Рекурсия в логике. Рекурсия в программировании
Функций: рекурсивно заданная функция в своём определении содержит себя, в частности, рекурсивной является функция, заданная рекуррентной формулой . Таким образом, можно одним выражением дать бесконечный набор способов вычисления функции, определить множество объектов через самого себя с использованием ранее заданных частных определений.
Данные
Struct element_of_list { element_of_list * next; /* ссылка на следующий элемент того же типа */ int data; /* некие данные */ } ;
Рекурсивная структура данных зачастую обуславливает применение рекурсии для обработки этих данных.
В физике
Классическим примером бесконечной рекурсии являются два поставленные друг напротив друга зеркала : в них образуются два коридора из уменьшающихся отражений зеркал.
Другим примером бесконечной рекурсии является эффект самовозбуждения (положительной обратной связи) у электронных схем усиления, когда сигнал с выхода попадает на вход, усиливается, снова попадает на вход схемы и снова усиливается. Усилители, для которых такой режим работы является штатным, называются автогенераторы .
В лингвистике
Способность языка порождать вложенные предложения и конструкции. Базовое предложение «кошка съела мышь » может быть за счёт рекурсии расширено как Ваня догадался, что кошка съела мышь , далее как Катя знает, что Ваня догадался, что кошка съела мышь и так далее. Рекурсия считается одной из лингвистических универсалий , то есть свойственна любому естественному языку. Однако, в последнее время активно обсуждается возможное отсутствие рекурсии в одном из языков Амазонии - пираха, которое отмечает лингвист Дэниэл Эверетт (англ. ) .
В культуре
Большая часть шуток о рекурсии касается бесконечной рекурсии, в которой нет условия выхода, например, известно высказывание: «чтобы понять рекурсию, нужно сначала понять рекурсию» .
Весьма популярна шутка о рекурсии, напоминающая словарную статью:
Несколько рассказов Станислава Лема посвящены (возможным) казусам при бесконечной рекурсии:
- рассказ про Йона Тихого «Путешествие четырнадцатое» из «Звёздных дневников Ийона Тихого », в котором герой последовательно переходит от статьи о сепульках к статье о сепуляции, оттуда к статье о сепулькариях, в которой снова стоит отсылка к статье «сепульки»:
Нашёл следующие краткие сведения:
«СЕПУЛЬКИ - важный элемент цивилизации ардритов (см.) с планеты Энтеропия (см.). См. СЕПУЛЬКАРИИ».
Я последовал этому совету и прочёл:
«СЕПУЛЬКАРИИ - устройства для сепуления (см.)».
Я поискал «Сепуление»; там значилось:
«СЕПУЛЕНИЕ - занятие ардритов (см.) с планеты Энтеропия (см.). См. СЕПУЛЬКИ».Лем С. «Звёздные дневники Ийона Тихого. Путешествие четырнадцатое.»
- Рассказ из «Кибериады» о разумной машине, которая обладала достаточным умом и ленью, чтобы для решения поставленной задачи построить себе подобную, и поручить решение ей (итогом стала бесконечная рекурсия, когда каждая новая машина строила себе подобную и передавала задание ей).
- Рекурсивные акронимы : GNU (GNU Not Unix), PHP (PHP: Hypertext Preprocessor) и т. д.
См. также
- Возвратная последовательность
Примечания
Wikimedia Foundation . 2010 .
- Видеопамять
- Электромагнитное излучение
Смотреть что такое "Рекурсия" в других словарях:
рекурсия - возвращение, повторение Словарь русских синонимов. рекурсия сущ., кол во синонимов: 1 … Словарь синонимов
рекурсия - — [] рекурсия В общем смысле вычисление функции по определенному алгоритму. Примерами таких алгоритмов являются рекуррентные формулы, выводящие вычисление заданного члена… … Справочник технического переводчика
Рекурсия - в общем смысле вычисление функции по определенному алгоритму. Примерами таких алгоритмов являются рекуррентные формулы, выводящие вычисление заданного члена последовательности (чаще всего числовой) из вычисления нескольких предыдущих … Экономико-математический словарь
Рекурсия - Терапевтический паттерн, когда берётся некоторое условие или критерий, сформулированный в исходном утверждении, и применяется к самому утверждению. Например: У меня нет времени. Сколько времени вам пришлось потратить, чтобы убедиться, что у вас… … Большая психологическая энциклопедия
РЕКУРСИЯ - способ определения функций, являющийся объектом изучения в теории алгоритмов и других разделах математич. логики. Этот способ давно применяется в арифметике для определения числовых последовательностей (прогрессии, чисел Фибоначчи и пр.).… … Математическая энциклопедия
рекурсия - (фон.) (лат. recursio возвращение). Одна из трех фаз артикуляции звуков, отступ. Перевод органов речи в спокойное состояние или приступ к артикуляции следующего звука. В слове отдых рекурсия (отступ) при артикулировании [т] может наложиться на… … Словарь лингвистических терминов Т.В. Жеребило
Энциклопедичный YouTube
-
1 / 5
В математике рекурсия имеет отношение к методу определения функций и числовых рядов: рекурсивно заданная функция определяет своё значение через обращение к себе самой с другими аргументами. При этом возможно два варианта:
e = 2 + 2 2 + 3 3 + 4 4 + … = 2 + f (2) {\displaystyle e=2+{\cfrac {2}{2+{\cfrac {3}{3+{\cfrac {4}{4+\ldots }}}}}}\;=2+f(2)} , где f (n) = n n + f (n + 1) {\displaystyle f(n)={\cfrac {n}{n+f(n+1)}}} Прямой расчёт по приведённой формуле вызовет бесконечную рекурсию, но можно доказать, что значение f(n) при возрастании n стремится к единице (поэтому, несмотря на бесконечность ряда, значение числа Эйлера конечно). Для приближённого вычисления значения e достаточно искусственно ограничить глубину рекурсии некоторым наперёд заданным числом и по достижении его использовать вместо f (n) {\displaystyle f(n)} единицу.Другим примером рекурсии в математике является числовой ряд, заданный рекуррентной формулой , когда каждый следующий член ряда вычисляется как результат функции от n предыдущих членов. Таким образом с помощью конечного выражения (представляющего собой совокупность реккурентной формулы и набора значений для первых n членов ряда) может даваться определение бесконечного ряда.
Struct element_of_list { element_of_list * next ; /* указатель на следующий элемент того же типа */ int data ; /* некие данные */ };
Поскольку бесконечное число вложенных объектов невозможно разместить в конечной памяти, в реальности такие рекурсивно-определённые структуры всегда конечны. В заключительных (терминальных) ячейках обычно записываются пустые указатели, являющиеся одновременно флагами, указывающими программе, обрабатывающей структуру, что достигнут её конец.
Рекурсия — это свойство объекта подражать самому себе. Объект является рекурсивным если его части выглядят также как весь объект. Рекурсия очень широко применяется в математике и программировании:
- структуры данных:
- граф (в частности деревья и списки) можно рассматривать как совокупность отдельного узла и подграфа (меньшего графа);
- строка состоит из первого символа и подстроки (меньшей строки);
- шаблоны проектирования, например . Объект декоратора может включать в себя другие объекты, также являющиеся декораторами. Детально рекурсивные шаблоны изучил Мак-Колм Смит, выделив в своей книге общий шаблон проектирования — Recursion ;
- рекурсивные функции (алгоритмы) выполняют вызов самих себя.
Статья посвящена анализу трудоемкости рекурсивных алгоритмов, приведены необходимые математические сведения, рассмотрены примеры. Кроме того, описана возможность замены рекурсии циклом, хвостовая рекурсия.
Примеры рекурсивных алгоритмов
Рекурсивный алгоритм всегда разбивает задачу на части, которые по своей структуре являются такими же как исходная задача, но более простыми. Для решения подзадач функция вызывается рекурсивно, а их результаты каким-либо образом объединяются. Разделение задачи происходит лишь тогда, когда ее не удается решить сразу (она является слишком сложной).
Например, задачу обработки массива нередко можно свести к обработке его частей. Деление на части выполняется до тех пор, пока они не станут элементарными, т.е. достаточно простыми чтобы получить результат без дальнейшего упрощения.
Поиск элемента массива
начало; search(array, begin, end, element) ; выполняет поиск элемента со значением element в массиве array между индексами begin и end если begin > end результат:= false; элемент не найден иначе если array = element результат:= true; элемент найден иначе результат:= search(array, begin+1, end, element) конец; вернуть результатАлгоритм делит исходный массив на две части — первый элемент и массив из остальных элементов. Выделяется два простых случая, когда разделение не требуется — обработаны все элементы или первый элемент является искомым.
В алгоритме поиска разделять массив можно было бы и иначе (например пополам), но это не сказалось бы на эффективности. Если массив отсортирован — то его деление пополам целесообразно, т.к. на каждом шаге количество обрабатываемых данных можно сократить на половину.
Двоичный поиск в массиве
Двоичный поиск выполняется над отсортированным массивом. На каждом шаге искомый элемент сравнивается со значением, находящимся посередине массива. В зависимости от результатов сравнения либо левая, либо правая части могут быть «отброшены».
Начало; binary_search(array, begin, end, element) ; выполняет поиск элемента со значением element ; в массиве упорядоченном по возрастанию массиве array ; между индексами begin и end если begin > end конец; вернуть false - элемент не найден mid:= (end + begin) div 2; вычисление индекса элемента посередине рассматриваемой части массива если array = element конец; вернуть true (элемент найден) если array < element результат:= binary_search(array, mid+1, end, element) иначе результат:= binary_search(array, begin, mid, element) конец; вернуть результат
Вычисление чисел Фибоначчи
Числа Фибоначчи определяются рекуррентным выражением, т.е. таким, что вычисление элемента которого выражается из предыдущих элементов: \(F_0 = 0, F_1 = 1, F_n = F_{n-1} + F_{n-2}, n > 2\).
Начало; fibonacci(number) если number = 0 конец; вернуть 0 если number = 1 конец; вернуть 1 fib_1:= fibonacci(number-1) fib_2:= fibonacci(number-2) результат:= fib_1 + fib_2 конец; вернуть результат
Быстрая сортировка (quick sort)
Алгоритм быстрой сортировки на каждом шаге выбирает один из элементов (опорный) и относительно него разделяет массив на две части, которые обрабатываются рекурсивно. В одну часть помещаются элементы меньше опорного, а в другую — остальные.
Блок-схема алгоритма быстрой сортировки
Сортировка слиянием (merge sort)
В основе алгоритма сортировки слиянием лежит возможность быстрого объединения упорядоченных массивов (или списков) так, чтобы результат оказался упорядоченным. Алгоритм разделяет исходный массив на две части произвольным образом (обычно пополам), рекурсивно сортирует их и объединяет результат. Разделение происходит до тех пор, пока размер массива больше единицы, т.к. пустой массив и массив из одного элемента всегда отсортированы.
 Блок схема сортировки слиянием
Блок схема сортировки слиянием На каждом шаге слияния из обоих списков выбирается первый необработанный элемент. Элементы сравниваются, наименьший из них добавляется к результату и помечается как обработанный. Слияние происходит до тех пор, пока один из списков не окажется пуст.
Начало; merge(Array1, Size1, Array2, Size2) ; исходные массивы упорядочены; в результат формируется упорядоченный массив длины Size1+Size2 i:= 0, j:= 0 вечный_цикл если i >= Size1 дописать элементы от j до Size2 массива Array2 в конец результата выход из цикла если j >= Size2 дописать элементы от i до Size1 массива Array1 в конец результата выход из цикла если Array1[i] < Array2[j] результат := Array1[i] i:= i + 1 иначе (если Array1[i] >= Array2[j]) результат := Array2[j] j:= j + 1 конец; вернуть результат
Анализ рекурсивных алгоритмов
При рассчитывается трудоемкость итераций и их количество в наихудшем, наилучшем и среднем случаях . Однако не получится применить такой подход к рекурсивной функции, т.к. в результате будет получено рекуррентное соотношение. Например, для функции поиска элемента в массиве:
\(
\begin{equation*}
T^{search}_n = \begin{cases}
\mathcal{O}(1) \quad &\text{$n = 0$} \\
\mathcal{O}(1) + \mathcal{O}(T^{search}_{n-1}) \quad &\text{$n > 0$}
\end{cases}
\end{equation*}
\)Рекуррентные отношения не позволяют нам оценить сложность — мы не можем их просто так сравнивать, а значит, и сравнивать эффективность соответствующих алгоритмов. Необходимо получить формулу, которая опишет рекуррентное отношение — универсальным способом сделать это является подбор формулы при помощи метода подстановки, а затем доказательство соответствия формулы отношению методом математической индукции.
Метод подстановки (итераций)
Заключается в последовательной замене рекуррентной части в выражении для получения новых выражений. Замена производится до тех пор, пока не получится уловить общий принцип и выразить его в виде нерекуррентной формулы. Например для поиска элемента в массиве:
\(
T^{search}_n = \mathcal{O}(1) + \mathcal{O}(T^{search}_{n-1}) =
2\times\mathcal{O}(1) + \mathcal{O}(T^{search}_{n-2}) =
3\times\mathcal{O}(1) + \mathcal{O}(T^{search}_{n-3})
\)Можно предположить, что \(T^{search}_n = T^{search}_{n-k} + k\times\mathcal{O}(1)\), но тогда \(T^{search}_n = T^{search}_{0} + n\times\mathcal{O}(1) = \mathcal{O}(n)\).
Мы вывели формулу, однако первый шаг содержит предположение, т.е. не имеется доказательства соответствия формулы рекуррентному выражению — получить доказательство позволяет метод математической индукции.
Метод математической индукции
Позволяет доказать истинность некоторого утверждения (\(P_n\)), состоит из двух шагов:
- доказательство утверждения для одного или нескольких частных случаев \(P_0, P_1, …\);
- из истинности \(P_n\) (индуктивная гипотеза) и частных случаев выводится доказательство \(P_{n+1}\).
Докажем корректность предположения, сделанного при оценки трудоемкости функции поиска (\(T^{search}_n = (n+1)\times\mathcal{O}(1)\)):
- \(T^{search}_{1} = 2\times\mathcal{O}(1)\) верно из условия (можно подставить в исходную рекуррентную формулу);
- допустим истинность \(T^{search}_n = (n+1)\times\mathcal{O}(1)\);
- требуется доказать, что \(T^{search}_{n+1} = ((n+1)+1)\times\mathcal{O}(1) = (n+2)\times\mathcal{O}(1)\);
- подставим \(n+1\) в рекуррентное соотношение: \(T^{search}_{n+1} = \mathcal{O}(1) + T^{search}_n\);
- в правой части выражения возможно произвести замену на основании индуктивной гипотезы: \(T^{search}_{n+1} = \mathcal{O}(1) + (n+1)\times\mathcal{O}(1) = (n+2)\times\mathcal{O}(1)\);
- утверждение доказано.
Часто, такое доказательство — достаточно трудоемкий процесс, но еще сложнее выявить закономерность используя метод подстановки. В связи с этим применяется, так называемый, общий метод .
Общий (основной) метод решения рекуррентных соотношений
Общий метод не является универсальным, например с его помощью невозможно провести оценку сложности приведенного выше алгоритма вычисления чисел Фибоначчи. Однако, он применим для всех случаев использования подхода «разделяй и властвуй» :
\(T_n = a\cdot T(\frac{n}{b})+f_n; a, b = const, a \geq 1, b > 1, f_n > 0, \forall n\).
Уравнения такого вида получаются если исходная задача разделяется на a подзадач, каждая из которых обрабатывает \(\frac{n}{b}\) элементов. \(f_n\) — трудоемкость операций разбиения задачи на части и комбинирование решений. Помимо вида соотношения, общий метод накладывает ограничения на функцию \(f_n\), выделяя три случая:
- \(\exists \varepsilon > 0: f_n = \mathcal{O}(n^{\log_b a — \varepsilon}) \Rightarrow T_n = \Theta(n^{\log_b a})\);
- \(f_n = \Theta(n^{\log_b a}) \Rightarrow T_n = \Theta(n^{\log_b a} \cdot \log n)\);
- \(\exists \varepsilon > 0, c < 1: f_n = \Omega(n^{\log_b a + \varepsilon}), f_{\frac{n}{b}} \leq c \cdot f_n \Rightarrow T_n = \Theta(f_n)\).
Правильность утверждений для каждого случая доказана формально . Задача анализа рекурсивного алгоритма теперь сводится к определению случая основной теоремы, которому соответствует рекуррентное соотношение.
Анализ алгоритма бинарного поиска
Алгоритм разбивает исходные данные на 2 части (b = 2), но обрабатывает лишь одну из них (a = 1), \(f_n = 1\). \(n^{\log_b a} = n^{\log_2 1} = n^0 = 1\). Функция разделения задачи и компоновки результата растет с той же скоростью, что и \(n^{\log_b a}\), значит необходимо использовать второй случай теоремы:
\(T^{binarySearch}_n = \Theta(n^{\log_b a} \cdot \log n) = \Theta(1 \cdot \log n) = \Theta(\log n)\).
Анализ алгоритма поиска
Рекурсивная функция разбивает исходную задачу на одну подзадачу (a = 1), данные делятся на одну часть (b = 1). Мы не можем использовать основную теорему для анализа этого алгоритма, т.к. не выполняется условие \(b > 1\).
Для проведения анализа может использоваться метод подстановки или следующие рассуждения: каждый рекурсивный вызов уменьшает размерность входных данных на единицу, значит всего их будет n штук, каждый из которых имеет сложность \(\mathcal{O}(1)\). Тогда \(T^{search}_n = n \cdot \mathcal{O}(1) = \mathcal{O}(n)\).
Анализ алгоритма сортировки слиянием
Исходные данные разделяются на две части, обе из которых обрабатываются: \(a = 2, b = 2, n^{\log_b a} = n\).
При обработке списка, разделение может потребовать выполнения \(\Theta(n)\) операций, а для массива — выполняется за постоянное время (\(\Theta(1)\)). Однако, на соединение результатов в любом случае будет затрачено \(\Theta(n)\), поэтому \(f_n = n\).
Используется второй случай теоремы: \(T^{mergeSort}_n = \Theta(n^{\log_b a} \cdot \log n) = \Theta(n \cdot \log n)\).
Анализ трудоемкости быстрой сортировки
В лучшем случае исходный массив разделяется на две части, каждая из которых содержит половину исходных данных. Разделение потребует выполнения n операций. Трудоемкость компоновки результата зависит от используемых структур данных — для массива \(\mathcal{O}(n)\), для связного списка \(\mathcal{O}(1)\). \(a = 2, b = 2, f_n = b\), значит сложность алгоритма будет такой же как у сортировки слиянием: \(T^{quickSort}_n = \mathcal{O}(n \cdot \log n)\).
Однако, в худшем случае в качестве опорного будет постоянно выбираться минимальный или максимальный элемент массива. Тогда \(b = 1\), а значит, мы опять не можем использовать основную теорему. Однако, мы знаем, что в этом случае будет выполнено n рекурсивных вызовов, каждый из которых выполняет разделение массива на части (\(\mathcal{O}(n)\)) — значит сложность алгоритма \(T^{quickSort}_n = \mathcal{O}(n^2)\).
При анализе быстрой сортировки методом подстановки, пришлось бы также рассматривать отдельно наилучший и наихудший случаи.
Хвостовая рекурсия и цикл
Анализ трудоемкости рекурсивных функций значительно сложнее аналогичной оценки циклов, но основной причиной, по которой циклы предпочтительнее являются высокие затраты на вызов функции.
После вызова управление передается другой функции. Для передачи управления достаточно изменить значение регистра программного счетчика, в котором процессор хранит номер текущей выполняемой команды — аналогичным образом передается управление ветвям алгоритма, например, при использовании условного оператора. Однако, вызов — это не только передача управления, ведь после того, как вызванная функция завершит вычисления, она должна вернуть управление в точку, и которой осуществлялся вызов, а также восстановить значения локальных переменных, которые существовали там до вызова.
Для реализации такого поведения используется стек (стек вызовов, call stack) — в него помещаются номер команды для возврата и информация о локальных переменных. Стек не является бесконечным, поэтому рекурсивные алгоритмы могут приводить к его переполнению, в любом случае на работу с ним может уходить значительная часть времени.
В ряде случаев рекурсивную функцию достаточно легко заменить циклом, например, рассмотренные выше . В некоторых случаях требуется более творческий подход, но чаще всего такая замена оказывается возможной. Кроме того, существует особый вид рекурсии, когда рекурсивный вызов является последней операцией, выполняемой функцией. Очевидно, что в таком случае вызывающая функция не будет каким-либо образом изменять результат, а значит ей нет смысла возвращать управление. Такая рекурсия называется хвостовой — компиляторы автоматически заменяют ее циклом.
Зачастую сделать рекурсию хвостовой помогает метод накапливающего параметра , который заключается в добавлении функции дополнительного аргумента-аккумулятора, в котором накапливается результат. Функция выполняет вычисления с аккумулятором до рекурсивного вызова. Хорошим примером использования такой техники служит функция вычисления факториала:
\(fact_n = n \cdot fact(n-1) \\
fact_3 = 3 \cdot fact_2 = 3 \cdot (2 \cdot fact_1) = 3\cdot (2 \cdot (1 \cdot fact_0)) = 6 \\
fact_n = factTail_{n, 1} \\
\\
factTail_{n, accumulator} = factTail(n-1, accumulator \cdot n)\\
factTail_{3, 1} = factTail_{2, 3} = factTail_{1, 6} = factTail_{0, 6} = 6
\)В качестве более сложного примера рассмотрим функцию вычисления чисел Фибоначчи. Основная функция вызывает вспомогательную,использующую метод накапливающего параметра, при этом передает в качестве аргументов начальное значение итератора и два аккумулятора (два предыдущих числа Фибоначчи).
Начало; fibonacci(number) вернуть fibonacci(number, 1, 1, 0) конец начало; fibonacci(number, iterator, fib1, fib2) если iterator == number вернуть fib1 вернуть fibonacci(number, iterator + 1, fib1 + fib2, fib1) конец
Функция с накапливающим параметром возвращает накопленный результат, если рассчитано заданное количество чисел, в противном случае — увеличивает счетчик, рассчитывает новое число Фибоначчи и производит рекурсивный вызов. Оптимизирующие компиляторы могут обнаружить, что результат вызова функции без изменений передается на выход функции и заменить его циклом. Такой прием особенно актуален в функциональных и логических языках программирования, т.к. в них программист не может явно использовать циклические конструкции.
Литература
- Многопоточный сервер Qt. Пул потоков. Паттерн Decorator[Электронный ресурс] – режим доступа : https://сайт/archives/1390. Дата обращения: 21.02.2015.
- Джейсон Мак-Колм Смит : Пер. с англ. - М. : ООО “И.Д. Вильямс”, 2013. - 304 с.
- Скиена С. Алгоритмы. Руководство по разработке.-2-е изд.: пер. с англ.-СПб.:БХВ-Петербург, 2011.-720с.: ил.
- Васильев В. С. Анализ сложности алгоритмов. Примеры [Электронный ресурс] – режим доступа: https://сайт/archives/1660. Дата обращения: 21.02.2015.
- А.Ахо, Дж.Хопкрофт, Дж.Ульман, Структуры данных и алгоритмы, М., Вильямс, 2007.
- Миллер, Р. Последовательные и параллельные алгоритмы: Общий подход / Р. Миллер, Л. Боксер; пер. с англ. - М. : БИНОМ. Лаборатория знаний, 2006. - 406 с.
- Сергиевский Г.М. Функциональное и логическое программирование: учеб. пособие для студентов высш. учеб. заведений / Г.М. Сергиевский, Н.Г. Волченков. - М.: Издательский центр «Академия», 2010.- 320с.
Рекурсией называется ситуация, когда подпрограмма вызывает сама себя. Впервые сталкиваясь с такой алгоритмической конструкцией, большинство людей испытывает определенные трудности, однако немного практики и рекурсия станет понятным и очень полезным инструментом в вашем программистском арсенале.
1. Сущность рекурсии
Процедура или функция может содержать вызов других процедур или функций. В том числе процедура может вызвать саму себя. Никакого парадокса здесь нет – компьютер лишь последовательно выполняет встретившиеся ему в программе команды и, если встречается вызов процедуры, просто начинает выполнять эту процедуру. Без разницы, какая процедура дала команду это делать.
Пример рекурсивной процедуры:
Procedure Rec(a: integer); begin if a>
Рассмотрим, что произойдет, если в основной программе поставить вызов, например, вида Rec(3). Ниже представлена блок-схема, показывающая последовательность выполнения операторов.
Рис. 1. Блок схема работы рекурсивной процедуры.
Процедура Rec вызывается с параметром a = 3. В ней содержится вызов процедуры Rec с параметром a = 2. Предыдущий вызов еще не завершился, поэтому можете представить себе, что создается еще одна процедура и до окончания ее работы первая свою работу не заканчивает. Процесс вызова заканчивается, когда параметр a = 0. В этот момент одновременно выполняются 4 экземпляра процедуры. Количество одновременно выполняемых процедур называют глубиной рекурсии .
Четвертая вызванная процедура (Rec(0)) напечатает число 0 и закончит свою работу. После этого управление возвращается к процедуре, которая ее вызвала (Rec(1)) и печатается число 1. И так далее пока не завершатся все процедуры. Результатом исходного вызова будет печать четырех чисел: 0, 1, 2, 3.
Еще один визуальный образ происходящего представлен на рис. 2.

Рис. 2. Выполнение процедуры Rec с параметром 3 состоит из выполнения процедуры Rec с параметром 2 и печати числа 3. В свою очередь выполнение процедуры Rec с параметром 2 состоит из выполнения процедуры Rec с параметром 1 и печати числа 2. И т. д.
В качестве самостоятельного упражнения подумайте, что получится при вызове Rec(4). Также подумайте, что получится при вызове описанной ниже процедуры Rec2(4), где операторы поменялись местами.
Procedure Rec2(a: integer); begin writeln(a); if a>0 then Rec2(a-1); end;
Обратите внимание, что в приведенных примерах рекурсивный вызов стоит внутри условного оператора. Это необходимое условие для того, чтобы рекурсия когда-нибудь закончилась. Также обратите внимание, что сама себя процедура вызывает с другим параметром, не таким, с каким была вызвана она сама. Если в процедуре не используются глобальные переменные, то это также необходимо, чтобы рекурсия не продолжалась до бесконечности.
Возможна чуть более сложная схема: функция A вызывает функцию B, а та в свою очередь вызывает A. Это называется сложной рекурсией . При этом оказывается, что описываемая первой процедура должна вызывать еще не описанную. Чтобы это было возможно, требуется использовать .
Procedure A(n: integer); {Опережающее описание (заголовок) первой процедуры} procedure B(n: integer); {Опережающее описание второй процедуры} procedure A(n: integer); {Полное описание процедуры A} begin writeln(n); B(n-1); end; procedure B(n: integer); {Полное описание процедуры B} begin writeln(n); if n
Опережающее описание процедуры B позволяет вызывать ее из процедуры A. Опережающее описание процедуры A в данном примере не требуется и добавлено из эстетических соображений.
Если обычную рекурсию можно уподобить уроборосу (рис. 3), то образ сложной рекурсии можно почерпнуть из известного детского стихотворения, где «Волки с перепуга, скушали друг друга». Представьте себе двух съевших друг друга волков, и вы поймете сложную рекурсию.

Рис. 3. Уроборос – змей, пожирающий свой хвост. Рисунок из алхимического трактата «Synosius» Теодора Пелеканоса (1478г).

Рис. 4. Сложная рекурсия.
3. Имитация работы цикла с помощью рекурсии
Если процедура вызывает сама себя, то, по сути, это приводит к повторному выполнению содержащихся в ней инструкций, что аналогично работе цикла. Некоторые языки программирования не содержат циклических конструкций вовсе, предоставляя программистам организовывать повторения с помощью рекурсии (например, Пролог, где рекурсия - основной прием программирования).
Для примера сымитируем работу цикла for. Для этого нам потребуется переменная счетчик шагов, которую можно реализовать, например, как параметр процедуры.
Пример 1.
Procedure LoopImitation(i, n: integer); {Первый параметр – счетчик шагов, второй параметр – общее количество шагов} begin writeln("Hello N ", i); //Здесь любые инструкции, которые будут повторятся if i
Результатом вызова вида LoopImitation(1, 10) станет десятикратное выполнение инструкций с изменением счетчика от 1 до 10. В данном случае будет напечатано:
Hello N 1
Hello N 2
…
Hello N 10Вообще, не трудно видеть, что параметры процедуры это пределы изменения значений счетчика.
Можно поменять местами рекурсивный вызов и подлежащие повторению инструкции, как в следующем примере.
Пример 2.
Procedure LoopImitation2(i, n: integer); begin if i
В этом случае, прежде чем начнут выполняться инструкции, произойдет рекурсивный вызов процедуры. Новый экземпляр процедуры также, прежде всего, вызовет еще один экземпляр и так далее, пока не дойдем до максимального значения счетчика. Только после этого последняя из вызванных процедур выполнит свои инструкции, затем выполнит свои инструкции предпоследняя и т.д. Результатом вызова LoopImitation2(1, 10) будет печать приветствий в обратном порядке:
Hello N 10
…
Hello N 1Если представить себе цепочку из рекурсивно вызванных процедур, то в примере 1 мы проходим ее от раньше вызванных процедур к более поздним. В примере 2 наоборот от более поздних к ранним.
Наконец, рекурсивный вызов можно расположить между двумя блоками инструкций. Например:
Procedure LoopImitation3(i, n: integer); begin writeln("Hello N ", i); {Здесь может располагаться первый блок инструкций} if i
Здесь сначала последовательно выполнятся инструкции из первого блока затем в обратном порядке инструкции второго блока. При вызове LoopImitation3(1, 10) получим:
Hello N 1
…
Hello N 10
Hello N 10
…
Hello N 1Потребуется сразу два цикла, чтобы сделать то же самое без рекурсии.
Тем, что выполнение частей одной и той же процедуры разнесено по времени можно воспользоваться. Например:
Пример 3: Перевод числа в двоичную систему.
Получение цифр двоичного числа, как известно, происходит с помощью деления с остатком на основание системы счисления 2. Если есть число , то его последняя цифра в его двоичном представлении равна
Взяв же целую часть от деления на 2:
получим число, имеющее то же двоичное представление, но без последней цифры. Таким образом, достаточно повторять приведенные две операции пока поле очередного деления не получим целую часть равную 0. Без рекурсии это будет выглядеть так:
While x>0 do begin c:=x mod 2; x:=x div 2; write(c); end;
Проблема здесь в том, что цифры двоичного представления вычисляются в обратном порядке (сначала последние). Чтобы напечатать число в нормальном виде придется запомнить все цифры в элементах массива и выводить в отдельном цикле.
С помощью рекурсии нетрудно добиться вывода в правильном порядке без массива и второго цикла. А именно:
Procedure BinaryRepresentation(x: integer); var c, x: integer; begin {Первый блок. Выполняется в порядке вызова процедур} c:= x mod 2; x:= x div 2; {Рекурсивный вызов} if x>0 then BinaryRepresentation(x); {Второй блок. Выполняется в обратном порядке} write(c); end;
Вообще говоря, никакого выигрыша мы не получили. Цифры двоичного представления хранятся в локальных переменных, которые свои для каждого работающего экземпляра рекурсивной процедуры. То есть, память сэкономить не удалось. Даже наоборот, тратим лишнюю память на хранение многих локальных переменных x. Тем не менее, такое решение кажется мне красивым.
4. Рекуррентные соотношения. Рекурсия и итерация
Говорят, что последовательность векторов задана рекуррентным соотношением, если задан начальный вектор и функциональная зависимость последующего вектора от предыдущего
Простым примером величины, вычисляемой с помощью рекуррентных соотношений, является факториал
Очередной факториал можно вычислить по предыдущему как:
Введя обозначение , получим соотношение:
Вектора из формулы (1) можно интерпретировать как наборы значений переменных. Тогда вычисление требуемого элемента последовательности будет состоять в повторяющемся обновлении их значений. В частности для факториала:
X:= 1; for i:= 2 to n do x:= x * i; writeln(x);
Каждое такое обновление (x:= x * i) называется итерацией , а процесс повторения итераций – итерированием .
Обратим, однако, внимание, что соотношение (1) является чисто рекурсивным определением последовательности и вычисление n-го элемента есть на самом деле многократное взятие функции f от самой себя:
В частности для факториала можно написать:
Function Factorial(n: integer): integer; begin if n > 1 then Factorial:= n * Factorial(n-1) else Factorial:= 1; end;
Следует понимать, что вызов функций влечет за собой некоторые дополнительные накладные расходы, поэтому первый вариант вычисления факториала будет несколько более быстрым. Вообще итерационные решения работают быстрее рекурсивных.
Прежде чем переходить к ситуациям, когда рекурсия полезна, обратим внимание еще на один пример, где ее использовать не следует.
Рассмотрим частный случай рекуррентных соотношений, когда следующее значение в последовательности зависит не от одного, а сразу от нескольких предыдущих значений. Примером может служить известная последовательность Фибоначчи, в которой каждый следующий элемент есть сумма двух предыдущих:
При «лобовом» подходе можно написать:
Function Fib(n: integer): integer; begin if n > 1 then Fib:= Fib(n-1) + Fib(n-2) else Fib:= 1; end;
Каждый вызов Fib создает сразу две копии себя, каждая из копий – еще две и т.д. Количество операций растет с номером n экспоненциально, хотя при итерационном решении достаточно линейного по n количества операций.
На самом деле, приведенный пример учит нас не КОГДА рекурсию не следует использовать, а тому КАК ее не следует использовать. В конце концов, если существует быстрое итерационное (на базе циклов) решение, то тот же цикл можно реализовать с помощью рекурсивной процедуры или функции. Например:
// x1, x2 – начальные условия (1, 1) // n – номер требуемого числа Фибоначчи function Fib(x1, x2, n: integer): integer; var x3: integer; begin if n > 1 then begin x3:= x2 + x1; x1:= x2; x2:= x3; Fib:= Fib(x1, x2, n-1); end else Fib:= x2; end;
И все же итерационные решения предпочтительны. Спрашивается, когда же в таком случае, следует пользоваться рекурсией?
Любые рекурсивные процедуры и функции, содержащие всего один рекурсивный вызов самих себя, легко заменяются итерационными циклами. Чтобы получить что-то, не имеющее простого нерекурсивного аналога, следует обратиться к процедурам и функциям, вызывающим себя два и более раз. В этом случае множество вызываемых процедур образует уже не цепочку, как на рис. 1, а целое дерево. Существуют широкие классы задач, когда вычислительный процесс должен быть организован именно таким образом. Как раз для них рекурсия будет наиболее простым и естественным способом решения.
5. Деревья
Теоретической базой для рекурсивных функций, вызывающих себя более одного раза, служит раздел дискретной математики, изучающий деревья.
5.1. Основные определения. Способы изображения деревьев
Определение: будем называть конечное множество T , состоящее из одного или более узлов, таких что:
а) Имеется один специальный узел, называемый корнем данного дерева.
б) Остальные узлы (исключая корень) содержатся в попарно непересекающихся подмножествах , каждое из которых в свою очередь является деревом. Деревья называются поддеревьями данного дерева.Это определение является рекурсивным. Если коротко, то дерево это множество, состоящее из корня и присоединенных к нему поддеревьев, которые тоже являются деревьями. Дерево определяется через само себя. Однако данное определение осмысленно, так как рекурсия конечна. Каждое поддерево содержит меньше узлов, чем содержащее его дерево. В конце концов, мы приходим к поддеревьям, содержащим всего один узел, а это уже понятно, что такое.

Рис. 3. Дерево.
На рис. 3 показано дерево с семью узлами. Хотя обычные деревья растут снизу вверх, рисовать их принято наоборот. При рисовании схемы от руки такой способ, очевидно, удобнее. Из-за данной несогласованности иногда возникает путаница, когда говорят о том, что один из узлов находится над или под другим. По этой причине удобнее пользоваться терминологией, употребляемой при описании генеалогических деревьев, называя более близкие к корню узлы предками, а более далекие потомками.
Графически дерево можно изобразить и некоторыми другими способами. Некоторые из них представлены на рис. 4. Согласно определению дерево представляет собой систему вложенных множеств, где эти множества или не пересекаются или полностью содержатся одно в другом. Такие множества можно изобразить как области на плоскости (рис. 4а). На рис. 4б вложенные множества располагаются не на плоскости, а вытянуты в одну линию. Рис. 4б также можно рассматривать как схему некоторой алгебраической формулы, содержащей вложенные скобки. Рис. 4в дает еще один популярный способ изображения древовидной структуры в виде уступчатого списка.
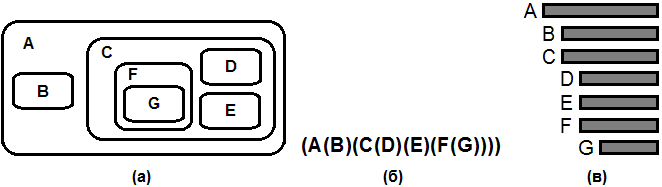
Рис. 4. Другие способы изображения древовидных структур: (а) вложенные множества; (б) вложенные скобки; (в) уступчатый список.
Уступчатый список имеет очевидное сходство со способом форматирования программного кода. Действительно, программа, написанная в рамках парадигмы структурного программирования, может быть представлена как дерево, состоящее из вложенных друг в друга конструкций.
Также можно провести аналогию между уступчатым списком и внешним видом оглавлений в книгах, где разделы содержат подразделы, те в свою очередь поподразделы и т.д. Традиционный способ нумерации таких разделов (раздел 1, подразделы 1.1 и 1.2, подподраздел 1.1.2 и т.п.) называется десятичной системой Дьюи. В применении к дереву на рис. 3 и 4 эта система даст:
1. A; 1.1 B; 1.2 C; 1.2.1 D; 1.2.2 E; 1.2.3 F; 1.2.3.1 G;
5.2. Прохождение деревьев
Во всех алгоритмах, связанных с древовидными структурами неизменно встречается одна и та же идея, а именно идея прохождения или обхода дерева . Это – такой способ посещения узлов дерева, при котором каждый узел проходится точно один раз. При этом получается линейная расстановка узлов дерева. В частности существует три способа: можно проходить узлы в прямом, обратном и концевом порядке.
Алгоритм обхода в прямом порядке:
- Попасть в корень,
- Пройти все поддеревья слева на право в прямом порядке.
Данный алгоритм рекурсивен, так как прохождение дерева содержит прохождение поддеревьев, а они в свою очередь проходятся по тому же алгоритму.
В частности для дерева на рис. 3 и 4 прямой обход дает последовательность узлов: A, B, C, D, E, F, G.
Получающаяся последовательность соответствует последовательному слева направо перечислению узлов при представлении дерева с помощью вложенных скобок и в десятичной системе Дьюи, а также проходу сверху вниз при представлении в виде уступчатого списка.
При реализации этого алгоритма на языке программирования попадание в корень соответствует выполнение процедурой или функцией некоторых действий, а прохождение поддеревьев – рекурсивным вызовам самой себя. В частности для бинарного дерева (где из каждого узла исходит не более двух поддеревьев) соответствующая процедура будет выглядеть так:
// Preorder Traversal – английское название для прямого порядка procedure PreorderTraversal({Аргументы}); begin //Прохождение корня DoSomething({Аргументы}); //Прохождение левого поддерева if {Существует левое поддерево} then PreorderTransversal({Аргументы 2}); //Прохождение правого поддерева if {Существует правое поддерево} then PreorderTransversal({Аргументы 3}); end;
То есть сначала процедура производит все действия, а только затем происходят все рекурсивные вызовы.
Алгоритм обхода в обратном порядке:
- Пройти левое поддерево,
- Попасть в корень,
- Пройти следующее за левым поддерево.
- Попасть в корень,
- и т.д пока не будет пройдено крайнее правое поддерево.
То есть проходятся все поддеревья слева на право, а возвращение в корень располагается между этими прохождениями. Для дерева на рис. 3 и 4 это дает последовательность узлов: B, A, D, C, E, G, F.
В соответствующей рекурсивной процедуре действия будут располагаться в промежутках между рекурсивными вызовами. В частности для бинарного дерева:
// Inorder Traversal – английское название для обратного порядка procedure InorderTraversal({Аргументы}); begin //Прохождение левого поддерева if {Существует левое поддерево} then InorderTraversal({Аргументы 2}); //Прохождение корня DoSomething({Аргументы}); //Прохождение правого поддерева if {Существует правое поддерево} then InorderTraversal({Аргументы 3}); end;
Алгоритм обхода в концевом порядке:
- Пройти все поддеревья слева на право,
- Попасть в корень.
Для дерева на рис. 3 и 4 это даст последовательность узлов: B, D, E, G, F, C, A.
В соответствующей рекурсивной процедуре действия будут располагаться после рекурсивных вызовов. В частности для бинарного дерева:
// Postorder Traversal – английское название для концевого порядка procedure PostorderTraversal({Аргументы}); begin //Прохождение левого поддерева if {Существует левое поддерево} then PostorderTraversal({Аргументы 2}); //Прохождение правого поддерева if {Существует правое поддерево} then PostorderTraversal({Аргументы 3}); //Прохождение корня DoSomething({Аргументы}); end;
5.3. Представление дерева в памяти компьютера
Если некоторая информация располагается в узлах дерева, то для ее хранения можно использовать соответствующую динамическую структуру данных. На Паскале это делается с помощью переменной типа запись (record), содержащей указатели на поддеревья того же типа. Например, бинарное дерево, где в каждом узле содержится целое число можно сохранить с помощью переменной типа PTree, который описан ниже:
Type PTree = ^TTree; TTree = record Inf: integer; LeftSubTree, RightSubTree: PTree; end;
Каждый узел имеет тип PTree. Это указатель, то есть каждый узел необходимо создавать, вызывая для него процедуру New. Если узел является концевым, то его полям LeftSubTree и RightSubTree присваивается значение nil . В противном случае узлы LeftSubTree и RightSubTree также создаются процедурой New.
Схематично одна такая запись изображена на рис. 5.

Рис. 5. Схематичное изображение записи типа TTree. Запись имеет три поля: Inf – некоторое число, LeftSubTree и RightSubTree – указатели на записи того же типа TTree.
Пример дерева, составленного из таких записей, показан на рисунке 6.
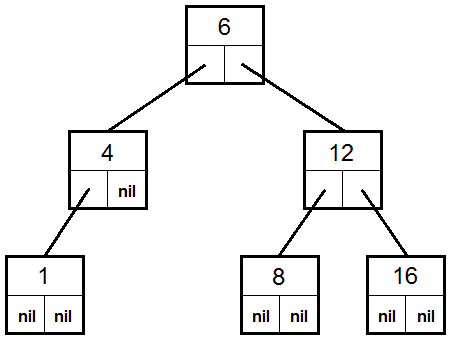
Рис. 6. Дерево, составленное из записей типа TTree. Каждая запись хранит число и два указателя, которые могут содержать либо nil , либо адреса других записей того же типа.
Если вы ранее не работали со структурами состоящими из записей, содержащих ссылки на записи того же типа, то рекомендуем ознакомиться с материалом о .
6. Примеры рекурсивных алгоритмов
6.1. Рисование дерева
Рассмотрим алгоритм рисования деревца, изображенного на рис. 6. Если каждую линию считать узлом, то данное изображение вполне удовлетворяет определению дерева, данному в предыдущем разделе.

Рис. 6. Деревце.
Рекурсивная процедура, очевидно должна рисовать одну линию (ствол до первого разветвления), а затем вызывать сама себя для рисования двух поддеревьев. Поддеревья отличаются от содержащего их дерева координатами начальной точки, углом поворота, длиной ствола и количеством содержащихся в них разветвлений (на одно меньше). Все эти отличия следует сделать параметрами рекурсивной процедуры.
Пример такой процедуры, написанный на Delphi, представлен ниже:
Procedure Tree(Canvas: TCanvas; //Canvas, на котором будет рисоваться дерево x,y: extended; //Координаты корня Angle: extended; //Угол, под которым растет дерево TrunkLength: extended; //Длина ствола n: integer //Количество разветвлений (сколько еще предстоит //рекурсивных вызовов)); var x2, y2: extended; //Конец ствола (точка разветвления) begin x2:= x + TrunkLength * cos(Angle); y2:= y - TrunkLength * sin(Angle); Canvas.MoveTo(round(x), round(y)); Canvas.LineTo(round(x2), round(y2)); if n > 1 then begin Tree(Canvas, x2, y2, Angle+Pi/4, 0.55*TrunkLength, n-1); Tree(Canvas, x2, y2, Angle-Pi/4, 0.55*TrunkLength, n-1); end; end;
Для получения рис. 6 эта процедура была вызвана со следующими параметрами:
Tree(Image1.Canvas, 175, 325, Pi/2, 120, 15);
Заметим, что рисование осуществляется до рекурсивных вызовов, то есть дерево рисуется в прямом порядке.
6.2. Ханойские башни
Согласно легенде в Великом храме города Бенарас, под собором, отмечающим середину мира, находится бронзовый диск, на котором укреплены 3 алмазных стержня, высотой в один локоть и толщиной с пчелу. Давным-давно, в самом начале времен монахи этого монастыря провинились перед богом Брамой. Разгневанный, Брама воздвиг три высоких стержня и на один из них поместил 64 диска из чистого золота, причем так, что каждый меньший диск лежит на большем. Как только все 64 диска будут переложены со стержня, на который Бог Брама сложил их при создании мира, на другой стержень, башня вместе с храмом обратятся в пыль и под громовые раскаты погибнет мир.
В процессе требуется, чтобы больший диск ни разу не оказывался над меньшим. Монахи в затруднении, в какой же последовательности стоит делать перекладывания? Требуется снабдить их софтом для расчета этой последовательности.Независимо от Брамы данную головоломку в конце 19 века предложил французский математик Эдуард Люка. В продаваемом варианте обычно использовалось 7-8 дисков (рис. 7).

Рис. 7. Головоломка «Ханойские башни».
Предположим, что существует решение для n -1 диска. Тогда для перекладывания n дисков надо действовать следующим образом:
1) Перекладываем n -1 диск.
2) Перекладываем n -й диск на оставшийся свободным штырь.
3) Перекладываем стопку из n -1 диска, полученную в пункте (1) поверх n -го диска.Поскольку для случая n = 1 алгоритм перекладывания очевиден, то по индукции с помощью выполнения действий (1) – (3) можем переложить произвольное количество дисков.
Создадим рекурсивную процедуру, печатающую всю последовательность перекладываний для заданного количества дисков. Такая процедура при каждом своем вызове должна печатать информацию об одном перекладывании (из пункта 2 алгоритма). Для перекладываний из пунктов (1) и (3) процедура вызовет сама себя с уменьшенным на единицу количеством дисков.
//n – количество дисков //a, b, c – номера штырьков. Перекладывание производится со штырька a, //на штырек b при вспомогательном штырьке c. procedure Hanoi(n, a, b, c: integer); begin if n > 1 then begin Hanoi(n-1, a, c, b); writeln(a, " -> ", b); Hanoi(n-1, c, b, a); end else writeln(a, " -> ", b); end;
Заметим, что множество рекурсивно вызванных процедур в данном случае образует дерево, проходимое в обратном порядке.
6.3. Синтаксический анализ арифметических выражений
Задача синтаксического анализа заключается в том, чтобы по имеющейся строке, содержащей арифметическое выражение, и известным значениям, входящих в нее переменных, вычислить значение выражения.
Процесс вычисления арифметических выражений можно представить в виде бинарного дерева. Действительно, каждый из арифметических операторов (+, –, *, /) требует двух операндов, которые также будут являться арифметическими выражениями и, соответственно могут рассматриваться как поддеревья. Рис. 8 показывает пример дерева, соответствующего выражению:

Рис. 8. Синтаксическое дерево, соответствующее арифметическому выражению (6).
В таком дереве концевыми узлами всегда будут переменные (здесь x ) или числовые константы, а все внутренние узлы будут содержать арифметические операторы. Чтобы выполнить оператор, надо сначала вычислить его операнды. Таким образом, дерево на рисунке следует обходить в концевом порядке. Соответствующая последовательность узлов
называется обратной польской записью арифметического выражения.
При построении синтаксического дерева следует обратить внимание на следующую особенность. Если есть, например, выражение
и операции сложения и вычитания мы будем считывать слева на право, то правильное синтаксическое дерево будет содержать минус вместо плюса (рис. 9а). По сути, это дерево соответствует выражению Облегчить составление дерева можно, если анализировать выражение (8) наоборот, справа налево. В этом случае получается дерево с рис. 9б, эквивалентное дереву 8а, но не требующее замены знаков.
Аналогично справа налево нужно анализировать выражения, содержащие операторы умножения и деления.

Рис. 9. Синтаксические деревья для выражения a – b + c при чтении слева направо (а) и справа налево (б).
Такой подход не избавляет нас от рекурсии полностью. Однако он позволяет ограничиться только одним обращением к рекурсивной процедуре, что может быть достаточно, если мотивом является забота о максимальной производительности.
7.3. Определение узла дерева по его номеру
Идея данного подхода в том, чтобы заменить рекурсивные вызовы простым циклом, который выполнится столько раз, сколько узлов в дереве, образованном рекурсивными процедурами. Что именно будет делаться на каждом шаге, следует определить по номеру шага. Сопоставить номер шага и необходимые действия – задача не тривиальная и в каждом случае ее придется решать отдельно.
Например, пусть требуется выполнить k вложенных циклов по n шагов в каждом:
For i1:= 0 to n-1 do for i2:= 0 to n-1 do for i3:= 0 to n-1 do …
Если k заранее неизвестно, то написать их явным образом, как показано выше невозможно. Используя прием, продемонстрированный в разделе 6.5 можно получить требуемое количество вложенных циклов с помощью рекурсивной процедуры:
Procedure NestedCycles(Indexes: array of integer; n, k, depth: integer); var i: integer; begin if depth
Чтобы избавиться от рекурсии и свести все к одному циклу, обратим внимание, что если нумеровать шаги в системе счисления с основанием n , то каждый шаг имеет номер, состоящий из цифр i1, i2, i3, … или соответствующих значений из массива Indexes. То есть цифры соответствуют значениям счетчиков циклов. Номер шага в обычной десятичной системе счисления:
Всего шагов будет n k . Перебрав их номера в десятичной системе счисления и переведя каждый из них в систему с основанием n , получим значения индексов:
M:= round(IntPower(n, k)); for i:= 0 to M-1 do begin Number:= i; for p:= 0 to k-1 do begin Indexes := Number mod n; Number:= Number div n; end; DoSomething(Indexes); end;
Еще раз отметим, что метод не универсален и под каждую задачу придется придумывать что-то свое.
Контрольные вопросы
1. Определите, что сделают приведенные ниже рекурсивные процедуры и функции.
(а) Что напечатает приведенная ниже процедура при вызове Rec(4)?
Procedure Rec(a: integer); begin writeln(a); if a>0 then Rec(a-1); writeln(a); end;
(б) Чему будет равно значение функции Nod(78, 26)?
Function Nod(a, b: integer): integer; begin if a > b then Nod:= Nod(a – b, b) else if b > a then Nod:= Nod(a, b – a) else Nod:= a; end;
(в) Что будет напечатано приведенными ниже процедурами при вызове A(1)?
Procedure A(n: integer); procedure B(n: integer); procedure A(n: integer); begin writeln(n); B(n-1); end; procedure B(n: integer); begin writeln(n); if n
(г) Что напечатает нижеприведенная процедура при вызове BT(0, 1, 3)?
Procedure BT(x: real; D, MaxD: integer); begin if D = MaxD then writeln(x) else begin BT(x – 1, D + 1, MaxD); BT(x + 1, D + 1, MaxD); end; end;
2. Уроборос – змей, пожирающий собственный хвост (рис. 14) в развернутом виде имеет длину L , диаметр около головы D , толщину брюшной стенки d . Определите, сколько хвоста он сможет в себя впихнуть и в сколько слоев после этого будет уложен хвост?
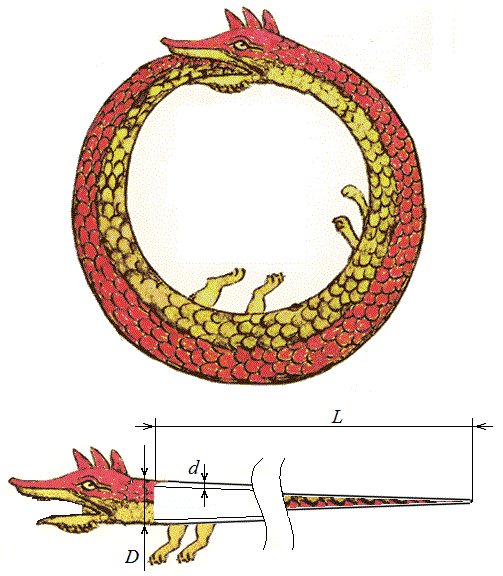
Рис. 14. Развернутый уроборос.
3. Для дерева на рис. 10а укажите последовательности посещения узлов при прямом, обратном и концевом порядке обхода.
4. Изобразите графически дерево, заданное с помощью вложенных скобок: (A(B(C, D), E), F, G).
5. Изобразите графически синтаксическое дерево для следующего арифметического выражения:
Запишите это выражение в обратной польской записи.
6. Для приведенного ниже графа (рис. 15) запишите матрицу смежности и матрицу инцидентности.
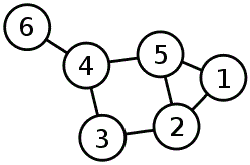
Задачи
1. Вычислив факториал достаточно большое количество раз (миллион или больше), сравните эффективность рекурсивного и итерационного алгоритмов. Во сколько раз будет отличаться время выполнения и как это отношение будет зависеть от числа, факториал которого рассчитывается?
2. Напишите рекурсивную функцию, проверяющую правильность расстановки скобок в строке. При правильной расстановке выполняются условия:
(а) количество открывающих и закрывающих скобок равно.
(б) внутри любой пары открывающая – соответствующая закрывающая скобка, скобки расставлены правильно.Примеры неправильной расстановки:)(, ())(, ())(() и т.п.
3. В строке могут присутствовать скобки как круглые, так и квадратные скобки. Каждой открывающей скобке соответствует закрывающая того же типа (круглой – круглая, квадратной- квадратная). Напишите рекурсивную функцию, проверяющую правильность расстановки скобок в этом случае.
Пример неправильной расстановки: ([) ].
4. Число правильных скобочных структур длины 6 равно 5: ()()(), (())(), ()(()), ((())), (()()).
Напишите рекурсивную программу генерации всех правильных скобочных структур длины 2n .Указание : Правильная скобочная структура минимальной длины «()». Структуры большей длины получаются из структур меньшей длины, двумя способами:
(а) если меньшую структуру взять в скобки,
(б) если две меньших структуры записать последовательно.5. Создайте процедуру, печатающую все возможные перестановки для целых чисел от 1 до N.
6. Создайте процедуру, печатающую все подмножества множества {1, 2, …, N}.
7. Создайте процедуру, печатающую все возможные представления натурального числа N в виде суммы других натуральных чисел.
8. Создайте функцию, подсчитывающую сумму элементов массива по следующему алгоритму: массив делится пополам, подсчитываются и складываются суммы элементов в каждой половине. Сумма элементов в половине массива подсчитывается по тому же алгоритму, то есть снова путем деления пополам. Деления происходят, пока в получившихся кусках массива не окажется по одному элементу и вычисление суммы, соответственно, не станет тривиальным.
Замечание : Данный алгоритм является альтернативой . В случае вещественнозначных массивов он, обычно, позволяет получать меньшие погрешности округления.
10. Создайте процедуру, рисующую кривую Коха (рис. 12).
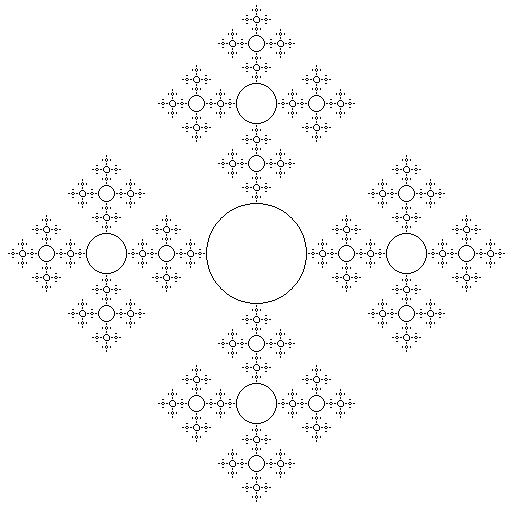
11. Воспроизведите рис. 16. На рисунке на каждой следующей итерации окружности в 2.5 раза меньше (этот коэффициент можно сделать параметром).
Литература
1. Д. Кнут. Искусство программирования на ЭВМ. т. 1. (раздел 2.3. «Деревья»).
2. Н. Вирт. Алгоритмы и структуры данных.Рекурсии являются интересными событиями сами по себе, но в программировании они представляют особенную важность в отдельных случаях. Впервые сталкиваясь с ними, довольно значительное количество людей имеют проблемы с их пониманием. Это связано с огромным полем потенциального применения самого термина в зависимости от контекста, в котором «рекурсия» используется. Но можно надеяться, что эта статья поможет избежать возможного недоразумения или непонимания.
Что такое "рекурсия" вообще?
Слово "рекурсия" имеет целый спектр значений, которые зависят от области, в которой оно применяется. Универсальное обозначение является таким: рекурсии - это определения, изображения, описания объектов или процессов в самих объектах. Возможны они только в тех случаях, когда объект является частью самого себя. По-своему определяют рекурсию математика, физика, программирование и ряд других научных дисциплин. Практическое применение она нашла в работе информационных систем и физических экспериментах.
Что подразумевают под рекурсией в программировании?

Рекурсивными ситуациями, или рекурсией в программировании, называют моменты, когда процедура или функция программы вызывает саму себя. Как бы странно для тех, кто начал изучать программирование, это ни звучало, здесь нет ничего странного. Следует запомнить, что рекурсии - это не сложно, и в отдельных случаях они заменяют циклы. Если компьютеру правильно задать вызов процедуры или функции, он просто начнёт её выполнять.
Рекурсия может быть конечной или бесконечной. Для того чтобы первая прекратила сама себя вызывать, в ней же должны быть условия прекращения. Это может быть уменьшение значения переменной и при достижении определённого значения остановка вызова и завершение программы/переход к последующему коду, в зависимости от потребностей достичь определённых целей. Под бесконечной рекурсией подразумевают, что она будет вызываться, пока будет работать компьютер или программа, в которой она работает.
Возможна также организация сложной рекурсии с помощью двух функций. Допустим, есть А и Б. Функция А имеет в своем коде вызов Б, а Б, в свою очередь, указывает компьютеру на необходимость выполнить А. Сложные рекурсии - это выход из целого ряда сложных логических ситуаций для компьютерной логики.
Если читающий эти строки изучал программные циклы, то он, наверное, уже заметил схожесть между ними и рекурсией. В целом они действительно могут выполнять похожие или идентичные задания. С помощью рекурсии удобно делать имитацию работы цикла. Особенно это полезно там, где сами циклы использовать не очень удобно. Схема программной реализации не сильно различается у разных высокоуровневых языков программирования. Но всё же рекурсия в "Паскале" и рекурсия в С или другом языке имеет свои особенности. Может она быть успешно реализована и в низкоуровневых языках вроде "Ассемблера", но это является более проблематичным и затратным по времени.
Деревья рекурсии

Что такое "дерево" в программировании? Это конечное множество, состоящее как минимум из одного узла, который:
- Имеет начальный специальный узел, который называют корнем всего дерева.
- Остальные узлы находятся в количестве, отличном от нуля, попарно непересекающихся подмножеств, при этом они тоже являются деревом. Все такие формы организации называют поддеревьями главного дерева.
Другими словами: деревья содержат поддеревья, которые содержат ещё деревья, но в меньшем количестве, чем предыдущее дерево. Так продолжается до тех пор, пока в одном из узлов не останется возможности продвигаться далее, и это будет обозначать конец рекурсии. Есть ещё один нюанс насчет схематического изображения: обычные деревья растут снизу вверх, а в программировании они рисуются наоборот. Узлы, не имеющие продолжения, называются конечными узлами. Для удобства обозначения и для удобства используется генеалогическая терминология (предки, дети).
Зачем она применяется в программировании?

Своё применение рекурсия в программировании нашла в решении целого ряда сложных задач. Если необходимо сделать только один вызов, то более легким является применение интеграционного цикла, но при двух и более повторах, чтобы избежать построения цепочки и сделать их выполнение в виде дерева, и применяются рекурсивные ситуации. Для широкого класса задач организация вычислительного процесса таким способом является наиболее оптимальной с точки зрения потребления ресурсов. Так, рекурсия в "Паскале" или другом любом высокоуровневом языке программирования представляет собой вызов функции или процедуры до выполнения условий, независимо от количества внешних вызовов. Другими словами, в программе может быть только одно обращение к подпрограмме, но происходить оно будет до определённого заранее момента. В некотором роде это аналог цикла со своей спецификой использования.
Отличия рекурсии в различных языках программирования
Несмотря на общую схему реализации и конкретное применение в каждом отдельном случае, рекурсия в программировании имеет свои особенности. Это может привести к сложности во время поиска необходимого материала. Но всегда следует помнить: если язык программирования вызывает функции или процедуры, значит, и вызов рекурсии - дело осуществимое. Но наиболее значимые её отличия проявляются при использовании низких и высоких языков программирования. Особенно это касается возможностей программной реализации. Исполнение в конечном итоге зависит от того, какая задача поставлена, в соответствии с ней и пишется рекурсия. Функции и процедуры используются разные, но их цель всегда одна - заставить вызвать самих себя.
Рекурсия - это легко. Как просто запомнить содержание статьи?

Для начинающих понять её, может быть, поначалу сложно, поэтому нужны примеры рекурсии или хотя бы один. Поэтому следует привести небольшой пример из бытовой жизни, который поможет понять саму суть этого механизма достижения целей в программировании. Возьмите два или больше зеркал, поставьте их так, чтобы в одном отображались все остальные. Можно увидеть, что зеркала отображают себя многократно, создавая эффект бесконечности. Вот рекурсии - это, образно говоря, отражения (их будет множество). Как видите, понять несложно, было бы желание. А изучая материалы по программированию, далее можно понять, что рекурсия - это ещё и очень легко выполнимая задача.
- структуры данных: