Parret regression i excel. Regressionsanalyse i Microsoft Excel
Regression og korrelationsanalyse er statistiske forskningsmetoder. Dette er de mest almindelige måder at vise en parameters afhængighed af en eller flere uafhængige variable.
Nedenfor om specifikke praktiske eksempler Lad os se på disse to meget populære analyser blandt økonomer. Vi vil også give et eksempel på opnåelse af resultater ved at kombinere dem.
Regressionsanalyse i Excel
Viser indflydelsen af nogle værdier (uafhængig, uafhængig) på den afhængige variabel. For eksempel hvordan afhænger antallet af erhvervsaktive af antallet af virksomheder, lønninger og andre parametre. Eller: hvordan påvirker udenlandske investeringer, energipriser osv. niveauet af BNP.
Resultatet af analysen giver dig mulighed for at fremhæve prioriteringer. Og baseret på de vigtigste faktorer, forudsige og planlægge udvikling prioriterede områder, træffe ledelsesbeslutninger.
Regression sker:
- lineær (y = a + bx);
- parabolsk (y = a + bx + cx 2);
- eksponentiel (y = a * exp(bx));
- potens (y = a*x^b);
- hyperbolsk (y = b/x + a);
- logaritmisk (y = b * 1n(x) + a);
- eksponentiel (y = a * b^x).
Lad os se på konstruktionen som et eksempel regressionsmodel i Excel og fortolkning af resultaterne. Lad os tage lineær type regression.
Opgave. På 6 virksomheder er den gennemsnitlige månedsløn og antallet af fratrådte analyseret. Det er nødvendigt at bestemme afhængigheden af antallet af opsigende medarbejdere af gennemsnitslønnen.
Model lineær regression har følgende form:
Y = a 0 + a 1 x 1 +…+a k x k.
Hvor a er regressionskoefficienter, x er påvirkende variable, k er antallet af faktorer.
I vores eksempel er Y indikatoren for at stoppe medarbejdere. Den indflydelsesrige faktor er løn (x).
Excel har indbyggede funktioner, der kan hjælpe dig med at beregne parametrene for en lineær regressionsmodel. Men tilføjelsen "Analysis Package" vil gøre dette hurtigere.
Vi aktiverer et stærkt analytisk værktøj:


Når den er aktiveret, vil tilføjelsen være tilgængelig på fanen Data.

Lad os nu lave selve regressionsanalysen.


Først og fremmest er vi opmærksomme på R-kvadrat og koefficienter.
R-kvadrat er bestemmelseskoefficienten. I vores eksempel - 0,755 eller 75,5%. Det betyder, at modellens beregnede parametre forklarer 75,5 % af sammenhængen mellem de undersøgte parametre. Jo højere bestemmelseskoefficient, jo bedre kvalitetsmodel. Godt - over 0,8. Dårlig – mindre end 0,5 (en sådan analyse kan næppe anses for rimelig). I vores eksempel - "ikke dårligt".
Koefficienten 64,1428 viser, hvad Y vil være, hvis alle variabler i den betragtede model er lig med 0. Det vil sige, at værdien af den analyserede parameter også påvirkes af andre faktorer, der ikke er beskrevet i modellen.
Koefficienten -0,16285 viser vægten af variabel X på Y. Det vil sige, at den gennemsnitlige månedsløn inden for denne model påvirker antallet af kvittere med en vægt på -0,16285 (dette er en lille grad af indflydelse). "-"-tegnet indikerer en negativ indvirkning: Jo højere løn, jo færre stopper. Hvilket er fair.
Korrelationsanalyse i Excel
Korrelationsanalyse hjælper med at bestemme, om der er en sammenhæng mellem indikatorer i en eller to prøver. For eksempel mellem en maskines driftstid og omkostningerne til reparationer, prisen på udstyr og varigheden af driften, børns højde og vægt mv.
Hvis der er en forbindelse, fører en stigning i den ene parameter til en stigning (positiv korrelation) eller et fald (negativ) af den anden. Korrelationsanalyse hjælper analytikeren med at bestemme, om værdien af en indikator kan bruges til at forudsige den mulige værdi af en anden.
Korrelationskoefficienten er angivet med r. Varierer fra +1 til -1. Klassificering af korrelationer for forskellige områder vil være anderledes. Når koefficienten er 0 lineær afhængighed eksisterer ikke mellem prøverne.
Lad os se på, hvordan man bruger Excel værktøjer find korrelationskoefficienten.
For at finde parrede koefficienter bruges CORREL-funktionen.
Mål: Afgøre, om der er sammenhæng mellem driftstid drejebænk og omkostningerne ved dens vedligeholdelse.

Placer markøren i en hvilken som helst celle, og tryk på fx-knappen.
- I kategorien "Statistisk" skal du vælge CORREL-funktionen.
- Argument "Array 1" - det første værdiområde - maskinens driftstid: A2:A14.
- Argument "Array 2" - andet værdiområde - reparationsomkostninger: B2:B14. Klik på OK.

For at bestemme typen af forbindelse skal du se på koefficientens absolutte tal (hvert aktivitetsområde har sin egen skala).
Til korrelationsanalyse flere parametre (mere end 2), er det mere bekvemt at bruge "Data Analysis" (tilføjelsen "Analysis Package"). Du skal vælge korrelation fra listen og udpege arrayet. Alle.
De resulterende koefficienter vil blive vist i korrelationsmatrixen. Sådan her:

Korrelations- og regressionsanalyse
I praksis bruges disse to teknikker ofte sammen.
Eksempel:



Nu er regressionsanalysedataene blevet synlige.
Korrelations- OG REGRESSIONSANALYSE IFRK EXCEL
1. Opret en kildedatafil i MS Excel (f.eks. tabel 2)
2. Konstruktion af korrelationsfeltet
At konstruere et korrelationsfelt i kommandolinje vælg menu Indsæt/Diagram. I dialogboksen, der vises, skal du vælge diagramtypen: Få øje på; udsigt: Spredningsplot, så du kan sammenligne værdipar (fig. 22).
Figur 22 – Valg af en diagramtype
Figur 23– Vinduesvisning ved valg af et område og rækker
Figur 25 – Vinduesvisning, trin 4
2. B kontekstmenu vælge et hold Tilføj en trendlinje.
3. Vælg graftypen (lineær i vores eksempel) og ligningsparametrene i den dialogboks, der vises, som vist i figur 26.
Klik på OK. Resultatet er vist i figur 27.
Figur 27 – Korrelationsfelt for arbejdsproduktivitets afhængighed af kapital-arbejdskraft-forhold
På samme måde konstruerer vi et korrelationsfelt for arbejdsproduktivitetens afhængighed af udstyrsskiftforholdet. (Figur 28).
 |
Figur 28 – Sammenhængsfelt for arbejdsproduktivitet
på udstyrsudskiftningssatsen
3. Konstruktion af korrelationsmatrixen.
At bygge en korrelationsmatrix i menuen Service vælge Dataanalyse.
Brug af et dataanalyseværktøj Regression, udover resultaterne af regressionsstatistik, analyse af varians og konfidensintervaller, kan du få residualer og grafer over tilpasning af regressionslinjen, residualer og normal sandsynlighed. For at gøre dette skal du kontrollere adgangen til analysepakken. Vælg i hovedmenuen Service/tillæg. Sæt kryds i boksen Analysepakke(Figur 29)
Figur 30 – Dialogboks Dataanalyse
Efter at have klikket på OK, i dialogboksen, der vises, skal du angive inputintervallet (i vores eksempel A2:D26), gruppering (i vores tilfælde efter kolonner) og outputparametre, som vist i figur 31.
 |
Figur 31 – Dialogboks Korrelation
Beregningsresultaterne er vist i tabel 4.
Tabel 4 – Korrelationsmatrix
Kolonne 1 | Kolonne 2 | Kolonne 3 |
|
Kolonne 1 | |||
Kolonne 2 | |||
Kolonne 3 |
ENKELT-FAKTOR REGRESSIONSANALYSE
BRUG AF REGRESSIONSVÆRKTØJET
At udføre en regressionsanalyse af arbejdsproduktivitetens afhængighed af kapital-arbejdsforholdet i menuen Service vælge Dataanalyse og specificer analyseværktøjet Regression(Figur 32).
Figur 33 – Dialogboks Regression
Den lineære regressionsmetode giver os mulighed for at beskrive en ret linje, der bedst passer til en række ordnede par (x, y). Ligningen for en ret linje, kendt som lineær ligning, præsenteres nedenfor:
ŷ er den forventede værdi af y for en given værdi af x,
x er en uafhængig variabel,
a er et segment på y-aksen for en ret linje,
b er hældningen af den rette linje.
Nedenstående figur illustrerer dette koncept grafisk:
Ovenstående figur viser linjen beskrevet af ligningen ŷ =2+0,5x. Y-skæringspunktet er det punkt, hvor linjen skærer y-aksen; i vores tilfælde er a = 2. Linjens hældning, b, forholdet mellem linjens stigning og linjens længde, har en værdi på 0,5. En positiv hældning betyder, at linjen stiger fra venstre mod højre. Hvis b = 0, er linjen vandret, hvilket betyder, at der ikke er nogen sammenhæng mellem de afhængige og uafhængige variable. Med andre ord, at ændre værdien af x påvirker ikke værdien af y.
ŷ og y forveksles ofte. Grafen viser 6 ordnede par af punkter og en linje, ifølge den givne ligning

Denne figur viser punktet svarende til det ordnede par x = 2 og y = 4. Bemærk, at den forventede værdi af y ifølge linjen kl. x= 2 er ŷ. Vi kan bekræfte dette med følgende ligning:
ŷ = 2 + 0,5х =2 +0,5(2) =3.
Y-værdien repræsenterer det faktiske punkt, og ŷ-værdien er den forventede værdi af y ved hjælp af en lineær ligning for en given værdi af x.
Det næste trin er at bestemme den lineære ligning, der bedst matcher sættet af ordnede par, det talte vi om i den forrige artikel, hvor vi bestemte ligningstypen ved .
Brug af Excel til at definere lineær regression
For at bruge regressionsanalyseværktøjet indbygget i Excel, skal du aktivere tilføjelsen Analysepakke. Du kan finde den ved at klikke på fanen Fil -> Indstillinger(2007+), i dialogboksen, der vises MulighederExcel gå til fanen Tilføjelser. I marken Styring vælge TilføjelserExcel og klik Gå. Marker afkrydsningsfeltet ud for det vindue, der vises Analysepakke, klik OKAY.

I fanen Data i gruppe Analyse en ny knap vises Dataanalyse.

For at demonstrere tilføjelsens arbejde vil vi bruge data, hvor en fyr og en pige deler et bord på badeværelset. Indtast dataene fra vores badekareksempel i kolonne A og B på det tomme ark.
Gå til fanen Data, i gruppe Analyse klik Dataanalyse. I det vindue, der kommer frem Dataanalyse Vælg Regression som vist på figuren, og klik på OK.

Indstil de nødvendige regressionsparametre i vinduet Regression, som det er vist på billedet:

Klik OKAY. Nedenstående figur viser de opnåede resultater:
Disse resultater stemmer overens med dem, vi opnåede ved at lave vores egne beregninger i .
MS Excel-pakken giver dig mulighed for at udføre det meste af arbejdet meget hurtigt, når du konstruerer en lineær regressionsligning. Det er vigtigt at forstå, hvordan man fortolker de opnåede resultater. For at bygge en regressionsmodel skal du vælge Værktøjer\Dataanalyse\Regression (i Excel 2007 er denne tilstand i blokken Data/Dataanalyse/Regression). Kopier derefter resultaterne til en blok til analyse.

Regressions analyse er en af de mest populære metoder til statistisk forskning. Det kan bruges til at bestemme graden af indflydelse af uafhængige variabler på den afhængige variabel. I funktionalitet Microsoft Excel Der er værktøjer designet til at udføre denne type analyse. Lad os se på, hvad de er, og hvordan man bruger dem.
Men for at bruge funktionen, der giver dig mulighed for at udføre regressionsanalyse, skal du først aktivere Analysepakken. Først da vises de nødvendige værktøjer til denne procedure på Excel-båndet.


Når vi nu går til fanen "Data", på båndet i værktøjskassen "Analyse" Vi får at se ny knap – "Dataanalyse".

Typer af regressionsanalyse
Der er flere typer regression:
- parabolsk;
- berolige;
- logaritmisk;
- eksponentiel;
- demonstrativ;
- hyperbolsk;
- lineær regression.
Om udførelse sidste type Vi vil snakke om regressionsanalyse i Excel mere detaljeret senere.
Lineær regression i Excel
Nedenfor ses som eksempel en tabel, der viser den gennemsnitlige daglige lufttemperatur udenfor og antallet af butikskunder for den tilsvarende arbejdsdag. Lad os ved hjælp af regressionsanalyse finde ud af præcis, hvordan vejrforhold i form af lufttemperatur kan påvirke tilstedeværelsen af en detailvirksomhed.
Den generelle lineære regressionsligning er som følger: Y = a0 + a1x1 +…+ akhk. I denne formel Y betyder en variabel, indflydelsen af faktorer, som vi forsøger at studere. I vores tilfælde er dette antallet af købere. Betyder x- Det her forskellige faktorer, der påvirker variablen. Muligheder -en er regressionskoefficienter. Det vil sige, at det er dem, der bestemmer betydningen af en bestemt faktor. Indeks k angiver det samlede antal af netop disse faktorer.


Analyseresultater analyse
Resultaterne af regressionsanalysen vises i form af en tabel på det sted, der er angivet i indstillingerne.

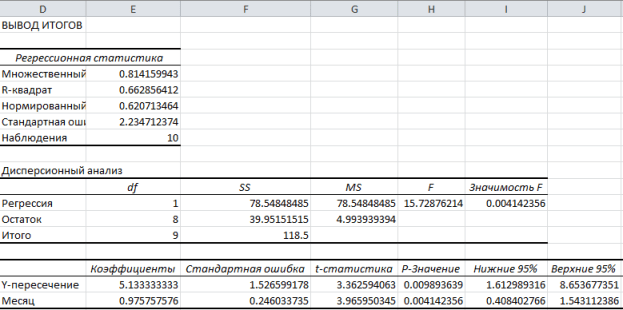
En af hovedindikatorerne er R-firkant. Det angiver kvaliteten af modellen. I vores tilfælde er denne koefficient 0,705 eller omkring 70,5%. Dette er et acceptabelt kvalitetsniveau. Afhængighed mindre end 0,5 er dårligt.
En anden vigtig indikator placeret i cellen i skæringspunktet mellem linjen "Y-kryds" og kolonne "Odds". Dette indikerer hvilken værdi Y vil have, og i vores tilfælde er dette antallet af købere, med alle andre faktorer lig med nul. I denne tabel givet værdi svarer til 58,04.
Værdi i skæringspunktet mellem grafen "Variabel X1" Og "Odds" viser niveauet af afhængighed af Y på X. I vores tilfælde er dette niveauet af afhængighed af antallet af butikskunder af temperatur. En koefficient på 1,31 betragtes som en ret høj indflydelsesindikator.
Som vi kan se, ved hjælp af Microsoft programmer Excel er ret nemt at lave en regressionsanalysetabel. Men kun en uddannet person kan arbejde med outputdataene og forstå dens essens.