. Do czego służy protokół routingu (IP)? Protokół internetowy zapewnia protokół routingu ip
Stos protokołów TCP/IP
Jest to ustandaryzowany zestaw protokołów sieciowych. Obecnie jest to główny zestaw protokołów komunikacyjnych w Internecie. Możesz przeczytać więcej na temat tego stosu protokołów i nie tylko w tym artykule.
Stos protokołów TCP/IP składa się z dwóch głównych protokołów: IP, TCP i kilku protokołów pomocniczych.
- protokół internetowy- główny protokół warstwy sieciowej. Definiuje metodę adresowania na poziomie sieci.
- TCP (protokół kontroli transmisji)) to protokół zapewniający gwarantowaną dostawę danych.
Jak działają te protokoły?
Protokół IP określa format adresu hosta (dlatego adresy komputerów nazywane są adresami IP) i dostarcza pakiet danych.
Jednak na jednym węźle (komputerze sieciowym) może działać równolegle kilka programów wymagających dostępu do sieci. Dlatego dane w systemie komputerowym muszą być rozdzielone pomiędzy programami. Dlatego podczas przesyłania danych przez sieć nie wystarczy po prostu zaadresować konkretny węzeł. Niezbędna jest także identyfikacja programu odbiorcy, czego nie da się zrobić przy pomocy protokołu IP.
Innym poważnym problemem protokołu IP jest niemożność przesyłania dużych ilości danych. Protokół IP dzieli przesyłane dane na pakiety, z których każdy jest przesyłany do sieci niezależnie od pozostałych. Jeżeli jakiekolwiek pakiety zostaną utracone, moduł IP po stronie odbierającej nie będzie w stanie wykryć utraty, tzn. integralność danych zostanie naruszona.
Aby rozwiązać te problemy, opracowano protokół TCP.
Każdemu programowi przypisany jest numer portu TCP zgodnie z jego funkcjonalnością w oparciu o określone standardy. Port można porównać do celi na poczcie. Protokół IP określa jedynie adres poczty, a protokół TCP umieści kopertę w żądanej komórce.
Zatem stos protokołów IP i TCP zapewnia pełne adresowanie:
- Numer portu TCP umożliwia jednoznaczną identyfikację programu na komputerze sieciowym,
- Komputer w sieci jest jednoznacznie identyfikowany na podstawie adresu IP.
Dlatego kombinacja adresu IP i numeru portu umożliwia jednoznaczną identyfikację programu w sieci. Ten połączony adres nazywa się gniazdo elektryczne(gniazdo elektryczne).
Ponadto protokół TCP zapewnia gwarantowaną dostawę danych. Zapewnia to komputer odbierający potwierdzający pomyślny odbiór danych. Jeśli komputer wysyłający nie otrzyma potwierdzenia, podejmie próbę ponownej transmisji.
Adresy IP, sieci IP. Podsieci i maski podsieci
Więcej na ten temat przeczytasz w tym artykule.
Adresy IP
Każdy komputer w sieci lokalnej ma swój własny, unikalny adres, tak jak osoba ma swój własny adres pocztowy. To właśnie pod tymi adresami komputery odnajdują się w sieci. W tej samej sieci nie powinny znajdować się dwa identyczne adresy. Format adresu jest standardowy i zdefiniowany przez protokół IP.
Adres IP komputera zapisywany jest w postaci 32 bitów (4 oktetów). Każdy oktet zawiera liczbę dziesiętną od 0 do 255 (w systemie binarnym zapis jest ciągiem zer i jedynek). Adres IP to cztery liczby oddzielone kropką. Na przykład komputer z adresem IP 192.168.3.24. Całkowita liczba adresów IP wynosi 4,2 miliarda, wszystkie adresy są unikalne.
Adres IP można przypisać nie tylko komputerowi, ale także innym urządzeniom sieciowym, na przykład serwerowi druku czy routerowi. Dlatego wszystkie urządzenia w sieci nazywane są zwykle węzłami lub zastępy niebieskie.
To samo urządzenie fizyczne (komputer lub inne) może mieć kilka adresów IP. Na przykład, jeśli na komputerze zainstalowanych jest kilka kart sieciowych, każda karta musi mieć swój własny, unikalny adres IP. Takie komputery służą do łączenia kilku sieci lokalnych i nazywane są routery.
Sieci IP
Aby szybko określić trasę, jaką informacje będą przesyłane z jednej sieci lokalnej do drugiej, router może przechowywać w swojej pamięci adresy IP komputerów w tych dwóch sieciach.
W Internecie istnieje ogromna liczba sieci. Routery internetowe musiałyby przechowywać adresy każdego komputera w każdej sieci, co praktycznie uniemożliwiałoby ich działanie.
Aby wskazać lokalizację komputera w sieci, adres IP jest podzielony na dwie części, jedna zawierająca numer sieci, druga zawierająca numer komputera w tej sieci. Podobnie nasz adres pocztowy wskazuje ulicę i stojący na niej dom.
Dla wygody komputery o tym samym numerze sieci są pogrupowane w sieci logiczne Sieci IP.
Komunikacja pomiędzy logicznymi sieciami IP realizowana jest przez routery odpowiedzialne za transmisję danych. A sam proces przesyłania danych - rozgromienie.
Proces ukierunkowanego dostarczania danych pomiędzy sieciami IP związany z zapewnieniem bezpieczeństwa przesyłanych danych, konwersją adresów, filtrowaniem itp. realizowany jest przez inne specjalne urządzenia - bramy.
Podsieci i maski podsieci
Wprowadzenie adresu sieciowego uprościło problemy z routingiem, ale nie rozwiązało ich całkowicie (na przykład w dużych sieciach lokalnych). Dlatego duża sieć IP jest podzielona na kilka podsieci, przypisując każdej z nich własny adres.
Podsieci to oddzielne, niezależnie funkcjonujące części sieci, posiadające własny identyfikator.
W przypadku adresu podsieci adres IP jest przydzielany z adresu hosta.
Aby określić adres sieciowy i podsieć, użyj Maska podsieci. Format wpisu maski podsieci jest taki sam jak format adresu IP, są to cztery pola oddzielone kropką. Wartości pól maski ustawia się w następujący sposób:
- wszystkie bity ustawione na 1 odpowiadają identyfikatorowi sieci;
- wszystkie bity ustawione na 0 odpowiadają identyfikatorowi węzła.
Jeśli wszystkie bity oktetu mają wartość 1, jest to równoznaczne z liczbą 255. Maska jest brana pod uwagę tylko w parach z adresem IP. Na przykład maska podsieci 255.255.255.0 i adres 192.168.100.5 wskazują, że 192.168.100 to numer sieci, a 5 to numer komputera w tej sieci.
Sprawdzając adres IP przez maskę podsieci, protokół IP określa adres sieciowy, adres podsieci i numer hosta.
Dlatego maskę podsieci należy podać w połączeniu z adresem IP komputerów.
Statyczne i dynamiczne adresy IP. DHCP
Wszystkie adresy IP muszą być unikalne w całej sieci. Istnieją dwa sposoby przypisywania tych adresów komputerom w sieci.
Statyczne adresy IP
Statyczny adres IP jest przypisywany do komputera ręcznie. Jest on zalecany przez administratora sieci w ustawieniach protokołu TCP/IP na każdym komputerze w sieci i jest na stałe przypisany do komputera.
Ważna zaleta: stała zgodność adresów IP z konkretnymi komputerami. Pozwala to np. zabronić określonemu komputerowi dostępu do Internetu, ustalić, z jakiego komputera uzyskano dostęp do Internetu itp.
Przydzielanie adresów statycznych komputerom wiąże się z pewnymi niedogodnościami:
- Administrator sieci musi prowadzić rejestr wszystkich używanych adresów, aby uniknąć powtórzeń
- Jeśli w sieci lokalnej znajduje się duża liczba komputerów, instalacja i konfiguracja adresów IP zajmuje dużo czasu
Dynamiczne adresy IP
Jeśli Twojemu komputerowi nie przypisano statycznego adresu IP, adres zostanie przypisany automatycznie przez usługę DHCP. Adres ten nazywany jest adresem dynamicznym, ponieważ Za każdym razem, gdy komputer łączy się z siecią lokalną, adres może się zmieniać, ale zawsze pozostaje w określonym zakresie.
Funkcja automatycznego przydzielania adresu IP gwarantuje unikalność nadawanego adresu IP, jednak inaczej działa w sieci peer-to-peer iw sieci z serwerem.
Dedykowane sieci serwerów
W sieciach zarządzanych przez serwer dynamiczny adres IP przydzielany jest przez specjalną usługę serwera DHCP zawartą w systemie Windows Server 2003. W parametrach usługi DHCP administrator sieci określa zakres adresów IP, z którego adresy będą przydzielane innym komputerom w sieci.
Serwer, na którym działa ta usługa, nazywany jest serwerem DHCP. Komputer uzyskujący adres IP z sieci nazywany jest klientem DHCP.
Sieci peer-to-peer
W sieci peer-to-peer nie ma serwera DHCP, a każdy komputer ma (domyślnie) zainstalowanego klienta DHCP. Po uruchomieniu systemu operacyjnego klient DHCP próbuje znaleźć dostępny serwer DHCP w sieci, aby uzyskać adres IP. Po nieudanej próbie uzyskania adresu IP, klient DHCP komputera włącza wbudowaną funkcję IANA (Internet Assigned Numbers Authority), która przydziela komputerowi adres IP i maskę podsieci przy użyciu jednego z zarezerwowanych adresów. Jednocześnie usługa IANA monitoruje unikalność adresów w sieci.
Zarezerwowane adresy przydzielane są z zakresu od 169.254.0.0 do 169.254.255.255 z maską podsieci 255.255.0.0. Ostatnie dwa pola adresowe reprezentują unikalny identyfikator klienta.
Automatyczne przydzielanie adresu IP odbywa się konsekwentnie na wszystkich komputerach w sieci.
Routery i bramy.
Routera to specjalne urządzenie przeznaczone do przesyłania informacji z jednej sieci do drugiej. Odbiera pakiety z jednej sieci i przesyła je do drugiej, przy czym sieci nie są łączone w jedną sieć, ale pozostają całkowicie niezależne. Routery wyposażone są w system kontroli pozwalający na filtrowanie danych przechodzących przez nie. Konfigurując odpowiednio filtr pakietów, możesz ograniczyć lub całkowicie uniemożliwić niektórym użytkownikom dostęp do innej sieci.
Trasowanie IP- proces wybierania sekwencji routerów, przez które pakiet przechodzi w drodze do węzła docelowego. Router musi mieć kilka adresów IP z numerami podłączonych sieci. Aby to zrobić, musi być wyposażony w kilka kart sieciowych.
Komputer z systemem Windows 2003 Server lub Windows XP Professional może działać jako router. Funkcje routingu są dostępne w tych systemach operacyjnych.
Router jest bramą dla każdej sieci, z którą się łączy. Dokładniej, bramą dla sieci lokalnej jest karta sieciowa zainstalowana w routerze i podłączona do tej sieci. Na przykład stacja robocza w sieci lokalnej chce połączyć się ze stacją roboczą w innej sieci. Wysyła żądanie do swojej sieci w celu znalezienia żądanego adresu IP. Jeżeli adres nie został odnaleziony w sieci, wówczas żądanie wysyłane jest do bramy tej sieci, tj. do routera, który z kolei przekazuje żądanie do innej sieci. Jeśli komputer został znaleziony w drugiej sieci, komunikują się za pośrednictwem routera.
Dodatkowo bramki mogą realizować funkcje związane z zapewnieniem bezpieczeństwa przesyłanych danych, translacją adresów, filtrowaniem itp.
Najpopularniejszymi protokołami routingu zawartymi w stosie protokołów TCP/IP są:
Protokół rozpoznawania adresów, ARP. Protokół rozpoznawania adresów odwzorowuje adres IP na fizyczny adres sprzętowy (adres MAC). Możesz zobaczyć zgodność adresów z tablicy ARP, wpisując arp w wierszu poleceń i podając adres IP.
*Protokół informacji o routingu, RIP. Protokół informacji o routingu używany w celu zapewnienia zgodności wstecznej z istniejącymi sieciami RIP.
*Otwórz najpierw najkrótszą ścieżkę, OSPF. Protokół wyboru najkrótszej trasy.
Routing IP.
Trasowanie IP- proces wyboru ścieżki transmisji pakietu z jednej sieci do drugiej. Ścieżka (trasa) to sekwencja routerów, przez którą przechodzi pakiet w drodze do węzła docelowego. router IP- jest to specjalne urządzenie przeznaczone do przesyłania pakietów z jednej sieci do drugiej i wyznaczania ścieżki pakietów w sieci kompozytowej. Router musi mieć kilka adresów IP z numerami sieci odpowiadającymi numerom podłączanych sieci.
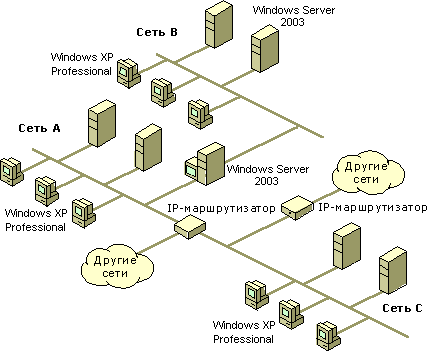
Routing odbywa się w węźle wysyłającym w momencie wysłania pakietu IP, a następnie na routerach IP.
Zasada routingu w węźle wysyłającym wygląda dość prosto. Gdy zachodzi potrzeba wysłania pakietu do węzła o określonym adresie IP, węzeł wysyłający używa maski podsieci w celu wybrania numerów sieci na podstawie własnego adresu IP i adresu IP odbiorcy. Następnie porównywane są numery sieci i jeśli są zgodne, pakiet wysyłany jest bezpośrednio do odbiorcy, w przeciwnym razie – do routera, którego adres jest określony w ustawieniach protokołu IP.
Wybór ścieżki na routerze odbywa się na podstawie informacji podanych w Tabela routingu. Tablica routingu to specjalna tabela, która odwzorowuje adresy IP sieci na adresy kolejnych routerów, do których powinny być wysyłane pakiety, aby dostarczyć je do tych sieci. Wymaganym wpisem w tablicy routingu jest tzw Trasa domyślna, który zawiera informacje o sposobie trasowania pakietów do sieci, których adresów nie ma w tabeli, dzięki czemu nie ma potrzeby opisywania tras dla wszystkich sieci w tabeli. Tablice routingu mogą być budowane „ręcznie” przez administratora lub dynamicznie, w oparciu o wymianę informacji prowadzoną przez routery przy użyciu specjalnych protokołów - dynamiczne protokoły routingu.
Protokoły ARP i RARP.
Główną zaletą funkcjonalną adresowania IP jest całkowita logiczna niezależność adresów IP od adresów fizycznych. Aby jednak narzędzia warstwy łącza mogły dostarczyć dane, konieczna jest znajomość adresu fizycznego odbiorcy. Mechanizm ustalania adresu fizycznego węzła odbiorcy poprzez adres IP zapewnia protokół ARP (Address Solution Protocol).
Określanie adresów fizycznych komputerów odbywa się za pomocą żądania rozgłoszeniowego, które raportuje adres IP żądanego komputera (urządzenia). Po otrzymaniu takiego żądania ARP każdy komputer sprawdza zgodność między określonym adresem IP a swoim własnym. Jeżeli są zgodne, informuje nadawcę o swoim adresie fizycznym. Po otrzymaniu odpowiedzi komputer, który zainicjował żądanie, wprowadza nowe dane do specjalnej tablicy ARP.
Posiadanie tablicy ARP w każdym węźle zmniejsza ilość ruchu rozgłoszeniowego, ponieważ żądanie jest wysyłane do sieci tylko wtedy, gdy żądane dopasowanie nie zostanie znalezione w tablicy ARP.
W niektórych przypadkach może być konieczne ustalenie adresu IP na podstawie adresu MAC. W tym celu wykorzystywany jest protokół RARP (ang. Reverse Address Solution Protocol). Funkcjonalnie RARP jest podobny do protokołu ARP.
Dynamiczne protokoły routingu
Protokoły routingu dynamicznego mają na celu automatyzację procesu tworzenia tablic routingu dla routerów. Zasada ich użycia jest dość prosta: routery, korzystając z kolejności ustalonej przez protokół, wysyłają do innych określone informacje ze swojej tablicy routingu i dostosowują swoją tablicę na podstawie danych otrzymanych od innych.
Ta metoda konstruowania i utrzymywania tablic routingu znacznie upraszcza zadanie administrowania sieciami, które mogą podlegać zmianom (na przykład rozbudowie) lub w sytuacjach, gdy zawiodą jakiekolwiek routery i/lub podsieci.
Należy zaznaczyć, że zastosowanie protokołów routingu dynamicznego nie eliminuje możliwości ręcznego wprowadzania danych do tablic routerów. Wpisy dokonane w ten sposób nazywane są statycznymi, natomiast wpisy uzyskane w wyniku wymiany informacji pomiędzy routerami nazywane są dynamicznymi. Każda tablica routingu zawsze ma co najmniej jeden wpis statyczny – trasę domyślną.
Nowoczesne protokoły routingu dzielą się na dwie grupy: protokoły wektora odległości i protokoły stanu łącza.
W protokołach odległości wektorowych każdy router wysyła listę adresów dostępnych dla niego sieci („wektorów”), z których każdy ma powiązany parametr „odległości” (na przykład liczba routerów w tej sieci, wartość oparta na na wydajność łącza, itp.). Głównym przedstawicielem protokołów z tej grupy jest protokół RIP (ang. Routing Information Protocol).
Protokoły stanu łącza opierają się na innej zasadzie. Routery wymieniają między sobą informacje topologiczne na temat połączeń w sieci: które routery są podłączone do jakich sieci. Dzięki temu każdy router ma pełny obraz struktury sieci (i widok ten będzie taki sam dla wszystkich), na podstawie którego oblicza własną optymalną tablicę routingu. Protokołem dla tej grupy jest OSPF (najpierw otwórz najkrótszą ścieżkę).
Protokół RIP.
RIP (protokół informacji o routingu) to najprostszy protokół routingu dynamicznego. Należy do protokołów wektorowo-odległościowych.
W wektorze protokół RIP definiuje adresy IP sieci, a odległość mierzona jest w przeskokach (hope) – liczbie routerów, przez które musi przejść pakiet, aby dotrzeć do określonej sieci. Należy zaznaczyć, że maksymalna wartość odległości dla protokołu RIP wynosi 15, wartość 16 jest interpretowana w specjalny sposób jako „sieć nieosiągalna”. To określiło główną wadę protokołu - okazuje się, że nie ma on zastosowania w dużych sieciach, w których możliwe są trasy przekraczające 15 przeskoków.
Wersja 1 protokołu RIP ma wiele istotnych wad w praktycznym zastosowaniu. Do ważnych kwestii należą:
- Szacowanie odległości biorąc pod uwagę tylko liczbę przejść. Protokół RIP nie uwzględnia rzeczywistej wydajności kanałów komunikacyjnych, która może być nieefektywna w sieciach heterogenicznych, tj. sieci łączące kanały komunikacji różnych urządzeń, wydajności i wykorzystujące różne technologie sieciowe.
- Problem powolnej konwergencji. Routery korzystające z protokołu RIP. Wysyłają informacje o routingu co 30 sekund, a ich praca nie jest zsynchronizowana. W sytuacji, gdy dany router wykryje, że jakaś sieć stała się niedostępna, to w najgorszym przypadku (jeśli problem został zidentyfikowany od razu po kolejnej transmisji) powiadomi o tym sąsiadów po 30 sekundach. W przypadku sąsiednich routerów wszystko stanie się w ten sam sposób. Oznacza to, że informacja o niedostępności sieci może zająć dużo czasu, zanim rozprzestrzeni się na routery; oczywiście sieć będzie w stanie niestabilnym.
- Rozgłaszanie tablic routingu. Protokół RIP pierwotnie zakładał, że routery wysyłają informacje w trybie rozgłoszeniowym. Oznacza to, że wysłany pakiet musi zostać odebrany i przeanalizowany na poziomie łącza, sieci i transportu przez wszystkie komputery w sieci, do której jest wysyłany.
Częściowo te problemy zostały rozwiązane w wersji 2 (RIP2).
Protokół OSPF
OSPF (Routing (najpierw otwarta najkrótsza ścieżka)) to nowszy protokół routingu dynamicznego i jest protokołem stanu łącza.
Działanie protokołu OSPF opiera się na wykorzystaniu przez wszystkie routery jednej bazy danych, która opisuje w jaki sposób i z jakimi sieciami każdy router jest połączony. Opisując każde połączenie, routery kojarzą z nim metrykę - wartość charakteryzującą „jakość” kanału. Na przykład sieci Ethernet 100 Mb/s używają wartości 1, a połączenia telefoniczne o szybkości 56 Kb/s używają wartości 1785. Dzięki temu routery OSPF (w przeciwieństwie do protokołu RIP, gdzie wszystkie kanały są równe) mogą uwzględniać rzeczywistą przepustowość i identyfikować efektywne trasy. Ważną cechą protokołu OSPF jest to, że wykorzystuje on transmisję multiemisji, a nie transmisję.
Te cechy, takie jak multicast zamiast rozgłaszania, brak ograniczeń długości trasy, okresowa wymiana tylko krótkich komunikatów o statusie i uwzględnienie „jakości” kanałów komunikacyjnych, pozwalają na wykorzystanie protokołu OSPF w dużych sieciach. Jednak takie wykorzystanie może stworzyć poważny problem – dużą ilość informacji o routingu krążących w sieci i wzrost tablic routingu. A ponieważ algorytm wyszukiwania wydajnych tras jest dość złożony pod względem wielkości obliczeniowej, duże sieci mogą wymagać routerów o wysokiej wydajności, a co za tym idzie, drogich. Dlatego możliwość budowania wydajnych tablic routingu można uznać zarówno za zaletę, jak i wadę protokołu OSPF.
Internet będący siecią sieci skupiającą ogromną liczbę różnych sieci lokalnych, regionalnych i korporacyjnych działa i rozwija się dzięki zastosowaniu jednego protokołu transmisji danych TCP/IP. Termin TCP/IP obejmuje nazwę dwóch protokołów:
Protokół kontroli transmisji (TCP) – protokół transportowy;
Protokół internetowy (IP) to protokół routingu.
Protokół routingu. Protokół IP zapewnia przesyłanie informacji pomiędzy komputerami w sieci. Rozważmy działanie tego protokołu przez analogię do przesyłania informacji za pomocą zwykłej poczty. Aby list dotarł do miejsca przeznaczenia, na kopercie wskazany jest adres odbiorcy (do którego list jest kierowany) oraz adres nadawcy (od którego list pochodzi).
Podobnie informacje przesyłane siecią są „pakowane w kopertę”, na której „zapisywane są adresy IP komputerów odbiorcy i nadawcy”, np. „Do: 198.78.213.185”, „Od: 193.124.5.33”. Zawartość koperty w języku komputerowym nazywana jest pakietem IP i stanowi zbiór bajtów.
W procesie przesyłania listów zwykłych są one najpierw dostarczane do urzędu pocztowego położonego najbliżej nadawcy, a następnie przekazywane wzdłuż sieci urzędów pocztowych do urzędu pocztowego położonego najbliżej odbiorcy. W urzędach pocztowych pośrednich następuje sortowanie listów, czyli ustalanie, do którego kolejnego urzędu pocztowego należy wysłać dany list.
W drodze do komputera odbiorcy pakiety IP przechodzą także przez liczne pośrednie serwery internetowe, na których przeprowadzana jest operacja routingu. W wyniku routingu pakiety IP są przesyłane z jednego serwera internetowego na drugi, stopniowo zbliżając się do komputera odbiorcy.
Protokół internetowy (IP) zapewnia routing pakietów IP, czyli dostarczanie informacji z komputera wysyłającego do komputera odbierającego.
Wyznaczanie drogi przepływu informacji. „Geografia” Internetu znacznie różni się od geografii, do której jesteśmy przyzwyczajeni. Szybkość pozyskiwania informacji nie zależy od odległości serwera WWW, ale od liczby serwerów pośredniczących i jakości łączy komunikacyjnych (ich przepustowości), którymi informacja jest przesyłana z węzła do węzła.
Ze szlakiem informacji w Internecie można zapoznać się po prostu w prosty sposób. Specjalny program tracirt.exe zawarty w systemie Windows umożliwia śledzenie, przez które serwery i z jakim opóźnieniem informacje są przesyłane z wybranego serwera internetowego na Twój komputer.
Zobaczmy, jak realizowany jest dostęp do informacji w „moskiewskiej” części Internetu do jednego z najpopularniejszych serwerów wyszukiwania w rosyjskim Internecie www.rambler.ru.
Wyznaczanie drogi przepływu informacji
1. Połącz się z Internetem, wpisz polecenie [Programy-MS-DOS Session].
2. W oknie Sesja MS-DOS, w odpowiedzi na monit systemu, wprowadź polecenie.
3. Po pewnym czasie pojawi się ślad przesłania informacji, czyli lista węzłów, przez które informacje przesyłane są do Twojego komputera, oraz czas transmisji pomiędzy węzłami.
Śledzenie trasy transmisja informacji pokazuje, że serwer www.rambler.ru znajduje się w „odległości” 7 przejść od nas, tj. informacje są przesyłane przez sześć pośrednich serwerów internetowych (za pośrednictwem serwerów moskiewskich dostawców MTU-Inform i Demos). Szybkość przesyłania informacji pomiędzy węzłami jest dość duża, jedno „przejście” trwa od 126 do 138 ms.
Protokół transportowy. A teraz wyobraźmy sobie, że musimy wysłać wielostronicowy rękopis pocztą, ale poczta nie przyjmuje przesyłek ani paczek. Pomysł jest prosty: jeśli rękopis nie mieści się w zwykłej kopercie pocztowej, należy go rozłożyć na arkusze i wysłać w kilku kopertach. W takim przypadku karty rękopisu należy ponumerować, aby odbiorca wiedział, w jakiej kolejności te arkusze zostaną później połączone.
Podobna sytuacja często ma miejsce w Internecie, gdy komputery wymieniają duże pliki. Jeśli wyślesz taki plik w całości, może on na długi czas „zablokować” kanał komunikacji, uniemożliwiając przesyłanie innych wiadomości.
Aby temu zapobiec, na komputerze wysyłającym konieczne jest podzielenie dużego pliku na małe części, ponumerowanie ich i przesłanie w oddzielnych pakietach IP do komputera odbierającego. Na komputerze odbiorcy konieczne jest złożenie pliku źródłowego z poszczególnych części w odpowiedniej kolejności.
Protokół kontroli transmisji (TCP), czyli protokół transportowy, zapewnia, że pliki są dzielone na pakiety IP podczas transmisji, a pliki są składane podczas odbioru.
Określanie czasu wymiany pakietów IP. Czas wymiany pakietów IP pomiędzy komputerem lokalnym a serwerem internetowym można określić za pomocą narzędzia ping, które jest częścią systemu operacyjnego Windows. Narzędzie wysyła cztery pakiety IP na podany adres i wyświetla całkowity czas transmisji i odbioru każdego pakietu
73. Wyszukiwanie informacji w Internecie.
Panuje w dużej mierze słuszna opinia, że dziś w Internecie „ma wszystko” i jedynym problemem jest to, jak znaleźć potrzebne informacje. Bardzo otwarta architektura Sieci sprawia, że brakuje w niej jakiejkolwiek centralizacji, a najcenniejsze dla Ciebie dane, których bezskutecznie przeszukiwałeś na całym świecie, mogą okazać się zlokalizowane na serwerze w tym samym mieście co Ty. Istnieją dwa uzupełniające się podejścia do gromadzenia informacji o zasobach Internetu: tworzenie indeksów I tworzenie katalogów:
Dzięki pierwszej metodzie potężna serwery wyszukiwania Stale „przeszukują” Internet, tworząc i aktualizując bazy danych zawierające informacje o tym, które dokumenty w Internecie zawierają określone słowa kluczowe. Tak więc w rzeczywistości wyszukiwanie odbywa się nie na serwerach internetowych, co byłoby technicznie niemożliwe, ale w bazie danych wyszukiwarki, a brak odpowiednich informacji znalezionych na żądanie nie oznacza, że nie ma ich w Internecie – można spróbuj użyć innego narzędzia wyszukiwania lub katalogu zasobów. Bazy danych serwerów wyszukiwania są nie tylko uzupełniane automatycznie. Każda większa wyszukiwarka ma możliwość zaindeksowania Twojej witryny i dodania jej do bazy danych. Zaletą serwera wyszukiwania jest łatwość pracy z nim, wadą jest niski stopień selekcji dokumentów na żądanie.
W drugim przypadku serwer jest zorganizowany jako katalog biblioteczny, zawierający hierarchię sekcji i podsekcji, w których przechowywane są łącza do dokumentów odpowiadających tematowi podsekcji. Katalog jest zazwyczaj uzupełniany przez samych użytkowników po sprawdzeniu wprowadzonych przez nich danych przez administrację serwera. Katalog zasobów jest zawsze lepiej zorganizowany i ustrukturyzowany, jednak znalezienie odpowiedniej kategorii wymaga czasu, co zresztą nie zawsze jest łatwe do zdefiniowania. Ponadto rozmiar katalogu jest zwykle mniejszy niż liczba witryn zaindeksowanych przez wyszukiwarkę.
Współpraca z serwerami wyszukiwania. Wchodząc na stronę główną serwera wyszukiwania, wystarczy wpisać zapytanie w polu wejściowym w postaci zestawu słów kluczowych i nacisnąć Enter lub przycisk rozpoczęcia wyszukiwania.
Zapytania mogą zawierać dowolne słowa i nie trzeba martwić się o przypadki i deklinacje - na przykład zapytania „esej filozoficzny” i „esej filozoficzny” są całkiem poprawne.
Nowoczesne serwery wyszukiwania dość dobrze rozumieją język naturalny, jednak wiele z nich zachowuje zaawansowane lub specjalne możliwości wyszukiwania, które pozwalają wyszukiwać słowa według maski, łączyć słowa zapytania z operacjami logicznymi „AND”, „OR” itp.
Po zakończeniu przeszukiwania bazy serwer wyświetla pierwszą partię 10 lub więcej dokumentów zawierających słowa kluczowe. Oprócz linku zwykle znajduje się kilka linijek tekstu opisujących dokument lub tylko jego początek. Otwierając linki w nowym lub tym samym oknie przeglądarki, możesz przejść do wybranych dokumentów, a linia linków na dole strony umożliwia przejście do kolejnej porcji dokumentów. Ta linia wygląda mniej więcej tak:
Różne serwery sortują znalezione dokumenty na różne sposoby - według daty utworzenia, ruchu w dokumencie, obecności całości lub części zapytań w dokumencie ( znaczenie), niektóre serwery umożliwiają zawężenie wyszukiwania poprzez wybranie na stronie głównej kategorii szukanego dokumentu - np. zapytanie „banki” w kategorii „świat biznesu” raczej nie spowoduje znalezienia informacji o puszkach.
Wśród popularnych rosyjskojęzycznych narzędzi wyszukiwania możemy wymienić serwery Yandex, Aport I Wędrowiec, indeksując dziesiątki tysięcy serwerów i dziesiątki milionów dokumentów. Popularny z zagranicznych serwerów Altavista, Podniecać, Hotbot, Lykos, Przeszukiwacz sieci, Otwarty tekst.
Wreszcie, w Internecie jest wiele stron poświęconych metawyszukiwarka, dzięki czemu możesz uzyskać dostęp do kilku popularnych serwerów wyszukiwania jednocześnie z tym samym zapytaniem - spójrz na przykład na strony http://www.find.ru/ Lub http://www.rinet.ru/buki/.
Praca z katalogami zasobów. Wchodząc na stronę główną katalogu, znajdziemy się w rozbudowanym menu lub tabeli wyboru kategorii, z których każda może zawierać zagnieżdżone podkategorie. Nie ma tu standardu, ale struktura katalogów jest bardzo podobna, wszędzie można znaleźć sekcje „biznes” lub „świat biznesu”, „komputery”, „programowanie” lub „Internet”, „humor” lub „hobby” itp. . . Poruszając się po kategoriach można dotrzeć do linków do konkretnych dokumentów, które podobnie jak na serwerze wyszukiwania wydawane są porcjami i opatrzone są krótką informacją.
Obecnie istnieje wiele dużych katalogów z dziesiątkami tysięcy linków, z katalogów krajowych możemy wymienić http://www.list.ru/, http://www.weblist.ru/, http://www.stars.ru/, http://www.au.ru/, http://www.ru/, http://www.ulitka.ru/, a od zagranicznych - Wieśniak, Magellana.
Często w katalogu znajduje się także formularz pozwalający na wyszukiwanie według słów kluczowych wśród wyszczególnionych w nim dokumentów.
Zasady wyszukiwania. Kilka prostych wskazówek dotyczących przeszukiwania Internetu.
jasno określ z wyprzedzeniem temat wyszukiwania, słowa kluczowe i czas, jaki chcesz poświęcić na to wyszukiwanie; wybierz serwer wyszukiwania - przydatne jest przechowywanie linków do najlepszych z nich w Ulubionych;
nie bój się języka naturalnego, ale sprawdzaj poprawność pisowni słów, na przykład za pomocą programu Microsoft Word;
W nazwach i tytułach używaj wyłącznie wielkich liter. Wiele wyszukiwarek poprawnie przetworzy zapytanie „abstrakcyjne”, ale nie „Abstrakcyjne”;
Protokół IP znajduje się w warstwie sieciowej stosu protokołów TCP/IP. Funkcje protokołu IP są zdefiniowane w standardzie RFC-791 w następujący sposób: „Protokół IP zapewnia transmisję bloków danych, zwanych datagramami, od nadawcy do odbiorców, przy czym nadawcami i odbiorcami są komputery identyfikowane przez stałą długość adresy ( Adresy IP). Protokół IP zapewnia również fragmentację i ponowne składanie datagramów, jeśli to konieczne, do transmisji danych w sieciach z małymi rozmiarami pakietów. Protokół IP jest niewiarygodne protokół bezpołączeniowy. Oznacza to, że protokół IP nie potwierdza dostarczenia danych, nie kontroluje integralności odebranych danych i nie wykonuje operacji uzgadniania – wymiany komunikatów serwisowych potwierdzających nawiązanie połączenia z węzłem docelowym i jego gotowość do odbioru danych.
Struktura pakietów IP
Pakiet IP składa się z nagłówka i pola danych. Nagłówek, zwykle o długości 20 bajtów, ma następującą strukturę (ryc. 5.12).
Pole Flagi (Wiedźmy) zajmuje 3 bity i zawiera cechy związane z fragmentacją. Ustawiony bit DF (Do not Fragment) zabrania routerowi fragmentowania tego pakietu, a ustawiony bit MF (More Fragments) wskazuje, że ten pakiet jest fragmentem pośrednim (nie ostatnim). Pozostały bit jest zarezerwowany.
Główną funkcją routera jest odczytywanie nagłówków pakietów protokołów sieciowych odebranych i buforowanych na każdym porcie (na przykład IPX, IP, AppleTalk lub DECnet) i podjęcie decyzji o dalszej trasie pakietu zgodnie z jego adresem sieciowym, co zazwyczaj zawiera numer sieci i węzeł numeryczny.
Moduły oprogramowania protokołu IP są instalowane na wszystkich stacjach końcowych i routerach w sieci. Używają tablic routingu do przekazywania pakietów.
Struktura tablicy routingu stosu TCP/IP jest zgodna z ogólnymi zasadami konstruowania tablic routingu. Należy jednak pamiętać, że wygląd tabeli routingu IP zależy od konkretnej implementacji stosu TCP/IP.
Cel pól tabeli routingu
Pomimo dość zauważalnych różnic zewnętrznych, wszystkie trzy tabele zawierają wszystkie kluczowe parametry niezbędne do działania routera.
Do parametrów tych zalicza się oczywiście adres sieci docelowej oraz adres kolejnego routera. Trzeci kluczowy parametr, czyli adres portu, na który należy wysłać pakiet, w niektórych tabelach jest wskazany bezpośrednio, a w innych pośrednio. Pozostałe parametry, które można znaleźć w prezentowanych wersjach tablicy routingu, są opcjonalne przy decydowaniu o ścieżce pakietu.
Źródła i typy wpisów w tablicy routingu:
- Pierwszym źródłem jest oprogramowanie stosu TCP/IP.
- Drugim źródłem pojawienia się wpisu w tabeli jest administrator, który bezpośrednio tworzy wpis za pomocą jakiegoś narzędzia systemowego.
- Trzecim źródłem rekordów mogą być protokoły routingu, takie jak RIP lub OSPF.
Fragmentacja pakietów IP
Protokół IP umożliwia fragmentację pakietów docierających do portów wejściowych routerów. Należy rozróżnić fragmentację komunikatów w węźle nadawczym od fragmentacji dynamicznej komunikatów w węzłach tranzytowych sieci – routerach. Prawie wszystkie stosy protokołów zawierają protokoły odpowiedzialne za fragmentację komunikatów warstwy aplikacji na fragmenty mieszczące się w ramkach warstwy łącza. W stosie TCP/IP problem ten rozwiązuje protokół TCP, który dzieli strumień bajtów przesyłanych do niego z warstwy aplikacji na komunikaty o wymaganej wielkości (np. 1460 bajtów dla protokołu Ethernet). Dlatego protokół IP w węźle wysyłającym nie wykorzystuje swoich możliwości fragmentacji pakietów.
Jeśli jednak konieczne jest przesłanie pakietu do następnej sieci, dla której rozmiar pakietu jest zbyt duży, konieczna staje się fragmentacja IP. Funkcje warstwy IP polegają na dzieleniu wiadomości zbyt długiej dla danego typu komponentu sieci na krótsze pakiety z utworzeniem odpowiednich pól usług niezbędnych do późniejszego złożenia fragmentów w oryginalną wiadomość.
W większości typów sieci lokalnych i rozległych wartości MTU, czyli maksymalny rozmiar pola danych, w którym protokół IP musi enkapsulować swój pakiet, znacznie się różnią. Sieci Ethernet mają MTU 1500 bajtów, sieci FDDI mają MTU 4096 bajtów, a sieci X.25 najczęściej działają z MTU 128 bajtów.
Pakiet IP może być oznaczony jako niefragmentowalny. Pakiet oznaczony w ten sposób nie może być w żadnym wypadku fragmentowany przez moduł IP. Jeśli pakiet oznaczony jako niefragmentowalny nie może dotrzeć do odbiorcy bez fragmentacji, wówczas pakiet ten jest po prostu niszczony, a odpowiedni komunikat ICMP jest wysyłany do hosta wysyłającego.
Procedura łączenia polega na umieszczeniu danych z każdego fragmentu w miejscu określonym w nagłówku pakietu, w polu „fragment offset”.
Każdy moduł IP musi być w stanie przesłać pakiet 68-bajtowy bez dalszej fragmentacji.
Protokół przesyłania danych TCP/IP
Internet będący siecią sieci skupiającą ogromną liczbę różnych sieci lokalnych, regionalnych i korporacyjnych działa i rozwija się dzięki zastosowaniu jednego protokołu transmisji danych TCP/IP. Termin TCP/IP obejmuje nazwę dwóch protokołów:
- Protokół kontroli transmisji (TCP) – protokół transportowy;
- Protokół internetowy (IP) to protokół routingu.
Protokół routingu. Protokół IP zapewnia przesyłanie informacji pomiędzy komputerami w sieci. Rozważmy działanie tego protokołu przez analogię do przesyłania informacji za pomocą zwykłej poczty. Aby list dotarł do miejsca przeznaczenia, na kopercie wskazany jest adres odbiorcy (do którego list jest kierowany) oraz adres nadawcy (od którego list pochodzi).
Podobnie informacje przesyłane siecią są „pakowane w kopertę”, na której „zapisywane są adresy IP komputerów odbiorcy i nadawcy”, np. „Do: 198.78.213.185”, „Od: 193.124.5.33”. Zawartość koperty w języku komputerowym nazywa się Pakiet IP i jest zbiorem bajtów.
W procesie przesyłania listów zwykłych są one najpierw dostarczane do urzędu pocztowego położonego najbliżej nadawcy, a następnie przekazywane wzdłuż sieci urzędów pocztowych do urzędu pocztowego położonego najbliżej odbiorcy. W urzędach pocztowych pośrednich następuje sortowanie listów, czyli ustalanie, do którego kolejnego urzędu pocztowego należy wysłać dany list.
Pakiety IP w drodze do komputera odbiorcy przechodzą także przez liczne pośrednie serwery internetowe, na których wykonywana jest operacja rozgromienie. W wyniku routingu pakiety IP są przesyłane z jednego serwera internetowego na drugi, stopniowo zbliżając się do komputera odbiorcy.
Protokół internetowy (IP) zapewnia routing pakietów IP, czyli dostarczanie informacji z komputera wysyłającego do komputera odbierającego.
Wyznaczanie drogi przepływu informacji.„Geografia” Internetu znacznie różni się od geografii, do której jesteśmy przyzwyczajeni. Szybkość pozyskiwania informacji nie zależy od odległości serwera WWW, ale od liczby serwerów pośredniczących i jakości łączy komunikacyjnych (ich przepustowości), którymi informacja jest przesyłana z węzła do węzła.
Ze szlakiem informacji w Internecie można zapoznać się po prostu w prosty sposób. Specjalny program tracirt.exe zawarty w systemie Windows umożliwia śledzenie, przez które serwery i z jakim opóźnieniem informacje są przesyłane z wybranego serwera internetowego na Twój komputer.
Zobaczmy, jak realizowany jest dostęp do informacji w „moskiewskiej” części Internetu do jednego z najpopularniejszych serwerów wyszukiwania w rosyjskim Internecie www.rambler.ru.
Wyznaczanie drogi przepływu informacji
2. W oknie Sesja MS-DOS w odpowiedzi na monit systemowy o wprowadzenie polecenia.
3. Po pewnym czasie pojawi się ślad przesłania informacji, czyli lista węzłów, przez które informacje przesyłane są do Twojego komputera, oraz czas transmisji pomiędzy węzłami.
 |
Śledzenie trasy transmisji informacji pokazuje, że serwer www.rambler.ru znajduje się w „odległości” 7 przejść od nas, tj. informacje są przesyłane przez sześć pośrednich serwerów internetowych (za pośrednictwem serwerów moskiewskich dostawców MTU-Inform i Demos ). Szybkość przesyłania informacji pomiędzy węzłami jest dość duża, jedno „przejście” trwa od 126 do 138 ms.
Protokół transportowy. A teraz wyobraźmy sobie, że musimy wysłać wielostronicowy rękopis pocztą, ale poczta nie przyjmuje przesyłek ani paczek. Pomysł jest prosty: jeśli rękopis nie mieści się w zwykłej kopercie pocztowej, należy go rozłożyć na arkusze i wysłać w kilku kopertach. W takim przypadku karty rękopisu należy ponumerować, aby odbiorca wiedział, w jakiej kolejności te arkusze zostaną później połączone.
Podobna sytuacja często ma miejsce w Internecie, gdy komputery wymieniają duże pliki. Jeśli wyślesz taki plik w całości, może on na długi czas „zablokować” kanał komunikacji, uniemożliwiając przesyłanie innych wiadomości.
Aby temu zapobiec, na komputerze wysyłającym konieczne jest podzielenie dużego pliku na małe części, ponumerowanie ich i przesłanie w oddzielnych pakietach IP do komputera odbierającego. Na komputerze odbiorcy konieczne jest złożenie pliku źródłowego z poszczególnych części w odpowiedniej kolejności.
Protokół kontroli transmisji (TCP), czyli protokół transportowy, zapewnia, że pliki są dzielone na pakiety IP podczas transmisji, a pliki są składane podczas odbioru.
Co ciekawe, w przypadku protokołu IP odpowiedzialnego za routing pakiety te są ze sobą zupełnie niepowiązane. Dlatego ostatni pakiet IP może po drodze wyprzedzić pierwszy pakiet IP. Może się okazać, że nawet trasy doręczenia tych paczek będą zupełnie inne. Jednakże protokół TCP będzie czekał na pierwszy pakiet IP i złoży plik źródłowy we właściwej kolejności.
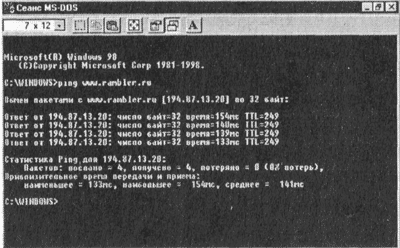
Określanie czasu wymiany pakietów IP. Czas wymiany pakietów IP pomiędzy komputerem lokalnym a serwerem internetowym można określić za pomocą narzędzia ping, które jest częścią systemu operacyjnego Windows. Narzędzie wysyła cztery pakiety IP na podany adres i wyświetla całkowity czas transmisji i odbioru każdego pakietu.
Określanie czasu wymiany pakietów IP
1. Połącz się z Internetem, wpisz polecenie [Programy-MS-DOS Session].
2. W oknie Sesja MS-DOS w odpowiedzi na monit systemowy o wprowadzenie polecenia.
3. W oknie Sesja MS-DOS Wyświetlony zostanie wynik testowania sygnału w czterech próbach. Czas odpowiedzi charakteryzuje parametry szybkości całego łańcucha linii komunikacyjnych od serwera do komputera lokalnego.
 |
Pytania do rozważenia
1. Co zapewnia integralne funkcjonowanie globalnej sieci komputerowej Internet?
Zadania praktyczne
4,5. Prześledź drogę informacji z jednego z najpopularniejszych serwerów wyszukiwania internetowego www.yahoo.com, zlokalizowanego w „amerykańskim” segmencie Internetu.
4.6. Określ czas wymiany pakietów IP z serwerem www.yahoo.com.
Tabela wyraźnie pokazuje maski sieci.
Pierwsze dwa wpisy wskazują, że sam router poprzez odpowiadające mu interfejsy IP wysyła datagramy adresowane do sieci, z którą jest bezpośrednio połączony. Wszystkie pozostałe datagramy są przekazywane do G2 (194.84.0.118). Interfejs se0 oznacza kanał szeregowy - linię dedykowaną.
2.3.5. Tworzenie tras statycznych
Tablicę tras można wypełnić na różne sposoby. Routing statyczny jest używany, gdy używane trasy nie mogą zmieniać się w czasie, jak np. host i router omówione powyżej, gdzie po prostu nie ma alternatywnych tras. Trasy statyczne są konfigurowane przez administratora sieci lub hosta.
Dla zwykłego hosta z omówionego powyżej przykładu wystarczy wskazać jedynie adres bramy (kolejnego routera w trasie domyślnej), reszta wpisów w tabeli jest oczywista, a host znając własne IP adres i maskę sieci, można je wprowadzić niezależnie. Adres bramy można podać ręcznie lub uzyskać automatycznie podczas konfiguracji stosu TCP/IP za pośrednictwem serwera DHCP (patrz praca laboratoryjna „Dynamiczne przydzielanie adresów IP” w kursie „Technologie internetowe”).
2.3.6. Routing dynamiczny
W przypadku łączenia sieci o złożonej topologii, gdy istnieje kilka opcji tras z jednego węzła do drugiego i (lub) gdy stan sieci (topologia, jakość kanałów komunikacyjnych) zmienia się w czasie, tablice tras są kompilowane dynamicznie przy użyciu różne protokoły routingu. Podkreślamy, że protokoły routingu w rzeczywistości nie routują datagramów - w każdym razie jest to wykonywane przez moduł IP zgodnie z wpisami w tablicy tras, jak omówiono powyżej. Protokoły routingu, bazujące na określonych algorytmach, dynamicznie edytują tablicę tras, czyli dodają i usuwają wpisy, choć niektóre wpisy nadal mogą być wprowadzane statycznie przez administratora.
W zależności od algorytmu działania istnieją wektor odległości protokoły i protokoły wektora odległości stany połączenia(protokoły stanu łącza).
Ze względu na obszar zastosowania istnieje podział na protokoły zewnętrzny(na zewnątrz) i wewnętrzny(wewnętrzne) trasowanie.
Protokoły wektora odległości zaimplementować algorytm Bellmana-Forda. Ogólny schemat ich działania jest następujący: każdy router okresowo rozsyła informacje o odległości od siebie do wszystkich znanych mu sieci ( „wektor odległości”). Oczywiście w początkowej chwili wysyłane są informacje tylko o tych sieciach, do których router jest bezpośrednio podłączony.
Ponadto każdy router otrzymawszy od kogoś wektor odległości, zgodnie z otrzymaną informacją, koryguje posiadane już dane o osiągalności sieci lub dodaje nowe, wskazując jako router, od którego otrzymano wektor następny router w drodze do sieci danych. Po pewnym czasie algorytm osiąga zbieżność i wszystkie routery mają informację o trasach do wszystkich sieci.
Protokoły wektora odległości działają dobrze tylko w małych sieciach. Algorytm ich działania zostanie omówiony szerzej w rozdziale 4. Rozwój technologii wektorów odległości - „wektorów ścieżek” stosowanych w protokole BGP.
Podczas pracy protokoły stanu łącza Każdy router monitoruje stan swoich połączeń z sąsiadami i w przypadku zmiany stanu (na przykład zerwania połączenia) wysyła komunikat rozgłoszeniowy, po odebraniu którego wszystkie pozostałe routery dostosowują swoje bazy danych i przeliczają trasy. W przeciwieństwie do protokołów wektora odległości, protokoły stanu łącza tworzą na każdym routerze bazę danych, która opisuje pełny wykres sieci i umożliwia lokalne, a tym samym szybkie obliczanie tras.
Powszechnym protokołem tego typu jest OSPF, opiera się na algorytmie SPF (ang. Shortest Path First) służącym do znajdowania najkrótszej ścieżki w grafie, zaproponowanym przez E.W. Dijkstrę.
Protokoły stanu łącza są znacznie bardziej złożone niż protokoły wektora odległości, ale zapewniają szybsze, bardziej optymalne i poprawne obliczanie tras. Protokoły stanu łącza zostaną omówione bardziej szczegółowo na przykładzie protokołu OSPF w rozdziale 5.
Wewnętrzne protokoły routingu (na przykład RIP, OSPF; zbiorczo zwane IGP – Interior Gateway Protocols) są używane na routerach działających wewnątrz systemy autonomiczne . System autonomiczny to największy dział Internetu, będący połączeniem sieci o tej samej polityce routingu i wspólnej administracji, na przykład zbioru sieci firmy Global One i jej klientów w Rosji.
Zakres konkretnego protokołu routingu wewnętrznego może nie obejmować całego systemu autonomicznego, ale jedynie pewną kombinację sieci wchodzącą w skład systemu autonomicznego. Nazwiemy taki związek systemu sieciowego , lub po prostu system, czasami wskazując protokół routingu działający w tym systemie, na przykład: system RIP, system OSPF.
Rozgromienie między realizowane przez systemy autonomiczne granica routery (graniczne), których tablice tras są kompilowane przy użyciu zewnętrznych protokołów routingu (zwanych łącznie EGP – Exterior Gateway Protocols). Osobliwością zewnętrznych protokołów routingu jest to, że przy obliczaniu tras muszą one uwzględniać nie tylko topologię wykresu sieci, ale także ograniczenia polityczne nałożone przez administrację systemów autonomicznych na routing ruchu innych systemów autonomicznych przez ich sieci. Obecnie najpopularniejszym protokołem routingu zewnętrznego jest BGP.
2.4. Format nagłówka datagramu IP
Datagram IP składa się z nagłówka i danych.
Nagłówek datagramu składa się z 32-bitowych słów i ma zmienną długość w zależności od rozmiaru pola opcji, ale zawsze jest wielokrotnością 32 bitów. Bezpośrednio po nagłówku następują dane zawarte w datagramie.
Format nagłówka:
Wartości pola nagłówka są następujące.
Wer(4 bity) - wersja protokołu IP, obecnie używana jest wersja 4, nowe rozwiązania mają numery wersji 6-8.
MPH (długość nagłówka internetowego)(4 bity) - długość nagłówka w słowach 32-bitowych; zakres prawidłowych wartości wynosi od 5 (minimalna długość nagłówka, brak pola „Opcje”) do 15 (czyli maksymalnie może być 40 bajtów opcji).
Warunki świadczenia usług (rodzaj usługi)(8 bitów) - wartość pola określa priorytet datagramu i pożądany typ routingu. Struktura bajtów TOS:
Trzy najmniej znaczące bity („Pierwszeństwo”) określają priorytet datagramu:
111 - zarządzanie siecią
110 - zarządzanie siecią
101 - KRYTYK-ECP
100 - więcej niż natychmiast
011 - natychmiast
010 - natychmiast
001 - pilne
000 - zwykle
Bity D, T, R, C określają żądany typ routingu:
D (Opóźnienie) - wybór trasy z minimalnym opóźnieniem,
T (Przepustowość) – wybór trasy o maksymalnej przepustowości,
R (Reliability) – wybór trasy o maksymalnej niezawodności,
C (Koszt) - wybór trasy z minimalnym kosztem.
W datagramie można ustawić tylko jeden z bitów D, T, R, C. Najbardziej znaczący bit bajtu nie jest używany.
Rzeczywiste uwzględnienie priorytetów i wybór trasy w oparciu o wartość bajtu TOS zależy od routera, jego oprogramowania i ustawień. Router może obsługiwać obliczanie tras dla wszystkich typów TOS, niektórych lub całkowicie ignorować TOS. Router może uwzględnić wartość priorytetu podczas przetwarzania wszystkich datagramów lub datagramów pochodzących tylko z ograniczonego zestawu węzłów sieciowych, albo całkowicie zignorować priorytet.
Długość całkowita(16 bitów) - długość całego datagramu w oktetach, łącznie z nagłówkiem i danymi, wartość maksymalna 65535, minimalna - 21 (nagłówek bez opcji i jeden oktet w polu danych).
Identyfikator (identyfikacja)(16 bitów), Flagi(3 bity), Przesunięcie fragmentu(13 bitów) służy do fragmentacji i ponownego składania datagramów, co zostanie omówione bardziej szczegółowo poniżej w sekcji 2.4.1.
TTL (czas życia)(8 bitów) - „czas życia” datagramu. Ustawiane przez nadawcę, mierzone w sekundach. Każdy router, przez który przechodzi datagram, zapisuje wartość TTL, odejmując od niej najpierw czas przetwarzania datagramu. Ponieważ prędkość przetwarzania routerów jest obecnie tak duża, przetworzenie jednego datagramu zajmuje zwykle mniej niż sekundę, więc każdy router faktycznie odejmuje jeden od TTL. Po osiągnięciu TTL=0 datagram jest odrzucany i do nadawcy można wysłać odpowiedni komunikat ICMP. Kontrola TTL zapobiega zapętlaniu się datagramu w sieci.
Protokół(8 bitów) - określa program (protokół wyższego stosu), do którego należy przesłać dane datagramu w celu dalszego przetwarzania. Niektóre kody protokołów przedstawiono w tabeli 2.4.1.
Kody protokołu IP
| Kod | Protokół | Opis |
| 1 | ICMP | Kontroluj protokół wiadomości |
| 2 | IGMP | Protokół zarządzania grupą hostów |
| 4 | IP | IP przez IP (hermetyzacja) |
| 6 | TCP | |
| 8 | E.G.P. | Zewnętrzny protokół routingu (przestarzały) |
| 9 | IGP | Wewnętrzny protokół routingu (przestarzały) |
| 17 | UDP | |
| 46 | Odpowiedź | Protokół rezerwacji zasobów dla multiemisji |
| 88 | IGRP | Wewnętrzny protokół routingu firmy Cisco |
| 89 | OSPF | Wewnętrzny protokół routingu |
Suma kontrolna nagłówka(16 bitów) - suma kontrolna nagłówka, składa się z 16 bitów, bitów uzupełniających w sumie wszystkich 16-bitowych słów nagłówka. Przed obliczeniem sumy kontrolnej wartość pola „Suma kontrolna nagłówka” jest resetowana do zera. Ponieważ routery zmieniają wartości niektórych pól nagłówka podczas przetwarzania datagramu (przynajmniej pola „TTL”), suma kontrolna jest przeliczana przez każdy router. Jeśli podczas weryfikacji sumy kontrolnej zostanie wykryty błąd, datagram jest odrzucany.
Adres źródłowy(32 bity) - adres IP nadawcy.
Adres przeznaczenia(32 bity) - adres IP odbiorcy.
Wyściółka- wyrównanie nagłówka na granicy słowa 32-bitowego, jeśli lista opcji zajmuje niecałkowitą liczbę słów 32-bitowych. Pole „Dopełnienie” jest wypełnione zerami.
2.4.1. Fragmentacja datagramów
Różne media transmisyjne mają różny maksymalny rozmiar przesyłanej jednostki danych (MTU – Media Transmission Unit), liczba ta zależy od charakterystyki prędkości medium i prawdopodobieństwa wystąpienia błędu podczas transmisji. Na przykład rozmiar MTU w 10 Mbit/s Ethernet wynosi 1536 oktetów, w 100 Mbit/s FDDI jest to 4096 oktetów.
Podczas przesyłania datagramu ze środowiska o dużej jednostce MTU do środowiska o mniejszej jednostce MTU może zaistnieć konieczność fragmentacji datagramu. Fragmentacja i ponowne składanie datagramów odbywa się za pomocą modułu protokołu IP. W tym celu wykorzystywane są pola „ID” (Identyfikacja), „Flags” i „Fragment Offset” nagłówka datagramu.
Flagi-pole składa się z 3 bitów, z których najmniej znaczący jest zawsze resetowany:
Wartości bitów DF (nie fragmentuj):
0 - fragmentacja dozwolona,
1 - fragmentacja wyłączona (jeżeli datagram nie może zostać przesłany bez fragmentacji, ulega zniszczeniu).
Wartości bitów MF (więcej fragmentów):
0 - ten fragment jest ostatnim (jedynym),
1 - ten fragment nie jest ostatnim.
Identyfikator (identyfikacja)- identyfikator datagramu, ustalany przez nadawcę; służy do składania datagramu z fragmentów w celu ustalenia, czy fragmenty należą do tego samego datagramu.
Przesunięcie fragmentu- przesunięcie fragmentu, wartość pola wskazuje, w którym miejscu pola danych oryginalnego datagramu znajduje się ten fragment. Przesunięcie jest uwzględniane w fragmentach 64-bitowych, tj. Minimalny rozmiar fragmentu wynosi 8 oktetów, a następny fragment w tym przypadku będzie miał przesunięcie 1. Pierwszy fragment ma przesunięcie zero.
Spójrzmy na proces fragmentacji na przykładzie. Załóżmy, że datagram składający się z 4020 oktetów (w tym 20 oktetów nagłówka) jest przesyłany ze środowiska FDDI (MTU=4096) do środowiska Ethernet (MTU=1536). Na granicy mediów datagram jest pofragmentowany. Nagłówki w tym datagramie i we wszystkich jego fragmentach mają tę samą długość - 20 oktetów.
Oryginalny datagram:
nagłówek: ID=X, długość całkowita=4020, DF=0, MF=0, FOffset=0
dane (4000 oktetów): „A....A” (1472 oktetów), „B....B” (1472 oktetów), „C...C” (1056 oktetów)
Fragment 1:
nagłówek: ID=X, długość całkowita=1492, DF=0, MF=1, FOffset=0
dane: „A....A” (1472 oktety)
Fragment 2:
nagłówek: ID=X, długość całkowita=1492, DF=0, MF=1, FOffset=184
dane: „B....B” (1472 oktety)
Fragment 3:
nagłówek: ID=X, długość całkowita=1076, DF=0, MF=0, FOffset=368
dane: „C....C” (1056 oktetów)
Fragmentacja może mieć charakter rekurencyjny, tzn. np. fragmenty 1 i 2 mogą zostać ponownie pofragmentowane; w tym przypadku przesunięcie (przesunięcie fragmentu) jest obliczane od początku oryginalnego datagramu.
2.4.2. Dyskusja na temat fragmentacji
Maksymalna liczba fragmentów wynosi 2 13 = 8192 przy minimalnym rozmiarze (8 oktetów) każdego fragmentu. Przy większym rozmiarze fragmentu maksymalna liczba fragmentów odpowiednio się zmniejsza.
Podczas fragmentacji niektóre opcje są kopiowane do nagłówka fragmentu, inne nie. Wszystkie pozostałe pola nagłówka datagramu w nagłówku fragmentu są obecne. Następujące pola nagłówka mogą zmieniać swoją wartość w stosunku do oryginalnego datagramu: pole opcji, flaga „MF”, „Fragment Offset”, „Total Długość”, „IHL”, suma kontrolna. Pozostałe pola są kopiowane we fragmentach bez zmian.
Każdy moduł IP musi być w stanie przesłać datagram o długości 68 oktetów bez fragmentacji (maksymalny rozmiar nagłówka 60 oktetów + minimalny fragment 8 oktetów).
Ponowne składanie fragmentów następuje tylko w węźle docelowym datagramu, ponieważ różne fragmenty mogą podążać różnymi drogami do miejsca docelowego.
Jeśli fragmenty zostaną opóźnione lub utracone w transporcie, wartość TTL pozostałych fragmentów otrzymanych już w punkcie ponownego montażu będzie zmniejszana o jedną sekundę, aż do momentu dotarcia brakujących fragmentów. Jeśli TTL osiągnie zero, wszystkie fragmenty zostaną zniszczone, a zasoby użyte do ponownego złożenia datagramu zostaną zwolnione.
Maksymalna liczba identyfikatorów datagramów wynosi 65536. Jeśli używane są wszystkie identyfikatory, należy poczekać do wygaśnięcia TTL, zanim będzie można ponownie użyć tego samego identyfikatora, ponieważ w ciągu sekund TTL „stary” datagram zostanie dostarczony i ponownie złożony lub zniszczony.
Przesyłanie datagramów z fragmentacją ma pewne wady. Przykładowo, jak wynika z poprzedniego akapitu, maksymalna prędkość takiej transmisji wynosi 65536 datagramów/TTL na sekundę. Jeśli weźmiemy pod uwagę, że zalecana wartość TTL wynosi 120, otrzymamy maksymalną prędkość 546 datagramów na sekundę. W środowisku FDDI MTU wynosi około 4100 oktetów, z czego uzyskujemy maksymalną prędkość przesyłania danych w środowisku FDDI na poziomie nie większym niż 18 Mbit/s, czyli znacznie poniżej możliwości tego środowiska.
Kolejną wadą fragmentacji jest jej niska wydajność: w przypadku utraty jednego fragmentu retransmitowany jest cały datagram; Podczas jednoczesnego oczekiwania na opóźnione fragmenty kilku datagramów powstaje zauważalny niedobór zasobów i działanie węzła sieciowego ulega spowolnieniu.
Sposobem na ominięcie procesu fragmentacji jest zastosowanie algorytmu „Path MTU Discovery”, algorytm ten jest obsługiwany przez protokół TCP. Celem algorytmu jest odkrycie minimalnej wartości MTU na całej trasie od nadawcy do miejsca docelowego. W tym celu datagramy wysyłane są z ustawionym bitem DF („fragmentacja zabroniona”). Jeśli nie dotrą one do miejsca docelowego, rozmiar datagramu zostanie zmniejszony i proces ten będzie kontynuowany aż do pomyślnej transmisji. Podczas przesyłania ładunków tworzone są datagramy o rozmiarze odpowiadającym wykrytej minimalnej wartości MTU.
2.4.3. Opcje IP
Opcje definiują dodatkowe usługi protokołu IP do przetwarzania datagramów. Opcja składa się co najmniej z oktetu typu opcji, po którym może następować oktet długości opcji i oktety danych dla opcji.
Struktura oktetu „Typ opcji”:
Wartości bitu C:
1 - opcja jest kopiowana do wszystkich fragmentów;
0 - opcja jest kopiowana tylko do pierwszego fragmentu.
Zdefiniowano dwie klasy opcji: 0 – „Zarządzanie” i 2 – „Pomiary i debugowanie”. W obrębie klasy opcja jest identyfikowana za pomocą liczby. Poniżej znajdują się opcje opisane w standardzie protokołu IP; znak „-” w kolumnie „Długość oktetu” oznacza, że opcja składa się wyłącznie z oktetu „Typ opcji”, liczba obok znaku plus oznacza, że opcja ma stałą długość (długość wyrażona jest w oktetach).
Tabela 2.4.2
Długość oktetu |
|||
Koniec listy opcji |
|||
Bez operacji |
|||
Bezpieczeństwo |
|||
Loose Source Routing (swobodna realizacja trasy nadawcy) |
|||
Strict Source Routing (ścisłe wykonanie trasy nadawcy) |
|||
Rejestrowanie trasy |
|||
Internetowy znacznik czasu |
Po znalezieniu na liście opcji „Koniec listy opcji” analizowanie opcji zostaje zatrzymane, nawet jeśli długość nagłówka (IHL) nie została jeszcze wyczerpana. Opcja Brak operacji jest zwykle używana do wyrównywania opcji na granicy 32-bitowej.
Większość opcji nie jest obecnie używana. Opcje „Identyfikator strumienia” i „Bezpieczeństwo” zostały wykorzystane w ograniczonym zakresie eksperymentów, funkcje opcji „Nagraj trasę” i „Internetowy znacznik czasu” realizuje program traceroute. Jedynie opcje „Loose/Strict Source Routing” są interesujące i zostały omówione w następnym akapicie.
Korzystanie z opcji w datagramach spowalnia ich przetwarzanie. Ponieważ większość datagramów nie zawiera opcji, czyli ma stałą długość nagłówka, ich przetwarzanie jest maksymalnie zoptymalizowane dla tego konkretnego przypadku. Pojawienie się opcji przerywa ten szybki proces i wywołuje standardowy uniwersalny moduł IP, który może przetwarzać dowolne standardowe opcje, ale kosztem znacznej utraty wydajności.
Opcje „Loose/Strict Source Routing” (odpowiednio klasa 0, cyfry 3 i 9) mają na celu wskazanie datagramowi trasy ustalonej przez nadawcę.
Obie opcje wyglądają tak samo:
Pole „Dane” zawiera listę adresów IP żądanej trasy w kolejności. Pole „Wskaźnik” służy do określenia kolejnego punktu trasy, zawiera numer pierwszego oktetu adresu IP tego punktu w polu „Dane”. Liczby liczone są od początku opcji od jedynki, początkowa wartość wskaźnika to 4.
Opcje działają w następujący sposób.
Załóżmy, że datagram wysłany z A do B musi przejść przez routery G1 i G2. Przy wyjściu z A pole „Adres docelowy” nagłówka datagramu zawiera adres G1, a pole danych opcji zawiera adresy G2 i B (wskaźnik = 4). Po przybyciu datagramu do G1, z pola danych opcji, zaczynając od oktetu wskazanego przez wskaźnik (oktet 4), pobierany jest adres kolejnego miejsca docelowego (G2) i umieszczany w polu „Adres docelowy”, wartość wskaźnika zwiększa się o 4, a adres G2 zostaje zastąpiony. Pole danych opcji zawiera adres interfejsu routera G1, przez który datagram zostanie wysłany do nowego miejsca docelowego (czyli do G2). Po dotarciu datagramu do G2 procedura jest powtarzana i datagram jest wysyłany do B. Podczas przetwarzania datagramu w B okazuje się, że wartość wskaźnika (12) przekracza długość opcji, co oznacza, że osiągnięty został ostateczny cel trasy.
Różnice pomiędzy opcjami „Loose Source Routing” i „Strict Source Routing” są następujące:
„Luźno”: do następnego punktu żądanej trasy można dotrzeć dowolną liczbą kroków ( chmiel);
„Ścisłe”: do następnego punktu żądanej trasy należy dotrzeć w 1 kroku, czyli bezpośrednio.
Rozważane opcje są kopiowane do wszystkich fragmentów. Na jeden datagram może przypadać tylko jedna taka opcja.
Opcja „Loose/Strict Source Routing” może zostać wykorzystana w celu nieautoryzowanej penetracji przez węzeł kontrolujący (filtrujący) (w polu „Adres docelowy” ustawiany jest dozwolony adres, datagram przekazywany jest przez węzeł kontrolujący, następnie z pola danych opcji zostaje podstawiony zabroniony adres i datagram zostaje przekierowany na ten adres, który jest już poza zasięgiem węzła kontrolującego), dlatego ze względów bezpieczeństwa zaleca się, aby węzeł kontrolujący ogólnie zabraniał przekazywania datagramów z opcjami w pytanie.
Szybką alternatywą dla korzystania z opcji „Loose Source Routing” jest enkapsulacja IP-IP: zamknięcie datagramu IP w datagramie IP (pole „Protokół” datagramu zewnętrznego ma wartość 4, patrz ). Na przykład musisz wysłać segment TCP z A do B przez C. Taki datagram jest wysyłany z A do C:
Podczas przetwarzania datagramu w C okazuje się, że dane datagramu muszą zostać przesłane do protokołu IP w celu przetworzenia i są oczywiście również datagramami IP. Ten wewnętrzny datagram jest pobierany i wysyłany do B.
W tym przypadku dodatkowy czas na przetworzenie datagramu był wymagany tylko w węźle C (przetworzenie dwóch nagłówków zamiast jednego), natomiast we wszystkich pozostałych węzłach trasy nie było wymagane dodatkowe przetwarzanie, w przeciwieństwie do przypadku użycia opcji.
Stosowanie enkapsulacji IP-IP może również powodować problemy związane z bezpieczeństwem opisane powyżej.
2.5. Protokół ICMP
Protokół ICMP (ang. Internet Control Message Protocol) stanowi integralną część modułu IP. Zapewnia informację zwrotną w postaci komunikatów diagnostycznych wysyłanych do nadawcy, gdy jego datagram nie może zostać dostarczony oraz w innych przypadkach. ICMP jest standaryzowany w RFC-792 z dodatkami w RCF-950.1256.
Komunikaty ICMP nie są generowane, jeśli dostarczenie jest niemożliwe:
- datagramy zawierające komunikaty ICMP;
- nie pierwsze fragmenty datagramu;
- datagramy wysyłane na adres grupowy (broadcasting, multicasting);
- datagramy, których adres źródłowy ma wartość null lub multiemisji.
Wszystkie komunikaty ICMP posiadają nagłówek IP, wartość pola „Protokół” wynosi 1. Dane datagramowe z komunikatem ICMP nie są przekazywane przez stos protokołów do przetworzenia, lecz są przetwarzane przez moduł IP.
Po nagłówku IP znajduje się 32-bitowe słowo z polami „Typ”, „Kod” i „Suma kontrolna”. Pola typu i kodu definiują treść komunikatu ICMP. Format pozostałej części datagramu zależy od typu wiadomości. Sumę kontrolną oblicza się analogicznie jak w nagłówku IP, jednak w tym przypadku sumowana jest zawartość komunikatu ICMP, łącznie z polami „Typ” i „Kod”.
Tabela 2.5.1
Rodzaje komunikatów ICMP
Wiadomość |
||
Odpowiedź Echa |
||
Miejsce docelowe nieosiągalne (miejsce docelowe jest nieosiągalne z różnych powodów): |
||
Sieć nieosiągalna (sieć niedostępna) |
||
Host nieosiągalny (host niedostępny) |
||
Protokół niedostępny |
||
Port nieosiągalny (port niedostępny) |
||
DF=1 (fragmentacja wymagana, ale niedozwolona) |
||
Trasa źródłowa nie powiodła się (nie można wykonać opcji Trasa źródłowa) |
||
Wygaszanie źródła |
||
Przekieruj (wybierz inny router, do którego chcesz wysyłać datagramy) |
||
do tej sieci |
||
do tego gospodarza |
||
do danej sieci z określonym TOS |
||
do danego hosta z określonymi TOS |
||
Prośba o echo |
||
Reklama routera |
||
Zapytanie o router (żądanie ogłoszenia o routerze) |
||
Przekroczono czas (upłynął okres ważności datagramu) |
||
po transmisji |
||
podczas montażu |
||
Problem z parametrami |
||
Błąd w nagłówku IP |
||
Brak wymaganej opcji |
||
Znacznik czasu (żądanie znacznika czasu) |
||
Odpowiedź dotycząca znacznika czasu (odpowiedź na żądanie znacznika czasu) |
||
Żądanie maski adresu |
||
Odpowiedź maski adresu (odpowiedź na żądanie maski sieci) |
Poniżej omawiamy formaty komunikatów ICMP i przedstawiamy komentarze do niektórych komunikatów.
Typy 3, 4, 11, 12
W komunikacie typu 12 pole „xxxxxxxxxxxxx” (1 oktet) zawiera numer oktetu nagłówka, w którym wykryto błąd; nieużywane w wiadomościach typu 3, 4, 11. Wszystkie nieużywane pola wypełniane są zerami.
Komunikaty typu 4 („Source Slowdown”) są generowane, gdy bufory przetwarzania datagramów w węźle docelowym lub pośrednim na trasie są pełne (lub grozi im przepełnienie). Odbierając taką wiadomość, nadawca musi zmniejszyć prędkość lub wstrzymać wysyłanie datagramów do czasu, aż przestanie otrzymywać wiadomości tego typu.
Nagłówek IP i początkowe słowa oryginalnego datagramu służą do identyfikacji twórcy datagramu i ewentualnej analizy przyczyny awarii.
Wpisz 5
Komunikaty typu 5 są wysyłane przez router do nadawcy datagramu, gdy router uważa, że datagramy do danego miejsca docelowego powinny być kierowane przez inny router. Adres nowego routera podawany jest w drugim słowie komunikatu.
Pojęcie „miejsce docelowe” określa wartość pola „Kod” (patrz tabela 2.5.1). Informacje o tym, dokąd wysłano datagram, który wygenerował komunikaty ICMP, pochodzą z jego nagłówka dołączonego do wiadomości. Brak transmisji poprzez maskę sieci ogranicza zakres komunikatów typu 5.
Typy 0,8
Typy komunikatów 0 i 8 służą do testowania komunikacji IP pomiędzy dwoma węzłami sieci. Węzeł testujący generuje komunikaty typu 8 („Echo Request”), natomiast „Identyfikator” określa tę sesję testową (numer kolejny wysłanych komunikatów), pole „Numer sekwencyjny” zawiera numer tego komunikatu w sekwencji. Pole danych zawiera dowolne dane, o wielkości tego pola decyduje całkowita długość datagramu, podana w polu „Całkowita długość” nagłówka IP.
Moduł IP, który odbiera żądanie echa, wysyła odpowiedź echa. W tym celu zamienia adresy nadawcy i odbiorcy, zmienia typ komunikatu ICMP na 0 i ponownie oblicza sumę kontrolną.
Węzeł testujący na podstawie samego faktu otrzymania odpowiedzi echa, czasu realizacji datagramu, procentu strat oraz kolejności nadejścia odpowiedzi może wyciągnąć wnioski na temat obecności i jakości komunikacji z testowanym węzłem. Program ping działa poprzez wysyłanie i odbieranie wiadomości echa.
Wpisz 9
Komunikaty typu 9 (anonsowanie routera) są okresowo wysyłane przez routery do hostów w sieci, dzięki czemu hosty mogą automatycznie konfigurować swoje tablice routingu. Zazwyczaj takie wiadomości są wysyłane na adres multiemisji 224.0.0.1 („wszystkie hosty”) lub na adres rozgłoszeniowy.
Wiadomość zawiera adresy jednego lub więcej routerów wraz z wartościami priorytetów dla każdego routera. Priorytetem jest liczba ze znakiem, zapisana w uzupełnieniu do dwójki; im wyższa liczba, tym wyższy priorytet.
Pole „NumAddr” zawiera liczbę adresów routerów w tej wiadomości; wartość pola „AddrEntrySize” jest równa dwa (rozmiar pola przeznaczonego na informacje o jednym routerze, w słowach 32-bitowych). „Czas życia” określa datę ważności informacji zawartych w tej wiadomości, wyrażoną w sekundach.
Wpisz 10
Komunikat typu 10 (Żądanie ogłoszenia routera) składa się z dwóch 32-bitowych słów, z których pierwsze zawiera pola Typ, Kod i Suma kontrolna, a drugie jest zarezerwowane (wypełnione zerami).
Typy 17 i 18
Komunikaty typu 17 i 18 (żądanie i odpowiedź na żądanie wartości maski sieci) są używane, gdy host chce poznać maskę sieci, w której się znajduje. W tym celu na adres routera wysyłane jest żądanie (lub rozgłaszane, jeśli adres routera jest nieznany). Router odpowiada komunikatem zawierającym wartość maski sieci, z której nadeszło żądanie. W przypadku, gdy requester nie zna jeszcze swojego adresu IP, odpowiedź wysyłana jest metodą rozgłoszeniową.
Pola „Identyfikator” i „Numer sekwencyjny” można wykorzystać do kontroli zgodności żądań i odpowiedzi, ale w większości przypadków są one ignorowane.
2.6. Protokół ARP
ARP (Address Solution Protocol) służy do tłumaczenia adresów IP na adresy MAC, często zwane także adresami fizycznymi.
MAC oznacza kontrolę dostępu do multimediów, kontrolę dostępu do multimediów. Adresy MAC identyfikują urządzenia podłączone do łącza fizycznego; przykładem adresu MAC jest adres Ethernet.
Aby przesłać datagram IP kanałem fizycznym (rozważymy Ethernet), należy zakapsułkować ten datagram w ramce Ethernet i w nagłówku ramki wskazać adres karty Ethernet, na którą datagram ten zostanie dostarczony w celu jego późniejszego przetworzenia przez protokół IP znajdujący się wyżej na stosie. Adres IP zawarty w nagłówku datagramu adresuje interfejs IP dowolnego węzła sieci i nie zawiera żadnego wskazania fizycznego medium transmisyjnego, do którego ten interfejs jest podłączony, a tym bardziej fizycznego adresu urządzenia (jeśli istnieje), za pośrednictwem którego ten interfejs interfejs komunikuje się z otoczeniem.
Wyszukiwanie odpowiedniego adresu Ethernet przy użyciu podanego adresu IP realizowane jest przez protokół ARP, który działa na poziomie dostępu do mediów transmisyjnych. Protokół utrzymuje dynamiczną tablicę arp w pamięci RAM w celu buforowania otrzymanych informacji. Protokół działa w następujący sposób.
Z warstwy intersieci odbierany jest datagram IP, który jest przesyłany do kanału fizycznego (Ethernet) i wraz z datagramem przesyłany jest m.in. adres IP hosta docelowego. Jeśli tablica arp nie zawiera wpisu adresu Ethernet odpowiadającego żądanemu adresowi IP, moduł arp umieszcza datagram w kolejce i wysyła żądanie rozgłoszenia. Żądanie jest odbierane przez wszystkie węzły podłączone do tej sieci; węzeł, który rozpoznał swój adres IP, wysyła odpowiedź arp z wartością swojego adresu Ethernet. Odebrane dane są wprowadzane do tabeli, oczekujący datagram jest usuwany z kolejki i przesyłany w celu enkapsulacji do ramki Ethernet w celu późniejszego przesłania kanałem fizycznym.
Żądanie lub odpowiedź ARP jest umieszczane w ramce Ethernet bezpośrednio po nagłówku ramki.
Formaty żądania i odpowiedzi są takie same i różnią się jedynie kodem operacji (odpowiednio kod operacji 1 i 2).
Chociaż ARP został zaprojektowany specjalnie dla Ethernetu, protokół może obsługiwać różne typy mediów fizycznych (pole „Typ sprzętu”, wartość 1 odpowiada Ethernet), a także różne typy obsługiwanych protokołów (pole „Typ protokołu”). )”, wartość 2048 odpowiada IP). Pola H-len i P-len zawierają odpowiednio długości adresu fizycznego i adresu „protokołu” w oktetach. Dla Ethernetu H-len=6, dla IP P-len=4.
Pola „Źródłowy adres sprzętowy” i „Adres protokołu źródłowego” zawierają adres fizyczny (Ethernet) i „protokół” (IP) nadawcy. Pola „Docelowy adres sprzętowy” i „Docelowy adres protokołu” zawierają odpowiednie adresy odbiorców. Podczas wysyłania żądania pole „Docelowy adres sprzętowy” jest inicjalizowane zerami, a pole „Adres docelowy” nagłówka ramki Ethernet jest ustawiane na adres rozgłoszeniowy.
2.6.1. ARP dla datagramów przeznaczonych dla innej sieci
Datagram skierowany do sieci zewnętrznej (innej) musi zostać przesłany do routera. Załóżmy, że host A wysyła datagram do hosta B za pośrednictwem routera G. Mimo że datagram wysłany z A ma adres IP B w nagłówku docelowym, ramka Ethernet zawierająca datagram musi zostać dostarczona do routera. Osiąga się to poprzez fakt, że moduł IP wywołując moduł ARP przesyła do niego wraz z datagramem adres routera wyodrębniony z tablicy tras jako adres IP hosta docelowego. Zatem datagram o adresie B jest hermetyzowany w ramce o adresie MAC G:
Moduł Ethernet na routerze G odbiera tę ramkę z sieci, ponieważ ramka jest do niego adresowana, wyodrębnia dane (czyli datagram) z ramki i wysyła je do modułu IP w celu przetworzenia. Moduł IP wykrywa, że datagram nie jest adresowany do niego, ale do hosta B, i na podstawie swojej tabeli tras określa, dokąd powinien zostać przekazany. Następnie datagram jest ponownie obniżany na niższy poziom, do odpowiedniego interfejsu fizycznego, do którego przesyłany jest adres kolejnego routera wyodrębniony z tablicy tras jako adres IP hosta docelowego lub od razu adres hosta B, jeśli router G może dostarczyć datagram bezpośrednio do niego.
2.6.2. Serwer proxy ARP
Odpowiedź ARP niekoniecznie musi zostać wysłana przez żądany węzeł; zamiast tego może ją wysłać inny węzeł. Mechanizm ten nazywa się proxy ARP.
Spójrzmy na przykład (ryc. 2.6.1). Zdalny host A jest podłączony za pośrednictwem linii telefonicznej do sieci 194.84.124.0/24 za pośrednictwem serwera dostępu G. Sieć 194.84.124.0 to warstwa fizyczna Ethernet. Serwer G nadaje hostowi A adres IP 194.84.124.30, który należy do sieci 194.84.124.0. Dlatego każdy węzeł w tej sieci, na przykład host B, uważa, że może bezpośrednio wysłać datagram do hosta A, ponieważ znajdują się one w tej samej sieci IP.
Ryż. 2.6.1. Serwer proxy ARP
Moduł IP hosta B wywołuje moduł ARP w celu ustalenia adresu fizycznego A. Jednak zamiast A (który oczywiście nie może odpowiedzieć, ponieważ nie jest fizycznie podłączony do sieci Ethernet), odpowiada serwer G, który zwraca swoje Adres Ethernet jako adres fizyczny hosta A. Następnie B wysyła, a G odbiera ramkę zawierającą datagram dla A, który G wysyła do miejsca docelowego przez obwód komutowany.