1 = TreeNode("+", [ TreeNode(2), TreeNode(2) ]) tree2 = TreeNode("*", [ TreeNode("+", [ TreeNode(2), TreeNode(2 ) ]), TreeNode("+", [ TreeNode(2), TreeNode(2) ]) ]) print "Tree1:", printTree(tree1) print print "Tree2:", printTree(tree2) print if __name__ == "__main__": main() It would seem that everything is fine! The code works fine as long as the tree meets the requirements: any node has an array of children (possibly empty) and some value. Who can tell what other requirements for this tree? I won't languish. Requirement: not very deep tree. How so? Here's how: Def buildTree(depth): root = TreeNode("1") node = root for k in range(depth): node = TreeNode("--", [ node ]) return node def depthTest(depth): tree = buildTree( depth) print "Tree of depth", depth, ":", printTree(tree) def main(): for d in range(10000): depthTest(d) Let’s mentally rewrite this code 1-in-1 in C++ (I’ll leave this task to the reader as a warm-up), and try to find the limit when the application hits a limitation... for the lazy #include Def printTree(node): opened = False for child in node.children: if not opened: print "(", opened = True printTree(child) print node.value, if opened: print ")", Nothing has changed, it still crashes when trying to print a tree with a depth of 997. And now the same thing, but on the pluses... Oops. The depth of the stack during the fall is 87327. Stop. We just added one local variable that does not in any way affect the algorithm or the essence of what is happening, and the maximum tree size was reduced by 17%! And now the fun part - all this greatly depends on the compiler options, on what platform it is executed on, in what OS and with what settings. But that's not the funniest thing. Let's imagine that this function is used by another function. Everything is fine if she is the only one - we can calculate how many actual steps are less than the maximum depth. What if this function is used from another recursive one? The capabilities of that function will then depend on the depth of the other function. This is how our beautiful simple algorithm suddenly stops fitting into our imperfect suitcase. I’ll leave it to the reader to imagine how good it is to have such restrictions in a service that is running in production and provides a certain service to unsuspecting hackers who do nothing but poke at this service with their dirty fuzzy testers. Firstly, we cannot know exactly how much of it has already been used. Secondly, we cannot know exactly how much of it is left. Thirdly, we cannot guarantee the availability of a certain size of this resource for each call. Fourthly, we cannot record the consumption of this resource. Thus, we become dependent on a resource that is damn difficult to control and distribute. As a result, we cannot guarantee any performance of this feature/service. It’s good if our service works in a managed context: java, python, .net, etc. It’s bad if the service works in an uncontrolled environment: javascript (with which everything is bad). It's even worse if the service runs in C++, and the depth of recursion depends on the data passed by the user. So, to get rid of the problems created by recursion, you can do the following (from simple to complex): The boundless sweetness of freedom Canonical non-recursive implementation of depth-first tree traversal: Here is the same code, only written “head-on”, preserving the context (at the same time, displaying commas between elements): Def printTree(node): stack = [ (node, 0) ] while len(stack)>0: i = len(stack)-1 node, phase = stack[i] if phase< len(node.children):
child = node.children
if phase == 0:
print "{",
if phase >0: print ",", stack.append((child, 0)) stack[i] = (node, phase+1) else: print node.value, if phase>0: print ")", del stack[i ] Why don't you use recursion?
Hello N 2
…
Hello N 10
…
Hello N 1
…
Hello N 10
Hello N 10
…
Hello N 14. Recurrence relations. Recursion and Iteration
5. Trees
5.1. Basic definitions. Ways to depict trees
a) There is one special node called the root of this tree.
b) The remaining nodes (excluding the root) are contained in pairwise disjoint subsets, each of which in turn is a tree. Trees are called subtrees of this tree.

5.2. Passing trees
5.3. Representation of a tree in computer memory

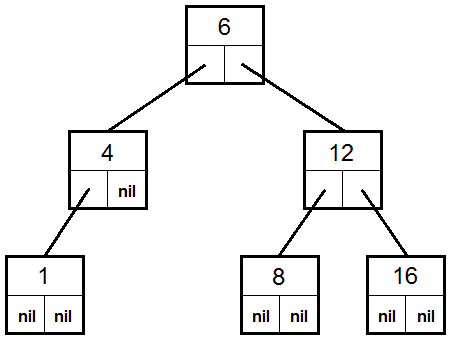
6. Examples of recursive algorithms
6.1. Drawing a tree

6.2. Hanoi Towers
The process requires that larger disk never found myself over anything less. The monks are in a quandary: in what order should they do the shifts? It is required to provide them with software to calculate this sequence.
2) Shift n th disk onto the remaining free pin.
3) We shift the stack from n-1 disk received in point (1) on top n-th disk.6.3. Parsing Arithmetic Expressions


7.3. Determining a tree node by its number
Security questions
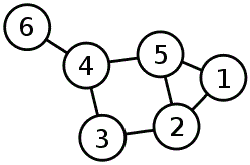
Tasks
(b) within any pair there is an opening - corresponding closing bracket, the brackets are placed correctly.
Write a recursive program to generate all regular bracket structures of length 2 n.
(b) if two smaller structures are written sequentially.
Literature
2. N. Wirth. Algorithms and data structures.What is "recursion" anyway?
What is meant by recursion in programming?

Recursion trees

Why is it used in programming?

Differences between recursion in different programming languages
Recursion is easy. How easy is it to remember the contents of an article?

Recursion: See recursion.
All programmers are divided into 11 2 categories: those who do not understand recursion, those who already understand, and those who have learned to use it. In general, I’m nothing but cardboard, so you, the reader, will still have to comprehend the Tao of Recursion on your own, I’ll just try to give out a few magic kicks in the right direction. - How is it built?
- Perfect! Only the hand sticks out a little from the suitcase.
It is precisely when trying to place a coherent theory of an algorithm into a hard backpack of real resources that one has to constantly cut and repack, and instead of the beautiful and coherent definitions of Fibonacci:
you have to fence in all sorts of dirty hacks, ranging from:
And finally ending:So what is recursion?
Recursion is essentially a proof by induction. We tell you how to get a result for a certain state, assuming that we have a result for another set of states, and we also tell you how to get a result in those states to which everything slides one way or another. If you are expecting guests and suddenly notice a stain on your suit, do not be upset. This can be fixed.
For example, stains from vegetable oil can be easily removed with gasoline. Gasoline stains can be easily removed with an alkali solution.
Alkali stains disappear with vinegar essence. Traces of vinegar essence should be rubbed with sunflower oil.
Well, you already know how to remove stains from sunflower oil...
Now let's look at a classic example: depth-first tree traversal. But no, let's look at another example: we need to print a tree of expressions in the form of reverse Polish notation. That is, for tree 1 we want to print “2 2 +” and for tree 2 “2 2 + 2 2 + *”. 
We launch, and whoops! "Tree of depth 997: RuntimeError: maximum recursion depth exceeded." We look into the documentation and find the sys.getrecursionlimit function. Now let's move away from the world of interpreted languages, and move into the world of languages that run directly on the processor. For example, in C++.
Let’s run… “Bus error (core dumped)”. Judging by gdb, at the time of the fall the stack was 104790 frames deep. What happens if we want to print not just consecutively through spaces, but also print “(” and “)” around expressions? Well, that is, for tree 1 the result should be (2 2 +) and for tree 2 - ((2 2 +)(2 2 +)*)? Let's rewrite... So what's the problem?
Using a recursive algorithm involves using a virtually uncontrollable resource: the call stack. What to do?
If we are not working on a microcontroller, we don’t have to worry about the size of the stack: it should be enough for a normal chain of calls. Provided, of course, that we care about the hygiene of local variables: large objects and arrays are allocated using memory (new/malloc). However, using recursion means that instead of a limited number of calls, we will simply have a countable number of them.
- Strictly limit the maximum size/format/numbers in incoming data. Hello, zip bombs and their ilk - sometimes even a small incoming package can cause a big commotion.
- Strictly limit the maximum call depth to a certain number. It is important to remember that this number should be VERY small. That is, about hundreds. And be sure to add tests that check that the program does not break with this maximum number. Moreover, with the maximum number on all possible branches of execution (hello to the allocation of local variables on demand). And don’t forget to check this test on different compilation options and after each build.
- Strictly limit the amount of stack used. Using complex workarounds and knowledge of the practical implementation of execution in hardware, you can get the size of the stack that is currently used (such as taking the address of a local volatile variable). In some cases (for example, through libunwind in Linux), you can also get the amount of stack available to the current thread, and take the difference between them. When using this method, it is important to have tests that check that pruning is guaranteed to work for all types of input data - for example, it can be fun if the check is carried out in one method, which is recursive through 3-4 others. And it can fail in the intermediate one... But only in release mode, after some functions are inline, for example. However, tests for the maximum acceptable complexity are also important here, so as not to accidentally cut off some of the correct input requests that clients actually use.
- Best way: get rid of recursion.And do not lie that you are free and holy - You are captive and captive.
I opened the firmament before you!
Times change their course - Look at the palms...
Deny freedom
Sergey Kalugin
Yes, yes. After comprehending the Tao of recursion, you also comprehend the Tao of non-recursion. Almost all recursive algorithms have non-recursive counterparts. Starting from more efficient ones (see Fibonacci above), and ending with equivalent ones that use a queue in memory instead of a call stack.
def printTree(node): stack = [ (node, False, False) ] while len(stack)>0: i = len(stack)-1 node, visited, opened = stack[i] if not visited: for child in reversed(node.children): if not opened: print "(", opened = True stack.append((child, False, False)) visited = True stack[i] = (node, visited, opened) else: print node .value, if opened: print ")", del stack[i]
As is easy to see, the algorithm has not changed, but instead of using a call stack, the stack array is used, located in memory, and storing both the processing context (in our case, the opened flag) and the processing context (in our case, before or after processing children). In cases where you need to do something between each of the recursive calls, either processing phases are added. Please note: this is an already optimized algorithm that adds all children to the stack at once, and that is why it adds in reverse order. This ensures that the order is kept the same as the original non-recursive algorithm.
Yes, the transition to non-recursive technologies is not entirely free: we periodically pay for more expensive ones - dynamic memory allocation for organizing the stack. However, this pays off: not all local variables are stored in the “manual stack”, but only the minimum necessary context, the size of which can already be controlled. The second cost item: code readability. Code written in non-recursive form is somewhat more difficult to understand due to branches from the current state. The solution to this problem lies in the area of code organization: putting steps into separate functions and naming them correctly.Misadventure
Despite the presence of a certain “non-recursion tax,” I personally consider it obligatory to pay in any place where data received from the user is processed in one way or another.