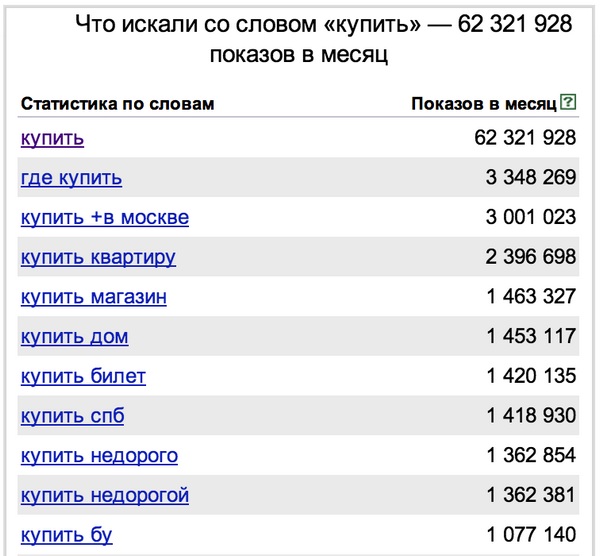
Working with various search engines. SEO jungle, or How do search engines work? Search engine, what is it?
Many people want to be in the TOP, but not everyone understands how search engines work. And by the turn of 2017, the requirements for websites from search engines became even more stringent (more details in the article). Therefore, in order to constantly be in the top, you first need to at least understand how search algorithms work.
After reading this article to the end, you will understand the principles on which the work of Yandex and Google is based, and you will learn a little more about mail, rambler and bing. At the same time, we will not touch upon website ranking factors, because... This is a very voluminous material that requires a separate publication.
Well, or if you want the goal, purpose or even mission of a search engine is to give the most accurate answer to the user’s request in the form of a list of links to various resources.
In order to generate a high-quality list of sites, the search engine creates a database. That is, if your site or a new site page is not indexed by Yandex or Google, then it will not be in the search results. A database of sites is formed by search robots, which provide information about the sites to their "boss", and he enters the data into the registry. For example, if you registered your site in or, you can find information there about how many pages of your site were indexed by the search engine.
Next, the entire register of data from the pages of numerous sites is ranked according to certain parameters: region, relevance to the request, resource popularity, content quality and so on. As I already said, we will analyze the entire list of ranking factors in a separate publication. The main task when promoting a site is to influence these factors in order to raise the site to the TOP.
Features and characteristics of search engines in 2018
We've all seen Google ads about how the search engine gets into an unequal battle with grandma to find the nearest pharmacy. What does this mean? That search engines are learning and will soon completely stop working with keywords and will only work with meanings. Because this is their main task, not to give out an arbitrary list of sites, but to help the user find a place, product or service.
In our country, the share of voice search is still very small, but in the USA it takes up about 50% of mobile traffic. This means that this trend will soon affect Russia. Accordingly, the number of information requests will increase ( how, where, where) and requests that cannot be predicted, because they will not be stereotyped and dictated by the situation in which the person finds himself. For example, he stands at an intersection and asks where I should turn to find a cafe where there are business opportunities worth up to 300 rubles. This is Google.
As for Yandex, which was also introduced at the end of 2016. This is an algorithm that will also work primarily with meanings.
Which search engine is better or how does Yandex differ from Google?
From my personal experience, I can say that both search engines are good in their own ways. The difference, of course, is that Yandex is a Russian search engine, and Google is the world's largest search engine. Of course, we are not interested in the external differences between the sites of these search engines and the services they provide, but in how they generate search results, since they differ very much.
Yandex pays more attention to regional search. That is, if you are in Vladivostok and enter a query without specifying a city or region, for example, “windows”, first of all Yandex will show the websites of those companies that are located in Vladivostok and are somehow connected with windows.
For Google, the popularity and citation of a resource (not just links to your site) are more important; based on this, it concludes whether your site is useful.
As for other search engines, then mail.ru is a shell of Google search results, i.e. mail.ru itself does not analyze anything, but simply shows what Google would show. Rambler.ru By the same principle, it is a Yandex shell.
By definition, an Internet search engine is an information retrieval system that helps us find information on the World Wide Web. This facilitates the global exchange of information. But the Internet is an unstructured database. It is growing exponentially and has become a huge repository of information. Finding information on the Internet is a difficult task. There is a need to have a tool to manage, filter and retrieve this ocean information. The search engine serves this purpose.
How does a search engine work?
Internet search engines are engines that search and retrieve information on the Internet. Most of them use a crawler indexer architecture. They depend on their track modules. Crawlers, also called spiders, are small programs that crawl web pages.
Crawlers visit an initial set of URLs. They mine URLs that appear on crawled pages and send this information to the crawler control module. The crawler decides which pages to visit next and gives those URLs to the crawlers.
The topics covered by different search engines vary depending on the algorithms they use. Some search engines are programmed to search sites on a specific topic, while others' crawlers may visit as many places as possible.
The indexing module extracts information from each page it visits and enters the URL into the database. This results in a huge lookup table with a list of URLs pointing to pages of information. The table shows the pages that were covered during the crawl.
The analysis module is another important part of the search engine architecture. It creates a utility index. The index utility can provide access to pages of a given length or pages containing a certain number of pictures on them.
During the crawling and indexing process, the search engine stores the pages it retrieves. They are temporarily stored in page storage. Search engines maintain a cache of the pages they visit to speed up the retrieval of pages that have already been visited.
The search engine query module receives search queries from users in the form of keywords. The ranking module sorts the results.
The crawler indexer architecture has many variations. They change in a distributed search engine architecture. These architectures consist of collectors and brokers. Collectors collect indexing information from web servers while brokers provide the indexing engine and query interface. Brokers index the update based on information received from collectors and other brokers. They can filter information. Many search engines today use this type of architecture.
Search engines and page ranking
When we create a query in a search engine, the results are displayed in a certain order. Most of us tend to visit the top pages and ignore the bottom ones. This is because we believe that the top few pages are more relevant to our query. So everyone is interested in having their pages rank in the top ten search engine results.
The words listed in the search engine query interface are the keywords that were requested in the search engines. They are a list of pages related to the requested keywords. During this process, search engines retrieve those pages that have frequent occurrences of these keywords. They look for relationships between keywords. The placement of keywords also counts, as does the ranking of the pages containing them. Keywords that appear in page titles or URLs are given more weight. Pages that have links pointing to them make them even more popular. If many other sites link to a page, it is seen as valuable and more relevant.
There is a ranking algorithm that every search engine uses. The algorithm is a computerized formula designed to provide relevant pages to a user's request. Each search engine may have a different ranking algorithm that analyzes pages in the engine's database to determine relevant responses to search queries. Search engines index different information differently. This means that a given query posed to two different search engines may return pages in different orders or retrieve different pages. The popularity of a website are factors that determine relevance. Click-through popularity of a site is another factor that determines its rank. This is a measure of how often a site is visited.
Webmasters try to trick search engine algorithms in order to increase the ranking of their site in search results. Stuffing website pages with keywords or using meta tags to cheat search engine ranking strategies. But search engines are smart enough! They are improving their algorithms so that the machinations of webmasters do not affect search results.
You need to understand that even the pages after the first few in the list may contain exactly the information you were looking for. But rest assured that good search engines will always bring you highly relevant pages in the top order!
In order to promote a website, you need to understand how search engines work and what you need to do to get into the search positions for keywords.
What are search engines and what are their tasks?
Search engines are computer robots that provide visitors with the most relevant and useful information for their queries.
The more correct the answer a search engine gives, the higher the level of trust Internet users have in it.
This is important for the system itself because it benefits from this in the form of profit for placements, which is visible to everyone who uses it.
In order to provide the correct answers, thereby increasing the number, search engines work according to a certain principle, which consists in collecting data about constantly appearing sites and indexing their pages.
How search engines work
 Many Internet users believe that search engines provide them with information about all the sites that exist. But in fact, this is completely wrong, because they only focus on those pages that are in the search engine database. If the site is not in search engines, then neither Google nor Yandex will show it up in searches.
Many Internet users believe that search engines provide them with information about all the sites that exist. But in fact, this is completely wrong, because they only focus on those pages that are in the search engine database. If the site is not in search engines, then neither Google nor Yandex will show it up in searches.
When a site appears in the database, search engine robots scan it, identifying all internal pages, as well as links posted on this Internet portal. Thus, complete information is collected both about a specific site and other resources that it popularizes.
The process of capturing and systematizing information occurs through. In some cases, this does not happen for quite a long time, so it is necessary to understand what this search engine function is and how it works.
Read ours about the role of correct text formatting on a website.
Results
In order to promote a website, you need to take into account all aspects of the work of popular search engines, adjusting the indicators of your Internet resource to the requirements of these systems. If everything is done in accordance with the rules established by Google and Yandex, you will soon be able to see your site in the first positions in keyword searches.
Sincerely, Nastya ChekhovaA search system is a software and hardware complex designed to search the Internet and respond to a user request, specified in the form of a text phrase (search query), by producing a list of links to sources of information, in order of relevance (in accordance with the request). The largest international search engines: "Google", "Yahoo", "MSN". On the Russian Internet it is - "Yandex", "Rambler", "Aport".
Let us describe the main characteristics of search engines:
Completeness
Completeness is one of the main characteristics of a search system, which is the ratio of the number of documents found by request to the total number of documents on the Internet that satisfy the given request. For example, if there are 100 pages on the Internet containing the phrase “how to choose a car,” and only 60 of them were found for the corresponding query, then the completeness of the search will be 0.6. Obviously, the more complete the search, the less likely it is that the user will not find the document he needs, provided that it exists on the Internet at all.
Accuracy
Accuracy is another main characteristic of a search engine, which is determined by the degree to which the found documents match the user's query. For example, if the query “how to choose a car” contains 100 documents, 50 of them contain the phrase “how to choose a car”, and the rest simply contain these words (“how to choose the right radio and install it in a car”), then the search accuracy is considered equal to 50/100 (=0.5). The more accurate the search, the faster the user will find the documents he needs, the less various kinds of “garbage” will be found among them, the less often the found documents will not correspond to the request.
Relevance
Relevance is an equally important component of search, which is characterized by the time that passes from the moment documents are published on the Internet until they are entered into the search engine index database. For example, the day after interesting news appeared, a large number of users turned to search engines with relevant queries. Objectively, less than a day has passed since the publication of news information on this topic, but the main documents have already been indexed and available for search, thanks to the existence of the so-called “fast database” of large search engines, which is updated several times a day.
Search speed
Search speed is closely related to its load resistance. For example, according to Rambler Internet Holding LLC, today, during business hours, the Rambler search engine receives about 60 requests per second. Such workload requires reducing the processing time of an individual request. Here the interests of the user and the search engine coincide: the visitor wants to get results as quickly as possible, and the search engine must process the request as quickly as possible, so as not to slow down the calculation of subsequent queries.
Visibility
Visual presentation of results is an important component of convenient search. For most queries, the search engine finds hundreds, or even thousands, of documents. Due to unclear queries or inaccurate searches, even the first pages of search results do not always contain only the necessary information. This means that the user often has to perform his own search within the found list. Various elements of the search engine results page help you navigate the search results. Detailed explanations of the search results page, for example for Yandex, can be found at the link http://help.yandex.ru/search/?id=481937.
4. Brief history of the development of search engines
In the initial period of Internet development, the number of its users was small, and the amount of available information was relatively small. For the most part, only research staff had access to the Internet. At this time, the task of searching for information on the Internet was not as urgent as it is now.
One of the first ways to organize access to network information resources was the creation of open directories of sites, links to resources in which were grouped according to topic. The first such project was the Yahoo.com website, which opened in the spring of 1994. After the number of sites in the Yahoo directory increased significantly, the ability to search for the necessary information in the directory was added. In the full sense, it was not yet a search engine, since the search area was limited only to the resources present in the catalog, and not to all Internet resources.
Link directories were widely used in the past, but have almost completely lost their popularity nowadays. Since even modern catalogs, huge in volume, contain information only about a negligible part of the Internet. The largest directory of the DMOZ network (also called the Open Directory Project) contains information about 5 million resources, while the Google search engine database consists of more than 8 billion documents.
The first full-fledged search engine was the WebCrawler project, published in 1994.
In 1995, search engines Lycos and AltaVista appeared. The latter has been a leader in the field of information search on the Internet for many years.
In 1997, Sergey Brin and Larry Page created the Google search engine as part of a research project at Stanford University. Google is currently the most popular search engine in the world!
In September 1997, the Yandex search engine, which is the most popular on the Russian-language Internet, was officially announced.
Currently, there are three main international search engines - Google, Yahoo and MSN, which have their own databases and search algorithms. Most other search engines (of which there are a large number) use in one form or another the results of the three listed. For example, AOL search (search.aol.com) uses the Google database, while AltaVista, Lycos and AllTheWeb use the Yahoo database.
5. Composition and principles of operation of the search system
In Russia, the main search engine is Yandex, followed by Rambler.ru, Google.ru, Aport.ru, Mail.ru. Moreover, at the moment, Mail.ru uses the Yandex search engine and database.
Almost all major search engines have their own structure, different from others. However, it is possible to identify the main components common to all search engines. Differences in structure can only be in the form of implementation of the mechanisms of interaction of these components.
Indexing module
The indexing module consists of three auxiliary programs (robots):
Spider is a program designed to download web pages. The spider downloads the page and retrieves all internal links from that page. The html code of each page is downloaded. Robots use HTTP protocols to download pages. The spider works as follows. The robot sends the request “get/path/document” and some other HTTP request commands to the server. In response, the robot receives a text stream containing service information and the document itself.
Page URL
date the page was downloaded
Server response http header
page body (html code)
Crawler (“traveling” spider) is a program that automatically follows all the links found on the page. Selects all links present on the page. Its job is to determine where the spider should go next, based on links or based on a predetermined list of addresses. Crawler, following the links found, searches for new documents that are still unknown to the search engine.
Indexer (robot indexer) is a program that analyzes web pages downloaded by spiders. The indexer parses the page into its component parts and analyzes them using its own lexical and morphological algorithms. Various page elements are analyzed, such as text, headings, links, structural and style features, special service HTML tags, etc.
Thus, the indexing module allows you to crawl a given set of resources using links, download encountered pages, extract links to new pages from received documents, and perform a complete analysis of these documents.
Database
A database, or search engine index, is a data storage system, an information array in which specially converted parameters of all documents downloaded and processed by the indexing module are stored.
Search server
The search server is the most important element of the entire system, since the quality and speed of the search directly depend on the algorithms that underlie its functioning.
The search server works as follows:
The request received from the user is subjected to morphological analysis. The information environment of each document contained in the database is generated (which will subsequently be displayed in the form of a snippet, that is, text information corresponding to the request on the search results page).
The received data is passed as input parameters to a special ranking module. Data is processed for all documents, as a result of which each document has its own rating that characterizes the relevance of the query entered by the user and the various components of this document stored in the search engine index.
Depending on the user’s choice, this rating can be adjusted by additional conditions (for example, the so-called “advanced search”).
Next, a snippet is generated, that is, for each document found, the title, a short abstract that best matches the query, and a link to the document itself are extracted from the document table, and the words found are highlighted.
The resulting search results are transmitted to the user in the form of a SERP (Search Engine Result Page) – a search results page.
As you can see, all these components are closely related to each other and work in interaction, forming a clear, rather complex mechanism for the operation of the search system, which requires huge amounts of resources.
No search engine covers all Internet resources.
Each search engine collects information about Internet resources using its own unique methods and forms its own periodically updated database. Access to this database is granted to the user.
Search engines implement two ways to search for a resource:
Search by topic catalogs - information is presented in the form of a hierarchical structure. At the top level there are general categories (“Internet”, “Business”, “Art”, “Education”, etc.), at the next level the categories are divided into sections, etc. The lowest level is links to specific web pages or other information resources.
Keyword search (index search or detailed search) - the user sends to the search engine request, consisting of keywords. System returns to the user a list of resources found upon request.
Most search engines combine both search methods.
Search engines can be local, global, regional and specialized.
In the Russian part of the Internet (Runet), the most popular general purpose search engines are Rambler (www.rambler.ru), Yandex (www.yandex.ru), Aport (www.aport.ru), Google (www.google.ru).
Most search enginesimplemented in the form of portals.
Portal (from English.portal- main entrance, gate) is a website that integrates various Internet services: search tools, mail, news, dictionaries, etc.
Portals can be specialized (like,www. museum. ru) and general (for example,www. km. ru).
Search by keywords
The set of keywords used to search is also called the search criterion or search topic.
A request can consist of either one word or a combination of words combined by operators - symbols by which the system determines what action it needs to perform. For example: the request “Moscow St. Petersburg” contains the AND operator (this is how a space is perceived), which indicates that one should search for documents that contain both words - Moscow and St. Petersburg.
In order for the search to be relevant (from the English relevant - relevant, relevant), several general rules should be taken into account:
Regardless of the form in which the word is used in the query, the search takes into account all its word forms according to the rules of the Russian language. For example, the query “ticket” will also find the words “ticket”, “ticket”, etc.
Capital letters should only be used in proper names to avoid viewing unnecessary references. At the request of “blacksmiths,” for example, documents will be found that talk about both blacksmiths and Kuznetsovs.
It is advisable to narrow your search using a few keywords.
If the required address is not among the first twenty addresses found, you should change the request.
Each search engine uses its own query language. To get acquainted with it, use the built-in help of the search engine
Large sites may have built-in information retrieval systems within their web pages.
Queries in such search systems, as a rule, are built according to the same rules as in global search engines, however, familiarity with the help here will not be superfluous.
Advanced Search
Search engines can provide a mechanism for the user to create a complex query. Follow the link Advanced Search makes it possible to edit search parameters, specify additional parameters and select the most convenient form for displaying search results. The following describes the parameters that can be specified during an advanced search in the Yanex and Rambler systems.
Parameter description
Name in Yandex
Name inRambler
Where to look for keywords (document title, body text, etc.)
Dictionary filter
Search by text...
What words should or should not be present in the document and how accurate the match should be
Dictionary filter
Search for query words... Exclude documents containing the following words...
How far apart should keywords be located?
Dictionary filter
Distance between query words...
Restriction on document date
Document date...
Limit your search to one or more sites
Site/Top
Search documents only on the following sites...
Limiting search by document language
Document language...
Search for documents containing a picture with a specific name or signature
Image
Finding pages that contain objects
Special objects
Search results presentation form
Issue format
Displaying search results
Some search engines (for example, Yandex) allow you to enter queries in natural language. You write what you need to find (for example: ordering train tickets from Moscow to St. Petersburg). The system analyzes the request and produces the result. If you are not satisfied with it, switch to the query language.
Why does a marketer need to know the basic principles of search engine optimization? It's simple: organic traffic is an excellent source of incoming traffic from the target audience for your corporate website and even landing pages.
Meet a series of educational posts on the topic of SEO.
What is a search engine?
A search engine is a large database of documents (content). Search robots crawl resources and index different types of content, and it is these saved documents that are ranked in search.
In fact, Yandex is a “snapshot” of the Runet (also Turkey and a few English-language sites), and Google is the global Internet.
A search index is a data structure containing information about documents and the location of keywords in them.
According to the operating principle, search engines are similar to each other; the differences lie in the ranking formulas (ordering sites in search results), which are based on machine learning.
Every day, millions of users submit queries to search engines.
“Write an abstract”:
"Buy":
But most of all they are interested...
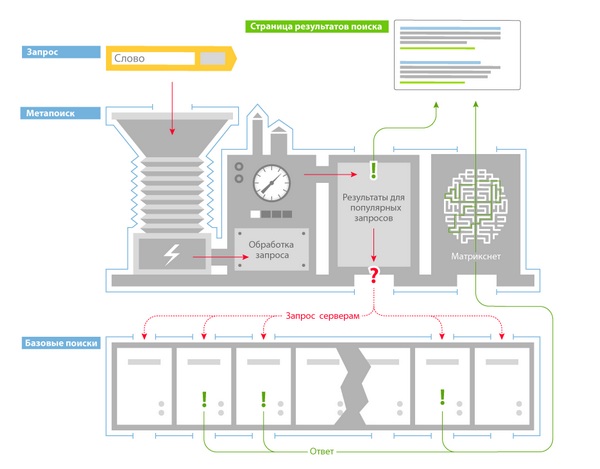
How does a search engine work?
To provide users with quick answers, the search architecture was divided into 2 parts:
- basic search,
- metasearch.
Basic search
Basic search is a program that searches its part of the index and provides all documents that match the query.
Metasearch is a program that processes a search query, determines the user's regionality, and if the query is popular, it produces a ready-made search option, and if the query is new, it selects a basic search and issues a command to select documents, then using machine learning it ranks the found documents and provides to the user.
Classification of search queries
To give a relevant answer to the user, the search engine first tries to understand what exactly he needs. The search query is analyzed and the user is analyzed in parallel.
Search queries are analyzed according to the following parameters:
- Length;
- definition;
- popularity;
- competitiveness;
- syntax;
- geography.
Request type:
- navigation;
- informational;
- transactional;
- multimedia;
- general;
- official
After parsing and classifying the request, a ranking function is selected.
The designation of query types is confidential information and the proposed options are the guesswork of search engine optimization specialists.
If a user asks a general query, the search engine returns different types of documents. And you should understand that by promoting the commercial page of the site in the TOP 10 for a general request, you are applying not to get into one of the 10 places, but into the number of places
for commercial pages, which is highlighted by the ranking formula. And therefore, the likelihood of ranking in the top for such queries is lower.Machine learning MatrixNet is an algorithm introduced in 2009 by Yandex, which selects a function for ranking documents for certain queries.
MatrixNet is used not only in Yandex search, but also for scientific purposes. For example, at the European Nuclear Research Center it is used for rare events in large volumes of data (they are looking for the Higgs boson).
The primary data to evaluate the effectiveness of the ranking formula is collected by the assessor department. These are specially trained people who evaluate a sample of sites using an experimental formula according to the following criteria.
Site quality assessment
Vital - official website (Sberbank, LPgenerator). The search query corresponds to the official website, groups on social networks, information on authoritative resources.
Useful (rated 5) - a site that provides extensive information upon request.
Example - request: banner fabric.
A site that is rated “useful” must contain the following information:
- what is banner fabric;
- technical specifications;
- photos;
- species;
- price list;
- something else.
Examples of queries in the top:
Relevant+ (score 4) – This score means the page is relevant to the search query.
Relevant - (score 3) - The page does not exactly match the search query.
Let’s say the query “Guardians of the Galaxy sessions” displays a page about a movie without sessions, a page of a past session, or a trailer page on YouTube.
Irrelevant (score 2) - the page does not match the request.
Example: the name of the hotel displays the name of another hotel.To promote a resource for a general or informational request, you need to create a page that corresponds to the “useful” rating.
For clear queries, a “relevant+” rating is sufficient.
Relevance is achieved through textual and link correspondence of the page to search queries.
Conclusions
- Not all queries can be promoted to a commercial landing page;
- Not all information requests can be used to promote a commercial website;
- When promoting a general request, create a useful page.
A common reason why a site does not rank in the top is that the content of the promoted page does not match the search query.
We’ll talk about this in the next article, “Checklist for basic website optimization.”