Bygge en ikke-lineær regresjonsmodell i Excel. Regresjon i Excel
Regresjonslinjen er en grafisk refleksjon av forholdet mellom fenomener. Du kan veldig tydelig konstruere en regresjonslinje i Excel-program.
For å gjøre dette trenger du:
1. Åpne Excel
2. Lag datakolonner. I vårt eksempel vil vi bygge en regresjonslinje, eller forhold, mellom aggressivitet og selvtvil hos førsteklassinger. 30 barn deltok i eksperimentet, dataene er presentert i Excel-tabellen:
1 kolonne - emnenummer
2 kolonne - aggressivitet i poeng
3 kolonner - selvtillit i poeng

3.Deretter må du velge begge kolonnene (uten kolonnenavnet), klikk på fanen sette inn , velge flekk , og velg den aller første fra de foreslåtte layoutene prikk med markører .

4. Så vi har en mal for regresjonslinjen - den såkalte - spredningsplott. For å gå til regresjonslinjen, klikk på den resulterende figuren og trykk på tab konstruktør, finner på panelet diagramoppsett og velg M EN ket9 , står det også f(x)

5. Så vi har en regresjonslinje. Grafen viser også ligningen og kvadratet på korrelasjonskoeffisienten

6. Det gjenstår bare å legge til navnet på grafen og navnet på aksene. Også, hvis ønskelig, kan du fjerne legenden, redusere antallet horisontale linjer rutenett (tab layout , da nett ). Grunnleggende endringer og innstillinger gjøres i fanen Oppsett

Regresjonslinjen ble konstruert i MS Excel. Nå kan du legge det til teksten i arbeidet.
Statistisk databehandling kan også utføres ved hjelp av et tillegg ANALYSEPAKKE(Fig. 62).
Fra de foreslåtte elementene, velg elementet " REGRESJON" og klikk på den med venstre museknapp. Klikk deretter OK.
Et vindu vises som vist i fig. 63.

Analyseverktøy " REGRESJON» brukes til å tilpasse en graf til et sett med observasjoner ved bruk av minste kvadraters metode. Regresjon brukes til å analysere virkningen på en individuell avhengig verdivariabel en eller flere uavhengige variabler. Flere faktorer påvirker for eksempel en idrettsutøvers prestasjoner, inkludert alder, høyde og vekt. Det er mulig å beregne i hvilken grad hver av disse tre faktorene påvirker en utøvers prestasjoner, og deretter bruke disse dataene til å forutsi prestasjonen til en annen utøver.
Regresjonsverktøyet bruker funksjonen LINJEST.
REGRESJON Dialogboks
Etiketter Velg avmerkingsboksen hvis den første raden eller første kolonnen i inndataområdet inneholder overskrifter. Fjern merket for denne boksen hvis det ikke er noen overskrifter. I dette tilfellet passende overskrifter for utdatatabellen vil data bli opprettet automatisk.
Pålitelighetsnivå Velg avmerkingsboksen for å inkludere et ekstra nivå i utdatasammendragstabellen. I det aktuelle feltet angir du konfidensnivået du vil bruke, i tillegg til standardnivået på 95 %.
Konstant - null Velg avmerkingsboksen for å tvinge regresjonslinjen til å gå gjennom origo.
Utgangsintervall Angi lenken til venstre øverste celle utgangsområde. Oppgi minst syv kolonner for utdatasammendragstabellen, som vil inkludere: ANOVA-resultater, koeffisienter, standardfeil for Y-beregningen, standardavvik, antall observasjoner, standardfeil for koeffisienter.
Nytt regneark Sett bryteren til denne posisjonen for å åpne nytt blad i arbeidsboken og lim inn analyseresultatene med start i celle A1. Om nødvendig, skriv inn et navn for det nye arket i feltet på motsatt side av den tilsvarende alternativknappen.
Ny arbeidsbok Sett bryteren til denne posisjonen for å lage en ny arbeidsbok der resultatene vil bli lagt til et nytt ark.
Residualer Merk av i boksen for å inkludere rester i utdatatabellen.
Standardiserte rester Velg avmerkingsboksen for å inkludere standardiserte rester i utdatatabellen.
Residual Plot Velg avmerkingsboksen for å plotte residualene for hver uavhengig variabel.
Tilpass plott Velg avmerkingsboksen for å plotte de anslåtte kontra observerte verdiene.
Normal sannsynlighetsplott Velg avmerkingsboksen for å plotte en normal sannsynlighetsgraf.
Funksjon LINJEST
For å utføre beregninger, velg med markøren cellen der vi ønsker å vise gjennomsnittsverdien og trykk på =-tasten på tastaturet. Angi deretter i Navn-feltet ønsket funksjon, For eksempel GJENNOMSNITTLIG(Fig. 22).
Funksjon LINJEST beregner statistikk for en serie ved å bruke minste kvadrater for å beregne en rett linje som på best mulig måte tilnærmer tilgjengelige data og returnerer deretter en matrise som beskriver den resulterende rette linjen. Du kan også kombinere funksjonen LINJEST med andre funksjoner for å beregne andre typer modeller som er lineære i ukjente parametere (hvis ukjente parametere er lineære), inkludert polynomiske, logaritmiske, eksponentielle og potensserier. Fordi en matrise med verdier returneres, må funksjonen spesifiseres som en matriseformel.
Ligningen for en rett linje er:
y=m 1 x 1 +m 2 x 2 +...+b (i tilfelle av flere områder med x-verdier),
der den avhengige verdien y er en funksjon av den uavhengige verdien x, er m-verdiene koeffisientene som tilsvarer hver uavhengig variabel x, og b er en konstant. Merk at y, x og m kan være vektorer. Funksjon LINJEST returnerer array(mn;mn-1;…;m 1 ;b). LINJEST kan også returnere ytterligere regresjonsstatistikk.
LINJEST(kjente_verdier_y; kjente_verdier_x; konst; statistikk)
Known_y_values - et sett med y-verdier som allerede er kjent for forholdet y=mx+b.
Hvis arrayen kjente_y_verdier har én kolonne, behandles hver kolonne i matrisen kjente_xverdier som en separat variabel.
Hvis kjente_y_verdier-matrisen har én rad, behandles hver rad i kjente_x_verdier-matrisen som en separat variabel.
Known_x-values er et valgfritt sett med x-verdier som allerede er kjent for forholdet y=mx+b.
Matrisen kjente_x_verdier kan inneholde ett eller flere sett med variabler. Hvis bare én variabel brukes, kan arrayene kjente_y_verdier og kjente_x_verdier ha hvilken som helst form - så lenge de har samme dimensjon. Hvis mer enn én variabel brukes, må kjente_y_verdier være en vektor (det vil si et intervall som er én rad høyt eller én kolonne bred).
Hvis array_known_x_values er utelatt, antas arrayen (1;2;3;...) å ha samme størrelse som array_known_values_y.
Const er en boolsk verdi som spesifiserer om konstanten b må være lik 0.
Hvis argumentet "const" er SANN eller utelatt, blir konstanten b evaluert som vanlig.
Hvis "const"-argumentet er FALSE, settes verdien av b til 0 og verdiene til m velges på en slik måte at forholdet y=mx er tilfredsstilt.
Statistikk – En boolsk verdi som spesifiserer om ytterligere regresjonsstatistikk skal returneres.
Hvis statistikken er TRUE, returnerer LINEST ytterligere regresjonsstatistikk. Den returnerte matrisen vil se slik ut: (mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid).
Hvis statistikk er FALSE eller utelatt, returnerer LINJE bare koeffisientene m og konstanten b.
Ytterligere regresjonsstatistikk.(Tabell 17)
| Størrelse | Beskrivelse |
| se1,se2,...,sen | Standard feilverdier for koeffisientene m1,m2,...,mn. |
| seb | Standardverdi feil for konstant b (seb = #N/A hvis "const"-argumentet er FALSE). |
| r2 | Koeffisient for determinisme. De faktiske verdiene til y og verdiene oppnådd fra linjens ligning sammenlignes; Basert på sammenligningsresultatene beregnes determinismekoeffisienten, normalisert fra 0 til 1. Hvis den er lik 1, er det en fullstendig korrelasjon med modellen, det vil si at det ikke er noen forskjell mellom de faktiske og estimerte verdiene av y. I motsatt tilfelle, hvis bestemmelseskoeffisienten er 0, er det ingen vits i å bruke regresjonsligningen for å forutsi verdiene til y. For mer informasjon om hvordan du beregner r2, se "Notater" på slutten denne delen. |
| sey | Standard feilå anslå y. |
| F | F-statistikk eller F-observert verdi. F-statistikken brukes til å bestemme om en observert sammenheng mellom en avhengig og uavhengig variabel skyldes tilfeldigheter. |
| df | Frihetsgrader. Frihetsgrader er nyttige for å finne F-kritiske verdier i den statistiske tabellen. For å bestemme konfidensnivået til modellen, sammenligner du verdiene i tabellen med F-statistikken returnert av LINJE-funksjonen. For mer informasjon om beregning av df, se "Notater" på slutten av denne delen. Deretter viser eksempel 4 bruken av F- og df-verdier. |
| ssreg | Regresjonssum av kvadrater. |
| ssresid | Restsum av kvadrater. For mer informasjon om beregning av ssreg og ssresid, se "Notater" på slutten av denne delen. |
Figuren under viser rekkefølgen som ekstra regresjonsstatistikk returneres i (Figur 64).

Merknader:
Enhver rett linje kan beskrives ved sin helning og skjæringspunkt med y-aksen:
Helning (m): For å bestemme helningen til en linje, vanligvis betegnet med m, må du ta to punkter på linjen (x 1 ,y 1) og (x 2 ,y 2); helningen vil være lik (y 2 -y 1)/(x 2 -x 1).
Y-skjæringspunkt (b): Y-skjæringspunktet til en linje, vanligvis betegnet b, er y-verdien for punktet der linjen skjærer y-aksen.
Ligningen til den rette linjen er y=mx+b. Hvis verdiene til m og b er kjent, kan et hvilket som helst punkt på linjen beregnes ved å erstatte verdiene til y eller x i ligningen. Du kan også bruke TREND-funksjonen.
Hvis det bare er én uavhengig variabel x, kan du få helningen og y-skjæringspunktet direkte ved å bruke følgende formler:
Helning: INDEX(LINEST(kjente_y_verdier; kjente_x_verdier); 1)
Y-skjæringspunkt: INDEX(LINEST(kjente_y_verdier; kjente_x_verdier); 2)
Nøyaktigheten til tilnærmingen ved å bruke den rette linjen beregnet av LINJE-funksjonen avhenger av graden av dataspredning. Jo nærmere dataene er en rett linje, desto mer nøyaktig er modellen som brukes av LINJEST-funksjonen. LINJE-funksjonen bruker minste kvadrater for å finne den beste tilpasningen til dataene. Når det bare er én uavhengig variabel, beregnes x, m og b ved å bruke følgende formler:

hvor x og y er eksempelmidler, for eksempel x = AVERAGE(kjente_x-er) og y = AVERAGE(kjente_y-er).
Tilpasningsfunksjonene LINEST og LGRFPRIBL kan beregne den rette linjen eller eksponentiell kurve som passer best til dataene. De svarer imidlertid ikke på spørsmålet om hvilket av de to resultatene som er mer egnet for å løse problemet. Du kan også evaluere funksjonen TREND(kjente_y_verdier; kjente_xverdier) for en rett linje eller funksjonen GROWTH(kjent_y_verdier; kjente_xverdier) for en eksponentiell kurve. Disse funksjonene, med mindre new_x-verdier er spesifisert, returnerer en rekke beregnede y-verdier for de faktiske x-verdiene langs en linje eller kurve. Du kan deretter sammenligne de beregnede verdiene med de faktiske verdiene. Du kan også lage diagrammer for visuell sammenligning.
Dirigering regresjonsanalyse, Microsoft Excel beregner for hvert punkt kvadratet av differansen mellom den anslåtte y-verdien og den faktiske y-verdien. Summen av disse kvadratiske forskjellene kalles restsummen av kvadrater (ssresid). Microsoft Excel beregner deretter den totale summen av kvadrater (sstotal). Hvis const = TRUE eller verdien av dette argumentet ikke er spesifisert, totalt beløp kvadrater vil være lik summen av kvadratene av forskjellene mellom de reelle verdiene av y og gjennomsnittsverdiene til y. Når const = FALSE, vil totalsummen av kvadrater være lik summen av kvadrater av de reelle y-verdiene (uten å trekke den gjennomsnittlige y-verdien fra den delvise y-verdien). Regresjonssummen av kvadrater kan da beregnes som følger: ssreg = sstotal - ssresid. Jo mindre restsummen av kvadrater, desto større er verdien av bestemmelseskoeffisienten r2, som viser hvor godt ligningen oppnådd ved bruk av regresjonsanalyse forklarer sammenhengene mellom variabler. Koeffisienten r2 er lik ssreg/sstotal.
I noen tilfeller har en eller flere X-kolonner (la Y- og X-verdiene være i kolonner) ingen ekstra predikativ verdi i andre X-kolonner. Med andre ord kan fjerning av en eller flere X-kolonner resultere i at Y-verdier beregnes med samme presisjon. I dette tilfellet vil de redundante X-kolonnene bli ekskludert fra regresjonsmodellen. Dette fenomenet kalles "kollinearitet" fordi de overflødige kolonnene til X kan representeres som summen av flere ikke-redundante kolonner. LINJE-funksjonen sjekker for kollinearitet og fjerner eventuelle redundante X-kolonner fra regresjonsmodellen hvis den oppdager dem. Fjernede X-kolonner kan identifiseres i LINEST-utdata med en faktor 0 og en se-verdi på 0. Fjerning av én eller flere kolonner som overflødige endrer verdien av df fordi den avhenger av antallet X-kolonner som faktisk brukes til prediktive formål. For mer informasjon om beregning av df, se eksempel 4 nedenfor. Når df endres på grunn av fjerning av overflødige kolonner, endres også verdiene til sey og F. Det anbefales ikke å bruke collinearity ofte. Den bør imidlertid brukes hvis noen X-kolonner inneholder 0 eller 1 som en indikator som indikerer om emnet for forsøket er inkludert i egen gruppe. Hvis const = TRUE eller en verdi for dette argumentet ikke er spesifisert, setter LINEST inn en ekstra X-kolonne for å modellere skjæringspunktet. Hvis det er en kolonne med verdier på 1 for menn og 0 for kvinner, og det er en kolonne med verdier på 1 for kvinner og 0 for menn, fjernes den siste kolonnen fordi verdiene kan oppnås fra kolonnen "mannlig indikator".
Beregningen av df for tilfeller der X kolonner ikke er fjernet fra modellen på grunn av kollinearitet skjer som følger: hvis det er k kjente_x kolonner og verdien const = TRUE eller ikke spesifisert, så er df = n – k – 1. Hvis const = FALSE, da df = n - k. I begge tilfeller øker df-verdien med 1 hvis du fjerner X-kolonnene på grunn av kollinearitet.
Formler som returnerer matriser må angis som matriseformler.
Når du legger inn en matrise med konstanter som et argument, for eksempel kjente_x_verdier, bør du bruke semikolon for å skille verdier på samme linje og et kolon for å skille linjer. Skilletegnene kan variere avhengig av innstillingene i Språk og innstillinger-vinduet i Kontrollpanel.
Det skal bemerkes at y-verdiene forutsagt av regresjonsligningen kanskje ikke er korrekte hvis de faller utenfor området til y-verdiene som ble brukt til å definere ligningen.
Grunnleggende algoritme brukt i funksjonen LINJEST, skiller seg fra hovedfunksjonsalgoritmen HELLING Og KUTT. Forskjellen mellom algoritmer kan føre til ulike resultater med usikre og kollineære data. For eksempel, hvis kjente_y_values-argumentdatapunktene er 0 og kjente_x_values-argumentdatapunktene er 1, så:
Funksjon LINJEST returnerer en verdi lik 0. Funksjonsalgoritme LINJEST brukes til å returnere passende verdier for kollineære data, og i i dette tilfellet minst ett svar kan bli funnet.
Funksjonene SLOPE og LINE returnerer #DIV/0! Algoritmen til SLOPE- og INTERCEPT-funksjonene brukes til å finne bare ett svar, men i dette tilfellet kan det være flere.
I tillegg til å beregne statistikk for andre typer regresjon, kan LINJE brukes til å beregne områder for andre typer regresjon ved å legge inn funksjoner til x- og y-variablene som serier av x- og y-variablene for LINJE. For eksempel følgende formel:
LINJE(y_verdier, x_verdier^KOLUMNE($A:$C))
fungerer ved å ha en kolonne med Y-verdier og en kolonne med X-verdier for å beregne en terningtilnærming (3. grads polynom) av følgende form:
y=m 1 x+m 2 x 2 +m 3 x 3 +b
Formelen kan endres for å beregne andre typer regresjon, men i noen tilfeller er justeringer av utgangsverdiene og annen statistikk nødvendig.
Etter min mening, som student, er økonometri en av de mest anvendte vitenskapene jeg var i stand til å bli kjent med innenfor murene til universitetet mitt. Med dens hjelp er det faktisk mulig å løse anvendte problemer i bedriftsskala. Hvor effektive disse beslutningene vil være, er det tredje spørsmålet. Poenget er at det meste av kunnskapen vil forbli teori, men økonometri og regresjonsanalyse er fortsatt verdt å studere med spesiell oppmerksomhet.
Hva forklarer regresjon?
Før vi begynner å vurdere funksjonene til MS Excel som lar oss løse disse problemene, vil jeg gjerne forklare deg i detalj hva regresjonsanalyse i hovedsak innebærer. Dette vil gjøre det lettere for deg å bestå eksamen, og viktigst av alt, det vil være mer interessant å studere emnet.
Forhåpentligvis er du kjent med konseptet med en funksjon fra matematikk. En funksjon er forholdet mellom to variabler. Når en variabel endres, skjer noe med en annen. Vi endrer X, og Y endres deretter. Funksjoner beskriver ulike lover. Når vi kjenner funksjonen, kan vi erstatte vilkårlige verdier av X og se hvordan Y endres.
Det har den stor verdi, siden regresjon er et forsøk på å forklare bruk spesifikk funksjon tilsynelatende usystematiske og kaotiske prosesser. For eksempel er det mulig å identifisere forholdet mellom dollarkursen og arbeidsledigheten i Russland.
Hvis dette mønsteret kan oppdages, vil vi ved å bruke funksjonen vi fikk under beregningene, kunne lage en prognose for hva arbeidsledigheten vil være ved Nth-dollarkursen mot rubelen.
Dette forholdet vil kalles korrelasjon. Regresjonsanalyse innebærer å beregne en korrelasjonskoeffisient som vil forklare den nære sammenhengen mellom variablene vi vurderer (dollarkursen og antall jobber).
Denne koeffisienten kan være positiv eller negativ. Verdiene varierer fra -1 til 1. Følgelig kan vi observere en høy negativ eller positiv korrelasjon. Hvis det er positivt, vil økningen i dollarkursen bli fulgt av etableringen av nye arbeidsplasser. Hvis den er negativ, betyr det at en økning i valutakursen vil bli fulgt av en nedgang i arbeidsplasser.
Det finnes flere typer regresjon. Det kan være lineært, parabolsk, kraft, eksponentielt, etc. Vi velger en modell avhengig av hvilken regresjon som spesifikt vil tilsvare vårt tilfelle, hvilken modell som vil være så nær korrelasjonen som mulig. La oss se på dette ved å bruke et eksempelproblem og løse det i MS Excel.
Lineær regresjon i MS Excel
For å løse lineære regresjonsproblemer trenger du funksjonaliteten for dataanalyse. Den er kanskje ikke aktivert for deg, så du må aktivere den.
- Klikk på "Fil"-knappen;
- Velg elementet "Alternativer";
- Klikk på den nest siste fanen "Tillegg" på venstre side;
- Nedenfor vil vi se påskriften "Management" og "Go"-knappen. Klikk på den;
- Merk av i boksen for "Analysepakke";
- Klikk "ok".

Eksempeloppgave
Batchanalysefunksjonen er aktivert. La oss løse følgende problem. Vi har et utvalg av data for flere år om antall nødsituasjoner på virksomhetens territorium og antall sysselsatte arbeidere. Vi må identifisere sammenhengen mellom disse to variablene. Det er en forklaringsvariabel X - dette er antall arbeidere og en forklaringsvariabel - Y - dette er antall nødhendelser. La oss fordele kildedataene i to kolonner.

La oss gå til "data"-fanen og velge "Dataanalyse"
I listen som vises, velg "Regresjon". I inngangsintervallene Y og X velger vi de riktige verdiene.

Klikk "Ok". Analysen er ferdig, og vi vil se resultatene i et nytt ark.
De viktigste verdiene for oss er markert i figuren nedenfor.

Multippel R er bestemmelseskoeffisienten. Den har en kompleks beregningsformel og viser hvor mye du kan stole på vår korrelasjonskoeffisient. Følgelig, jo høyere denne verdien er, jo mer tillit, jo mer vellykket vår modell som helhet.
Y-Intercept og X1-Intercept er våre regresjonskoeffisienter. Som allerede nevnt er regresjon en funksjon, og den har visse koeffisienter. Dermed vil funksjonen vår se slik ut: Y = 0,64*X-2,84.
Hva gir dette oss? Dette gir oss muligheten til å lage en prognose. La oss si at vi ønsker å ansette 25 arbeidere til et foretak, og vi må omtrent forestille oss hvor mange nødhendelser vil være. Vi erstatter det med vår funksjon gitt verdi og vi får resultatet Y = 0,64 * 25 – 2,84. Vi vil ha cirka 13 nødsituasjoner.
La oss se hvordan det fungerer. Ta en titt på bildet nedenfor. De faktiske verdiene for de involverte ansatte erstattes med funksjonen vi mottok. Se hvor nær verdiene er ekte spillere.

Du kan også bygge et korrelasjonsfelt ved å velge området til Y-ene og X-ene, klikke på "sett inn"-fanen og velge spredningsplottet.

Prikkene er spredt, men beveger seg vanligvis oppover, som om det er en rett linje i midten. Og du kan også legge til denne linjen ved å gå til "Layout"-fanen i MS Excel og velge "Trend Line"
Dobbeltklikk på linjen som dukker opp og du vil se hva som ble nevnt tidligere. Du kan endre regresjonstypen avhengig av hvordan korrelasjonsfeltet ditt ser ut.
Du kan føle at punktene tegner en parabel i stedet for en rett linje, og at det ville være bedre for deg å velge en annen type regresjon.

Konklusjon
La oss håpe det denne artikkelen ga deg en større forståelse av hva regresjonsanalyse er og hvorfor det er nødvendig. Alt dette er av stor praktisk betydning.
Den lineære regresjonsmetoden lar oss beskrive en rett linje som passer best til en rekke ordnede par (x, y). Ligningen for en rett linje, kjent som lineær ligning, presenteres nedenfor:
ŷ er den forventede verdien av y for en gitt verdi av x,
x er en uavhengig variabel,
a er et segment på y-aksen for en rett linje,
b er helningen til den rette linjen.
Dette konseptet er presentert grafisk i figuren nedenfor:
Figuren over viser linjen beskrevet av ligningen ŷ =2+0,5x. Y-skjæringspunktet er punktet der linjen skjærer y-aksen; i vårt tilfelle er a = 2. Linjens helning, b, forholdet mellom stigningen av linjen og lengden på linjen, har en verdi på 0,5. En positiv helning betyr at linjen stiger fra venstre til høyre. Hvis b = 0, er linjen horisontal, noe som betyr at det ikke er noen sammenheng mellom de avhengige og uavhengige variablene. Med andre ord, endring av verdien av x påvirker ikke verdien av y.
ŷ og y er ofte forvekslet. Grafen viser 6 ordnede par med punkter og en linje, i henhold til den gitte ligningen

Denne figuren viser punktet som tilsvarer det ordnede paret x = 2 og y = 4. Merk at forventet verdi av y i henhold til linjen ved X= 2 er ŷ. Vi kan bekrefte dette med følgende ligning:
ŷ = 2 + 0,5х =2 +0,5(2) =3.
Y-verdien representerer det faktiske punktet og ŷ-verdien er forventet verdi av y ved å bruke en lineær ligning for en gitt verdi av x.
Det neste trinnet er å bestemme den lineære ligningen som passer best med settet med ordnede par, vi snakket om dette i forrige artikkel, hvor vi bestemte ligningstypen ved .
Bruke Excel til å definere lineær regresjon
For å bruke regresjonsanalyseverktøyet innebygd i Excel, må du aktivere tillegget Analysepakke. Du finner den ved å klikke på fanen Fil -> Alternativer(2007+), i dialogboksen som vises AlternativerExcel gå til fanen Tillegg. I feltet Kontroll velge TilleggExcel og klikk Gå. I vinduet som vises, merk av i boksen ved siden av Analysepakke, klikk OK.

I fanen Data i gruppen Analyse vil vises ny knapp Dataanalyse.

For å demonstrere arbeidet med tillegget, vil vi bruke data der en fyr og en jente deler et bord på badet. Skriv inn dataene fra vårt badekareksempel i kolonne A og B på det tomme arket.
Gå til fanen Data, i gruppen Analyse klikk Dataanalyse. I vinduet som vises Dataanalyse velge Regresjon som vist i figuren og klikk OK.

Angi de nødvendige regresjonsparametrene i vinduet Regresjon som vist på bildet:

Klikk OK. Figuren nedenfor viser resultatene som er oppnådd:
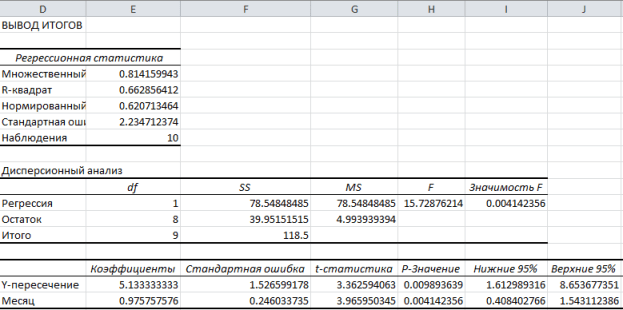
Disse resultatene stemmer overens med de vi oppnådde ved å gjøre våre egne beregninger i .
Dette er den vanligste måten å vise en variabels avhengighet av andre, for eksempel hvordan BNP-nivå fra størrelsen utenlandske investeringer eller fra Nasjonalbankens utlånsrente eller fra priser på viktige energiressurser.
Modellering lar deg vise størrelsen på denne avhengigheten (koeffisienter), takket være at du direkte kan lage en prognose og utføre en slags planlegging basert på disse prognosene. Basert på regresjonsanalyse er det også mulig å ta ledelsesbeslutninger rettet mot å stimulere prioriterte årsaker som påvirker det endelige resultatet, vil selve modellen bidra til å identifisere disse prioriterte faktorene.
Generell oversikt over den lineære regresjonsmodellen:
Y=a 0 +a 1 x 1 +...+a k x k
Hvor en - regresjonsparametere (koeffisienter), x - påvirkningsfaktorer, k - antall modellfaktorer.
Innledende data
Blant de første dataene trenger vi et visst sett med data som vil representere flere påfølgende eller sammenkoblede verdier av den endelige parameteren Y (for eksempel BNP) og det samme antall verdier av indikatorene hvis innflytelse vi studerer ( for eksempel utenlandske investeringer).
Figuren ovenfor viser en tabell med de samme startdataene Y er en indikator på den økonomisk aktive befolkningen, og antall foretak, mengden av investeringer i kapital og husholdningsinntekter er påvirkningsfaktorer, det vil si X-er.
Basert på figuren kan man også trekke en feilaktig konklusjon om at modellering kun kan dreie seg om tidsserier, det vil si momentserier registrert sekvensielt i tid, men dette er ikke slik med samme suksess, man kan modellere i sammenheng med en struktur, for eksempel kan verdiene som er angitt i tabellen brytes ned ikke etter år, men etter region.
Å bygge tilstrekkelig lineære modeller Det er ønskelig at kildedataene ikke har sterke fall eller kollapser i slike tilfeller, det er lurt å utføre utjevning, men vi snakker om utjevning neste gang.
Analysepakke
Parametrene til en lineær regresjonsmodell kan også beregnes manuelt ved hjelp av Ordinary Least Squares Method (OLS), men dette er ganske tidkrevende. Dette kan regnes ut litt raskere med samme metode ved å bruke formler i Excel, hvor programmet selv skal gjøre beregningene, men du må likevel legge inn formlene manuelt.
Excel har et tillegg Analysepakke som er pent kraftig verktøy for å hjelpe analytikeren. Dette verktøysettet kan blant annet beregne regresjonsparametere ved å bruke den samme minste kvadraters metode, med bare noen få klikk. Faktisk, hvordan du bruker dette verktøyet vil bli diskutert videre.
Aktiver analysepakken
Som standard er dette tillegget deaktivert, og du finner det ikke i fanemenyen, så vi tar en trinnvis titt på hvordan du aktiverer den.

I Excel, øverst til venstre, aktiver fanen Fil, i menyen som åpnes, se etter elementet Alternativer og klikk på den.

I vinduet som åpnes, til venstre, se etter elementet Tillegg og aktiver den, i denne fanen nederst vil det være en rullegardinkontrollliste, hvor det som standard vil bli skrevet Excel-tillegg , vil det være en knapp til høyre for rullegardinlisten Gå, må du klikke på den.

Et popup-vindu vil be deg om å velge tilgjengelige tillegg i det du må merke av i boksen Analysepakke og samtidig, bare i tilfelle, Å finne en løsning(også en nyttig ting), og bekreft deretter valget ditt ved å klikke på knappen OK.
Instruksjoner for å finne lineære regresjonsparametere ved hjelp av analysepakken
Etter aktivering av Analysis Pack-tillegget, vil det alltid være tilgjengelig i hovedmenyfanen Data under lenken Dataanalyse
I det aktive verktøyvinduet Dataanalyse fra listen over muligheter vi søker og velger Regresjon

Deretter åpnes et vindu for å sette opp og velge kildedata for beregning av parametrene til regresjonsmodellen. Her må du angi intervallene for de innledende dataene, nemlig parameteren som beskrives (Y) og faktorene som påvirker den (X), som vist i figuren nedenfor, de resterende parameterne er i prinsippet valgfrie.

Etter at du har valgt kildedata og klikket på OK-knappen, produserer Excel beregninger på et nytt ark i den aktive arbeidsboken (med mindre det er angitt annet i innstillingene), ser disse beregningene slik ut:

Nøkkelcellene er fylt med gult, dette er de du må være oppmerksom på først og fremst de andre parametrene av betydning er også viktige, men deres detaljerte analyse krever sannsynligvis et eget innlegg.
Så, 0,865 - Dette R 2- bestemmelseskoeffisient, som viser at 86,5% av de beregnede parametrene til modellen, det vil si selve modellen, forklarer avhengigheten og endringene i parameteren som studeres - Y fra de studerte faktorene - X-er. Hvis overdrevet, da dette er en indikator på kvaliteten på modellen og jo høyere den er, jo bedre. Det er klart at den ikke kan være mer enn 1 og anses som god når R 2 er over 0,8, og hvis den er mindre enn 0,5, kan man trygt stille spørsmål ved rimeligheten til en slik modell.
La oss nå gå videre til modellkoeffisienter:
2079,85
- Dette en 0- en koeffisient som viser hva Y vil være dersom alle faktorer som brukes i modellen er lik 0, det forstås at dette er en avhengighet av andre faktorer som ikke er beskrevet i modellen;
-0,0056
- en 1- en koeffisient som viser vekten av påvirkningen av faktor x 1 på Y, det vil si at antall foretak innenfor en gitt modell påvirker indikatoren for den økonomisk aktive befolkningen med en vekt på bare -0,0056 (en ganske liten grad av innflytelse ). Minustegnet viser at denne påvirkningen er negativ, det vil si at jo flere bedrifter, jo mindre økonomisk aktive befolkning, uansett hvor paradoksalt dette måtte ha betydning;
-0,0026
- en 2- innflytelseskoeffisient for volumet av investeringer i kapital på størrelsen på den økonomisk aktive befolkningen i henhold til modellen, denne påvirkningen er også negativ;
0,0028
- en 3- innflytelseskoeffisient av befolkningsinntekt på størrelsen på den yrkesaktive befolkningen, her er påvirkningen positiv, det vil si at i følge modellen vil en inntektsøkning bidra til en økning i størrelsen på den yrkesaktive befolkningen.
La oss samle de beregnede koeffisientene inn i modellen:
Y = 2079,85 - 0,0056x 1 - 0,0026x 2 + 0,0028x 3
Faktisk er dette en lineær regresjonsmodell, som for de første dataene som er brukt i eksemplet ser akkurat slik ut.
Modellestimater og prognose
Som vi allerede har diskutert ovenfor, er modellen bygget ikke bare for å vise størrelsen på avhengigheten til parameteren som studeres av påvirkningsfaktorene, men også slik at det, med kjennskap til disse påvirkningsfaktorene, er mulig å lage en prognose. Å lage denne prognosen er ganske enkel, du trenger bare å erstatte verdiene til påvirkningsfaktorene i stedet for de tilsvarende X-ene i den resulterende modellligningen. I figuren under er disse beregningene gjort i Excel i en egen kolonne.

De faktiske verdiene (de som skjedde i virkeligheten) og de beregnede verdiene i henhold til modellen i samme figur vises i form av grafer for å vise forskjellen, og dermed feilen til modellen.
Jeg gjentar nok en gang, for å lage en prognose ved hjelp av en modell, er det nødvendig at det er kjente påvirkningsfaktorer, og hvis vi snakker om en tidsserie og følgelig en prognose for fremtiden, for eksempel for neste år eller måned, så er det ikke alltid mulig å finne ut hva påvirkningsfaktorene vil være i akkurat denne fremtiden. I slike tilfeller er det også nødvendig å lage en prognose for påvirkningsfaktorene som oftest gjøres ved hjelp av en autoregressiv modell - en modell der påvirkningsfaktorene er objektet som studeres, det vil si avhengigheten av indikatoren; etter hva det var i fortiden er modellert.
Vi vil se på hvordan man bygger en autoregressiv modell i neste artikkel, men la oss nå anta at vi vet hva verdiene til påvirkningsfaktorene vil være i den fremtidige perioden (i eksemplet 2008), og ved å erstatte disse verdiene inn i beregningene får vi vår prognose for 2008.