Nestet rekursjon. Eksempler på rekursive algoritmer
Hei Habrahabr!
I denne artikkelen vi vil snakke om rekursjonsproblemer og hvordan de kan løses.
Kort om rekursjon
Rekursjon er et ganske vanlig fenomen som forekommer ikke bare innen vitenskap, men også i Hverdagen. For eksempel Droste-effekten, Sierpinski-trekanten, osv. En måte å se rekursjon på er å peke webkameraet mot dataskjermen, naturlig nok, etter først å ha slått det på. Dermed vil kameraet ta opp bildet av dataskjermen og vise det på denne skjermen, det vil være noe som en lukket sløyfe. Som et resultat vil vi observere noe som ligner på en tunnel.I programmering er rekursjon nært knyttet til funksjoner mer presist, det er takket være funksjoner i programmering at det finnes noe som heter rekursjon eller en rekursiv funksjon. Med enkle ord, rekursjon er definisjonen av en del av en funksjon (metode) gjennom seg selv, det vil si at det er en funksjon som kaller seg selv, direkte (i kroppen sin) eller indirekte (gjennom en annen funksjon).
Det har blitt sagt mye om rekursjon. Her er noen gode ressurser:
- Rekursjon og rekursive problemer. Bruksområder for rekursjon
Oppgaver
Når du lærer rekursjon, er den mest effektive måten å forstå rekursjon på å løse problemer.Hvordan løse rekursjonsproblemer?
Først av alt må du forstå at rekursjon er en slags overkill. Generelt sett kan alt som løses iterativt løses rekursivt, det vil si ved å bruke en rekursiv funksjon.fra nettverket
Enhver algoritme implementert i rekursiv form kan skrives om i iterativ form og omvendt. Spørsmålet gjenstår om dette er nødvendig og hvor effektivt det vil være.
For å begrunne dette kan følgende argumenter gis.
Til å begynne med kan vi huske definisjonene av rekursjon og iterasjon. Rekursjon er en måte å organisere databehandling på der et program kaller seg selv direkte eller ved hjelp av andre programmer. Iterasjon er en måte å organisere databehandling på der visse handlinger gjentas mange ganger uten å føre til rekursive programanrop.
Deretter kan vi konkludere med at de er gjensidig utskiftbare, men ikke alltid med de samme kostnadene når det gjelder ressurser og hastighet. For å rettferdiggjøre dette kan vi gi følgende eksempel: det er en funksjon der det, for å organisere en viss algoritme, er en sløyfe som utfører en sekvens av handlinger avhengig av tellerens nåværende verdi (det er kanskje ikke avhengig av den). Siden det er en syklus, betyr det at kroppen gjentar en sekvens av handlinger - iterasjoner av syklusen. Du kan flytte operasjoner til en egen subrutine og gi den tellerverdien, hvis noen. Etter fullføring av utførelsen av subrutinen, kontrollerer vi betingelsene for å utføre løkken, og hvis den er sann, fortsetter vi til et nytt kall til subrutinen, hvis den er falsk, fullfører vi utførelsen. Fordi Vi plasserte alt innholdet i løkken i en subrutine, noe som betyr at betingelsen for å utføre løkken også er plassert i subrutinen, og den kan fås gjennom returverdien til funksjonen, parametere som sendes ved referanse eller peker til subrutinen , samt globale variabler. Videre er det lett å vise at et anrop til en gitt subrutine fra en sløyfe lett kan konverteres til et anrop eller ikke-anrop (returnere en verdi eller bare fullføre arbeid) av en subrutine fra seg selv, styrt av noen forhold (de som var tidligere i løkketilstand). Nå, hvis du ser på vårt abstrakte program, ser det omtrent ut som å sende verdier til en subrutine og bruke dem, som subrutinen vil endre når den er ferdig, dvs. vi erstattet den iterative sløyfen med et rekursivt kall til en subrutine for å løse en gitt algoritme.
Oppgaven med å bringe rekursjon til en iterativ tilnærming er symmetrisk.
For å oppsummere kan vi uttrykke følgende tanker: for hver tilnærming er det sin egen klasse med oppgaver, som bestemmes av de spesifikke kravene til en spesifikk oppgave.
Du kan finne ut mer om dette
Akkurat som en oppregning (syklus), må rekursjon ha en stoppbetingelse - Grunntilfelle (ellers, akkurat som en syklus, vil rekursjon fungere for alltid - uendelig). Denne tilstanden er tilfellet som rekursjonen går til (rekursjonstrinn). Ved hvert trinn kalles en rekursiv funksjon til neste anrop utløser basisbetingelsen og rekursjonen stopper (eller rettere sagt, går tilbake til siste samtale funksjoner). Hele løsningen handler om å løse hovedsaken. I tilfellet der en rekursiv funksjon kalles for å løse et komplekst problem (ikke basistilfellet), utføres en rekke rekursive anrop eller trinn for å redusere problemet til et enklere. Og så videre til vi får en grunnleggende løsning.
Så den rekursive funksjonen består av
- Stoppetilstand eller grunntilfelle
- En fortsettelsestilstand eller et rekursjonstrinn er en måte å redusere et problem til enklere.
Offentlig klasse Løsning ( offentlig statisk int rekursjon(int n) ( // exit condition // Grunnfall // når skal man slutte å gjenta rekursjonen? if (n == 1) ( return 1; ) // Rekursjonstrinn / rekursiv tilstand returnere rekursjon( n - 1) * n; ) public static void main(String args) ( System.out.println(recursion(5)); // kall en rekursiv funksjon )
Her er grunnbetingelsen tilstanden når n=1. Siden vi vet at 1!=1 og å beregne 1! vi trenger ikke noe. For å beregne 2! vi kan bruke 1!, dvs. 2!=1!*2. For å beregne 3! vi trenger 2!*3... For å beregne n! vi trenger (n-1)!*n. Dette er rekursjonstrinnet. Med andre ord, for å få faktorverdien til et tall n, er det nok å multiplisere faktorverdien til forrige tall med n.
Tagger:
- rekursjon
- oppgaver
- java
Hei Habrahabr!
I denne artikkelen vil vi snakke om rekursjonsproblemer og hvordan de kan løses.
Kort om rekursjon
Rekursjon er et ganske vanlig fenomen som forekommer ikke bare innen vitenskap, men også i hverdagen. For eksempel Droste-effekten, Sierpinski-trekanten, osv. En måte å se rekursjon på er å peke webkameraet mot dataskjermen, naturlig nok etter først å ha slått det på. Dermed vil kameraet ta opp bildet av dataskjermen og vise det på denne skjermen, det vil være noe som en lukket sløyfe. Som et resultat vil vi observere noe som ligner på en tunnel.I programmering er rekursjon nært knyttet til funksjoner mer presist, det er takket være funksjoner i programmering at det finnes noe som heter rekursjon eller en rekursiv funksjon. Med enkle ord er rekursjon definisjonen av en del av en funksjon (metode) gjennom seg selv, det vil si at det er en funksjon som kaller seg selv, direkte (i kroppen sin) eller indirekte (gjennom en annen funksjon).
Det har blitt sagt mye om rekursjon. Her er noen gode ressurser:
- Rekursjon og rekursive problemer. Bruksområder for rekursjon
Oppgaver
Når du lærer rekursjon, er den mest effektive måten å forstå rekursjon på å løse problemer.Hvordan løse rekursjonsproblemer?
Først av alt må du forstå at rekursjon er en slags overkill. Generelt sett kan alt som løses iterativt løses rekursivt, det vil si ved å bruke en rekursiv funksjon.fra nettverket
Enhver algoritme implementert i rekursiv form kan skrives om i iterativ form og omvendt. Spørsmålet gjenstår om dette er nødvendig og hvor effektivt det vil være.
For å begrunne dette kan følgende argumenter gis.
Til å begynne med kan vi huske definisjonene av rekursjon og iterasjon. Rekursjon er en måte å organisere databehandling på der et program kaller seg selv direkte eller ved hjelp av andre programmer. Iterasjon er en måte å organisere databehandling på der visse handlinger gjentas mange ganger uten å føre til rekursive programanrop.
Deretter kan vi konkludere med at de er gjensidig utskiftbare, men ikke alltid med de samme kostnadene når det gjelder ressurser og hastighet. For å rettferdiggjøre dette kan vi gi følgende eksempel: det er en funksjon der det, for å organisere en viss algoritme, er en sløyfe som utfører en sekvens av handlinger avhengig av tellerens nåværende verdi (det er kanskje ikke avhengig av den). Siden det er en syklus, betyr det at kroppen gjentar en sekvens av handlinger - iterasjoner av syklusen. Du kan flytte operasjoner til en egen subrutine og gi den tellerverdien, hvis noen. Etter fullføring av utførelsen av subrutinen, kontrollerer vi betingelsene for å utføre løkken, og hvis den er sann, fortsetter vi til et nytt kall til subrutinen, hvis den er falsk, fullfører vi utførelsen. Fordi Vi plasserte alt innholdet i løkken i en subrutine, noe som betyr at betingelsen for å utføre løkken også er plassert i subrutinen, og den kan fås gjennom returverdien til funksjonen, parametere som sendes ved referanse eller peker til subrutinen , samt globale variabler. Videre er det lett å vise at et anrop til en gitt subrutine fra en sløyfe lett kan konverteres til et anrop eller ikke-anrop (returnere en verdi eller bare fullføre arbeid) av en subrutine fra seg selv, styrt av noen forhold (de som var tidligere i løkketilstand). Nå, hvis du ser på vårt abstrakte program, ser det omtrent ut som å sende verdier til en subrutine og bruke dem, som subrutinen vil endre når den er ferdig, dvs. vi erstattet den iterative sløyfen med et rekursivt kall til en subrutine for å løse en gitt algoritme.
Oppgaven med å bringe rekursjon til en iterativ tilnærming er symmetrisk.
For å oppsummere kan vi uttrykke følgende tanker: for hver tilnærming er det sin egen klasse med oppgaver, som bestemmes av de spesifikke kravene til en spesifikk oppgave.
Du kan finne ut mer om dette
Akkurat som en oppregning (syklus), må rekursjon ha en stoppbetingelse - Grunntilfelle (ellers, akkurat som en syklus, vil rekursjon fungere for alltid - uendelig). Denne tilstanden er tilfellet som rekursjonen går til (rekursjonstrinn). Ved hvert trinn kalles en rekursiv funksjon til neste kall utløser basisbetingelsen og rekursjonen stopper (eller rettere sagt går tilbake til siste funksjonskall). Hele løsningen handler om å løse hovedsaken. I tilfellet der en rekursiv funksjon kalles for å løse et komplekst problem (ikke basistilfellet), utføres en rekke rekursive anrop eller trinn for å redusere problemet til et enklere. Og så videre til vi får en grunnleggende løsning.
Så den rekursive funksjonen består av
- Stoppetilstand eller grunntilfelle
- En fortsettelsestilstand eller et rekursjonstrinn er en måte å redusere et problem til enklere.
Offentlig klasse Løsning ( offentlig statisk int rekursjon(int n) ( // exit condition // Grunnfall // når skal man slutte å gjenta rekursjonen? if (n == 1) ( return 1; ) // Rekursjonstrinn / rekursiv tilstand returnere rekursjon( n - 1) * n; ) public static void main(String args) ( System.out.println(recursion(5)); // kall en rekursiv funksjon )
Her er grunnbetingelsen tilstanden når n=1. Siden vi vet at 1!=1 og å beregne 1! vi trenger ikke noe. For å beregne 2! vi kan bruke 1!, dvs. 2!=1!*2. For å beregne 3! vi trenger 2!*3... For å beregne n! vi trenger (n-1)!*n. Dette er rekursjonstrinnet. Med andre ord, for å få faktorverdien til et tall n, er det nok å multiplisere faktorverdien til forrige tall med n.
Tagger: Legg til tagger
Rekursjon er når en subrutine kaller seg selv. Når de står overfor en slik algoritmisk konstruksjon for første gang, opplever de fleste visse vanskeligheter, men med litt øvelse vil rekursjonen bli tydelig og veldig nyttig verktøy i programmeringsarsenalet ditt.
1. Essensen av rekursjon
En prosedyre eller funksjon kan inneholde kall til andre prosedyrer eller funksjoner. Prosedyren kan også kalle seg selv. Det er ikke noe paradoks her - datamaskinen utfører bare kommandoene den møter i programmet sekvensielt, og hvis den støter på et prosedyrekall, begynner den ganske enkelt å utføre denne prosedyren. Det spiller ingen rolle hvilken prosedyre som ga kommandoen for å gjøre dette.
Eksempel på en rekursiv prosedyre:
Prosedyre Rec(a: heltall); begynne hvis a>
La oss vurdere hva som skjer hvis et kall, for eksempel, av formen Rec(3) gjøres i hovedprogrammet. Nedenfor er et flytskjema som viser utførelsessekvensen til setningene.
Ris. 1. Blokkskjema over den rekursive prosedyren.
Prosedyre Rec kalles med parameter a = 3. Den inneholder et kall til prosedyre Rec med parameter a = 2. Det forrige kallet er ikke fullført ennå, så du kan tenke deg at en annen prosedyre er opprettet og den første ikke fullfører arbeidet før det ender. Anropsprosessen avsluttes når parameter a = 0. På dette tidspunktet utføres 4 forekomster av prosedyren samtidig. Antallet samtidig utførte prosedyrer kalles rekursjonsdybde.
Den fjerde prosedyren kalt (Rec(0)) vil skrive ut tallet 0 og fullføre arbeidet. Etter dette går kontrollen tilbake til prosedyren som kalte den (Rec(1)) og tallet 1 skrives ut og så videre til alle prosedyrer er fullført. Den opprinnelige samtalen vil skrive ut fire tall: 0, 1, 2, 3.
Et annet visuelt bilde av hva som skjer er vist i fig. 2.

Ris. 2. Utføring av Rec-prosedyren med parameter 3 består av å utføre Rec-prosedyren med parameter 2 og skrive ut nummer 3. I sin tur består å utføre Rec-prosedyren med parameter 2 av å utføre Rec-prosedyren med parameter 1 og skrive ut nummer 2. Osv. .
Som uavhengig øvelse tenk på hva som skjer når du ringer Rec(4). Vurder også hva som ville skje hvis du kalte Rec2(4)-prosedyren nedenfor, med operatørene omvendt.
Prosedyre Rec2(a: heltall); begynne å skriveln(a); hvis a>0 så Rec2(a-1); slutt;
Vær oppmerksom på at i eksemplene ovenfor er det rekursive anropet inne betinget operatør. Dette nødvendig tilstand for at rekursjonen noen gang skal ta slutt. Merk også at prosedyren kaller seg selv med en annen parameter enn den den ble kalt med. Hvis prosedyren ikke bruker globale variabler, er dette også nødvendig for at rekursjonen ikke skal fortsette i det uendelige.
Litt mer mulig kompleks krets: Funksjon A kaller funksjon B, som igjen kaller A. Dette kalles kompleks rekursjon. Det viser seg at prosedyren beskrevet først må kalle en prosedyre som ennå ikke er beskrevet. For at dette skal være mulig, må du bruke .
Prosedyre A(n: heltall); (Videresend beskrivelse (overskrift) av den første prosedyren) prosedyre B(n: heltall); (Viderebeskrivelse av den andre prosedyren) prosedyre A(n: heltall); ( Full beskrivelse prosedyrer A) begynne å skriveln(n); B(n-1); slutt; prosedyre B(n: heltall); (Full beskrivelse av prosedyre B) start writeln(n); hvis n
En videresende erklæring om prosedyre B lar den kalles fra en prosedyre A. En videre erklæring om prosedyre A i i dette eksemplet ikke nødvendig og lagt til av estetiske grunner.
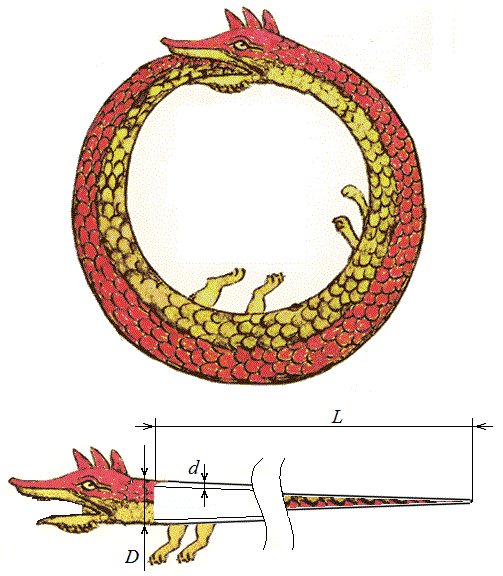
Hvis vanlig rekursjon kan sammenlignes med en ouroboros (fig. 3), så kan bildet av kompleks rekursjon hentes fra det berømte barnediktet, der "Ulvene ble skremt og spiste hverandre." Se for deg to ulver som spiser hverandre, og du vil forstå kompleks rekursjon.

Ris. 3. Ouroboros - en slange som sluker sin egen hale. Tegning fra den alkymistiske avhandlingen "Synosius" av Theodore Pelecanos (1478).

Ris. 4. Kompleks rekursjon.
3. Simulere en sløyfe ved hjelp av rekursjon
Hvis en prosedyre kaller seg selv, fører den i hovedsak til at instruksjonene den inneholder, blir utført på nytt, på samme måte som en loop. Noen programmeringsspråk inneholder ikke looping-konstruksjoner i det hele tatt, noe som lar programmerere organisere repetisjoner ved hjelp av rekursjon (for eksempel Prolog, der rekursjon er en grunnleggende programmeringsteknikk).
La oss for eksempel simulere arbeidet for løkke. For å gjøre dette trenger vi en trinntellervariabel, som for eksempel kan implementeres som en prosedyreparameter.
Eksempel 1.
Prosedyre LoopImitation(i, n: heltall); (Den første parameteren er trinntelleren, den andre parameteren er det totale antallet trinn) begin writeln("Hei N", i); //Her er instruksjoner som vil bli gjentatt hvis jeg Resultatet av et kall på formen LoopImitation(1, 10) vil være utførelse av instruksjoner ti ganger med telleren som endres fra 1 til 10. I i dette tilfellet vil bli skrevet ut: Hei N 1 Generelt er det ikke vanskelig å se at parametrene for prosedyren er grensene for å endre tellerverdiene. Du kan bytte det rekursive anropet og instruksjonene som skal gjentas, som i følgende eksempel. Eksempel 2.
Prosedyre LoopImitation2(i, n: heltall); begynne hvis jeg I dette tilfellet vil et rekursivt prosedyrekall forekomme før instruksjoner begynner å bli utført. Den nye instansen av prosedyren vil også først og fremst kalle en annen instans, og så videre, til vi når maksverdien til telleren. Først etter dette vil den siste av de kalte prosedyrene utføre sine instruksjoner, deretter vil den nest siste utføre sine instruksjoner osv. Resultatet av å ringe LoopImitation2(1, 10) vil være å skrive ut hilsener i omvendt rekkefølge: Hei N 10 Hvis vi ser for oss en kjede av rekursivt kalte prosedyrer, så går vi i eksempel 1 gjennom den fra tidligere kalte prosedyrer til senere. I eksempel 2, tvert imot, fra senere til tidligere. Til slutt kan et rekursivt anrop plasseres mellom to blokker med instruksjoner. For eksempel: Prosedyre LoopImitation3(i, n: heltall); begin writeln("Hei N", i); (Den første blokken med instruksjoner kan være plassert her) hvis jeg Her blir instruksjonene fra den første blokken først utført sekvensielt, deretter blir instruksjonene fra den andre blokken utført i omvendt rekkefølge. Når vi ringer LoopImitation3(1, 10) får vi: Hei N 1 Det ville ta to løkker for å gjøre det samme uten rekursjon. Du kan dra nytte av at utførelsen av deler av samme prosedyre er fordelt over tid. For eksempel: Eksempel 3: Konvertering av et tall til binært.
Å få sifrene til et binært tall, som kjent, skjer ved å dele med en rest på grunntallet av tallsystemet 2. Hvis det er et tall, er det siste sifferet i sin binære representasjon lik Å ta hele delen av divisjon med 2: vi får et tall som har samme binære representasjon, men uten siste siffer. Dermed er det nok å gjenta de to ovennevnte operasjonene til neste divisjonsfelt mottar en heltallsdel lik 0. Uten rekursjon vil det se slik ut: Mens x>0 begynner c:=x mod 2; x:=x div 2; skriv(c); slutt; Problemet her er at sifrene i den binære representasjonen beregnes i omvendt rekkefølge (siste først). For å skrive ut et tall i normal form, må du huske alle tallene i matriseelementene og skrive dem ut i en egen sløyfe. Ved å bruke rekursjon er det ikke vanskelig å oppnå utdata i riktig rekkefølge uten en matrise og en andre sløyfe. Nemlig: Prosedyre Binærrepresentasjon(x: heltall); var c, x: heltall; begynne (Første blokk. Utføres i rekkefølge etter prosedyrekall) c:= x mod 2; x:= x div 2; (Rekursivt kall) hvis x>0 så Binærrepresentasjon(x); (Andre blokk. Utføres i omvendt rekkefølge) write(c); slutt; Generelt sett mottok vi ingen gevinster. Sifrene i den binære representasjonen er lagret i lokale variabler, som er forskjellige for hver løpende forekomst av den rekursive prosedyren. Det vil si at det ikke var mulig å lagre minne. Tvert imot, vi kaster bort ekstra minne på å lagre mange lokale variabler x. Imidlertid virker denne løsningen vakker for meg. En sekvens av vektorer sies å være gitt av en gjentaksrelasjon hvis den opprinnelige vektoren og den funksjonelle avhengigheten til den påfølgende vektoren av den forrige er gitt Et enkelt eksempel på en mengde beregnet ved bruk av gjentakelsesrelasjoner er faktorialet Den neste faktoren kan beregnes fra den forrige som: Ved å introdusere notasjonen får vi relasjonen: Vektorene fra formel (1) kan tolkes som sett med variabelverdier. Deretter vil beregningen av det nødvendige elementet i sekvensen bestå av gjentatt oppdatering av verdiene deres. Spesielt for faktoriell: X:= 1; for i:= 2 til n gjør x:= x * i; skrivln(x); Hver slik oppdatering (x:= x * i) kalles iterasjon, og prosessen med å gjenta iterasjoner er iterasjon. La oss imidlertid merke oss at relasjon (1) er en rent rekursiv definisjon av sekvensen, og beregningen av det n-te elementet er faktisk den gjentatte ta av funksjonen f fra seg selv: Spesielt for faktoriell kan man skrive: Funksjonsfaktor(n: heltall): heltall; begynne hvis n > 1 så Faktoriell:= n * Faktoriell(n-1) ellers Faktoriell:= 1; slutt; Det skal forstås at oppkallingsfunksjoner innebærer noen ekstra overhead, så det første alternativet for å beregne faktoren vil være litt raskere. Generelt fungerer iterative løsninger raskere enn rekursive. Før vi går videre til situasjoner der rekursjon er nyttig, la oss se på ett eksempel til der det ikke bør brukes. La oss vurdere spesielt tilfelle tilbakevendende relasjoner, når den neste verdien i en sekvens ikke avhenger av én, men av flere tidligere verdier samtidig. Et eksempel er den berømte Fibonacci-sekvensen, der hvert neste element er summen av de to foregående: Med en "frontal" tilnærming kan du skrive: Funksjon Fib(n: heltall): heltall; begynne hvis n > 1 så Fib:= Fib(n-1) + Fib(n-2) ellers Fib:= 1; slutt; Hvert Fib-anrop lager to kopier av seg selv, hver kopi lager to til, og så videre. Antall operasjoner øker med antallet n eksponentielt, men med en iterativ løsning lineær inn n antall operasjoner. Faktisk lærer eksemplet ovenfor oss ikke NÅR rekursjon bør ikke brukes, ellers HVORDAN den skal ikke brukes. Tross alt, hvis det er en rask iterativ (løkkebasert) løsning, kan den samme loopen implementeres ved hjelp av en rekursiv prosedyre eller funksjon. For eksempel: // x1, x2 – startbetingelser (1, 1) // n – nummeret på den nødvendige Fibonacci-tallfunksjonen Fib(x1, x2, n: heltall): heltall; var x3: heltall; start hvis n > 1 så begynner x3:= x2 + x1; x1:= x2; x2:= x3; Fib:= Fib(xl, x2, n-1); end else Fib:= x2; slutt; Likevel er iterative løsninger å foretrekke. Spørsmålet er når i dette tilfellet bør du bruke rekursjon? Eventuelle rekursive prosedyrer og funksjoner som inneholder bare ett rekursivt anrop til seg selv, kan enkelt erstattes av iterative løkker. For å få noe som ikke har et enkelt ikke-rekursivt motstykke, må du ty til prosedyrer og funksjoner som kaller seg selv to eller flere ganger. I dette tilfellet danner settet med kalte prosedyrer ikke lenger en kjede, som i fig. 1, men et helt tre. Det er brede klasser av problemer når beregningsprosessen må organiseres på denne måten. Bare for dem vil rekursjon være den enkleste og på en naturlig måte løsninger. Det teoretiske grunnlaget for rekursive funksjoner som kaller seg mer enn en gang er grenen av diskret matematikk som studerer trær. Definisjon:
vi vil kalle den endelige mengden T, bestående av en eller flere noder slik at: Denne definisjonen er rekursiv. Kort fortalt er et tre et sett som består av en rot og undertrær knyttet til den, som også er trær. Et tre er definert gjennom seg selv. derimot denne definisjonen gir mening, siden rekursjonen er begrenset. Hvert undertre inneholder færre noder enn dets tre. Til slutt kommer vi til undertrær som inneholder bare én node, og dette er allerede klart hva det er. Ris. 3. Tre. I fig. Figur 3 viser et tre med syv noder. Selv om vanlige trær vokser fra bunn til topp, er det vanlig å tegne dem omvendt. Når du tegner et diagram for hånd, er denne metoden åpenbart mer praktisk. På grunn av denne inkonsekvensen oppstår noen ganger forvirring når en node sies å være over eller under en annen. Av denne grunn er det mer praktisk å bruke terminologien som brukes når man beskriver familietrær, kaller noder nærmere rotforfedrene og fjernere etterkommere. Et tre kan avbildes grafisk på andre måter. Noen av dem er vist i fig. 4. Ifølge definisjonen er et tre et system av nestede sett, der disse settene enten ikke krysser hverandre eller er fullstendig innesluttet i hverandre. Slike sett kan avbildes som områder på et plan (fig. 4a). I fig. 4b er de nestede settene ikke plassert på et plan, men er forlenget til en linje. Ris. 4b kan også sees på som et diagram av en algebraisk formel som inneholder nestede parenteser. Ris. 4b gir en til populær måte trestrukturbilder i form av en trinnliste. Ris. 4. Andre måter å representere trestrukturer på: (a) nestede sett; (b) nestede parenteser; (c) konsesjonsliste. Den forskjøvede listen har åpenbare likheter med formateringsmetoden programkode. Faktisk kan et program skrevet innenfor rammen av det strukturerte programmeringsparadigmet representeres som et tre som består av nestede strukturer. Du kan også tegne en analogi mellom en avsatsliste og utseende innholdsfortegnelser i bøker hvor seksjoner inneholder underkapitler, som igjen inneholder underavsnitt mv. Tradisjonell måte Nummereringen av slike seksjoner (seksjon 1, underavsnitt 1.1 og 1.2, underavsnitt 1.1.2 osv.) kalles Dewey-desimalsystemet. Påført treet i fig. 3 og 4 vil dette systemet gi: 1.A; 1.1B; 1,2 C; 1.2.1 D; 1.2.2 E; 1.2.3 F; 1.2.3.1 G; I alle algoritmer relatert til trestrukturer dukker alltid den samme ideen opp, nemlig ideen passering eller kryssing av tre. Dette er en måte å besøke trenoder der hver node krysses nøyaktig én gang. Dette resulterer i et lineært arrangement av trenoder. Spesielt er det tre måter: du kan gå gjennom nodene i forover-, revers- og sluttrekkefølge. Forward traversal algoritme: Denne algoritmen er rekursiv, siden traverseringen av et tre inneholder kryssingen av undertrær, og de på sin side krysses ved hjelp av den samme algoritmen. Spesielt for treet i fig. 3 og 4 gir direkte kryssing en sekvens av noder: A, B, C, D, E, F, G. Den resulterende sekvensen tilsvarer en sekvensiell venstre-til-høyre-oppregning av noder når du representerer et tre ved bruk av nestede parenteser og i desimalsystem Dewey, samt ovenfra-ned passasjen når den presenteres som en trinnvis liste. Når du implementerer denne algoritmen i et programmeringsspråk, tilsvarer det å treffe roten prosedyren eller funksjonen som utfører noen handlinger, og å gå gjennom undertrær tilsvarer rekursive anrop til seg selv. Spesielt for et binært tre (hvor hver node har maksimalt to undertrær), vil den tilsvarende prosedyren se slik ut: // Preorder Traversal – engelsk navn for direkte bestillingsprosedyre PreorderTraversal((Argumenter)); begynne //Passer roten DoSomething((Argumenter)); //Overgang av venstre undertre hvis (Det er et venstre undertre) deretter PreorderTransversal((Argumenter 2)); //Transversal av høyre undertre hvis (Det er et høyre undertre) deretter PreorderTransversal((Argumenter 3)); slutt; Det vil si at først utfører prosedyren alle handlinger, og først deretter oppstår alle rekursive anrop. Omvendt traversalalgoritme: Det vil si at alle undertrær krysses fra venstre til høyre, og returen til roten ligger mellom disse traverseringene. For treet i fig. 3 og 4 gir dette sekvensen av noder: B, A, D, C, E, G, F. I en tilsvarende rekursiv prosedyre vil handlingene være plassert i mellomrommene mellom de rekursive anropene. Spesielt for et binært tre: // Inorder Traversal – engelsk navn for prosedyre for omvendt rekkefølge InorderTraversal((Argumenter)); start //Reise det venstre undertreet hvis (Et venstre undertre finnes) deretter InorderTraversal((Argumenter 2)); //Passer roten DoSomething((Argumenter)); //Traverse det høyre undertreet hvis (Et høyre undertre finnes) deretter InorderTraversal((Argumenter 3)); slutt; End-order traversal algoritme: For treet i fig. 3 og 4 vil dette gi sekvensen av noder: B, D, E, G, F, C, A. I en tilsvarende rekursiv prosedyre vil handlingene bli lokalisert etter de rekursive anropene. Spesielt for et binært tre: // Postorder Traversal – engelsk navn for sluttbestillingsprosedyren PostorderTraversal((Argumenter)); begin //Reise det venstre undertreet if (Det er et venstre undertre) deretter PostorderTraversal((Argumenter 2)); //Transcendere det høyre undertreet hvis (Et høyre undertre eksisterer) så PostorderTraversal((Argumenter 3)); //Passer roten DoSomething((Argumenter)); slutt; Hvis noe informasjon er plassert i trenoder, kan du bruke den tilsvarende dynamisk struktur data. I Pascal gjøres dette ved hjelp av variabel type en post som inneholder pekere til undertrær av samme type. For eksempel kan et binært tre hvor hver node inneholder et heltall lagres ved å bruke en variabel av typen PTree, som er beskrevet nedenfor: Skriv PTree = ^TTree; TTree = post Inf: heltall; LeftSubTree, RightSubTree: PTree; slutt; Hver node har en PTree-type. Dette er en peker, noe som betyr at hver node må opprettes ved å kalle den nye prosedyren på den. Hvis noden er en bladnode, blir feltene LeftSubTree og RightSubTree tildelt verdien null. Ellers blir LeftSubTree- og RightSubTree-nodene også opprettet av New-prosedyren. En slik registrering er vist skjematisk i fig. 5. Ris. 5. Skjematisk representasjon av en TTree type post. Posten har tre felt: Inf – et tall, LeftSubTree og RightSubTree – pekere til poster av samme TTree-type. Et eksempel på et tre som består av slike poster er vist i figur 6. Ris. 6. Et tre som består av TTree type poster. Hver oppføring lagrer et tall og to pekere som kan inneholde enten null, eller adresser til andre poster av samme type. Dersom du ikke tidligere har jobbet med strukturer som består av poster som inneholder lenker til poster av samme type, anbefaler vi at du setter deg inn i materialet om. La oss vurdere algoritmen for å tegne treet vist i fig. 6. Hvis hver linje anses som en node, da dette bildet tilfredsstiller fullt ut definisjonen av et tre gitt i forrige avsnitt. Ris. 6. Tre. Den rekursive prosedyren ville åpenbart tegne en linje (stammen opp til den første grenen), og deretter kalle seg for å tegne de to undertrærne. Undertrær skiller seg fra treet som inneholder dem i koordinatene til deres startpunkt, rotasjonsvinkel, stammelengde og antall grener de inneholder (en mindre). Alle disse forskjellene bør gjøres til parametere for den rekursive prosedyren. Et eksempel på en slik prosedyre, skrevet i Delphi, er presentert nedenfor: Prosedyre Tre(Lerret: TCanvas; //Lerret som treet skal tegnes på x,y: utvidet; //Rotkoordinater Vinkel: utvidet; //Vinkel som treet vokser ved Stammelengde: utvidet; //Stammelengde n: heltall / /Antall grener (hvor mange flere //rekursive anrop gjenstår)); var x2, y2: utvidet; //Trunk end (grenpunkt) begynne x2:= x + TrunkLength * cos(Angle); y2:= y - TrunkLength * sin(Angle); Canvas.MoveTo(round(x), round(y)); Canvas.LineTo(rund(x2), rund(y2)); hvis n > 1, begynn Tre(Lerret, x2, y2, Vinkel+Pi/4, 0,55*Bamlengde, n-1); Tre(Lerret, x2, y2, Angle-Pi/4, 0,55*TrunkLength, n-1); slutt; slutt; For å få fig. 6 ble denne prosedyren kalt med følgende parametere: Tre(Bilde1.Lerret, 175, 325, Pi/2, 120, 15); Merk at tegning utføres før rekursive anrop, det vil si at treet tegnes i direkte rekkefølge. Ifølge legenden i det store tempelet i Banaras, under katedralen som markerer midten av verden, er det en bronseskive som 3 diamantstenger er festet på, en alen høy og tykk som en bie. For lenge siden, helt i begynnelsen av tiden, begikk munkene i dette klosteret fornærmelse overfor guden Brahma. Sint Brahma reiste tre høye stenger og plasserte 64 skiver av rent gull på en av dem, slik at hver mindre disk ligger på mer. Så snart alle 64 skivene er overført fra stangen som Gud Brahma plasserte dem på da han skapte verden, til en annen stang, vil tårnet sammen med templet bli til støv og verden vil gå til grunne under torden. Uavhengig av Brahma ble dette puslespillet foreslått på slutten av 1800-tallet av den franske matematikeren Edouard Lucas. Den solgte versjonen brukte vanligvis 7-8 disker (fig. 7). Ris. 7. Puslespill "Towers of Hanoi". La oss anta at det finnes en løsning for n-1 disk. Så for å skifte n disker, fortsett som følger: 1) Skift n-1 disk. Fordi for saken n= 1 omorganiseringsalgoritmen er åpenbar, så ved induksjon, ved hjelp av handlinger (1) – (3), kan vi omorganisere et vilkårlig antall disker. La oss lage en rekursiv prosedyre som skriver ut hele sekvensen av omorganiseringer for et gitt antall disker. Hver gang en slik prosedyre kalles, skal den skrive ut informasjon om ett skift (fra punkt 2 i algoritmen). For omorganiseringer fra punkt (1) og (3), vil prosedyren kalle seg selv med antall disker redusert med én. //n – antall disker //a, b, c – pin-nummer. Skifting gjøres fra pinne a, //til pinne b med hjelpepinne c. prosedyre Hanoi(n, a, b, c: heltall); start hvis n > 1 så begynner Hanoi(n-1, a, c, b); writeln(a, " -> ", b); Hanoi (n-1, c, b, a); end else writeln(a, " -> ", b); slutt; Merk at settet med rekursivt kalte prosedyrer i dette tilfellet danner et tre som krysses i omvendt rekkefølge. Oppgave parsing er å beregne verdien av uttrykket ved å bruke en eksisterende linje som inneholder et aritmetisk uttrykk og de kjente verdiene til variablene som er inkludert i den. Prosessen med å beregne aritmetiske uttrykk kan representeres som et binært tre. Faktisk krever hver av de aritmetiske operatorene (+, –, *, /) to operander, som også vil være aritmetiske uttrykk og følgelig kan betraktes som undertrær. Ris. Figur 8 viser et eksempel på et tre som tilsvarer uttrykket: Ris. 8. Syntakstreet tilsvarende aritmetisk uttrykk (6). I et slikt tre vil endenodene alltid være variabler (her x) eller numeriske konstanter, og alle interne noder vil inneholde aritmetiske operatorer. For å utføre en operator må du først evaluere operandene. Dermed bør treet på figuren krysses i terminal rekkefølge. Tilsvarende sekvens av noder kalt omvendt polsk notasjon aritmetisk uttrykk. Når du konstruerer et syntakstre, bør du være oppmerksom på følgende funksjon. Hvis det for eksempel er et uttrykk og vi vil lese operasjonene for addisjon og subtraksjon fra venstre til høyre, så vil det riktige syntakstreet inneholde et minus i stedet for et pluss (fig. 9a). I hovedsak tilsvarer dette treet uttrykket. Det er mulig å gjøre opprettelsen av et tre lettere hvis du analyserer uttrykk (8) omvendt, fra høyre til venstre. I dette tilfellet er resultatet et tre med fig. 9b, tilsvarende tre 8a, men krever ikke utskifting av skilt. På samme måte, fra høyre til venstre, må du analysere uttrykk som inneholder multiplikasjons- og divisjonsoperatorer. Ris. 9. Syntakstre for uttrykk en – b + c når du leser fra venstre til høyre (a) og fra høyre til venstre (b). Denne tilnærmingen eliminerer ikke rekursjon fullstendig. Det lar deg imidlertid begrense deg til kun ett kall til en rekursiv prosedyre, noe som kan være tilstrekkelig hvis motivet er å maksimere ytelsen. Ideen med denne tilnærmingen er å erstatte rekursive anrop med en enkel sløyfe som vil bli utført så mange ganger som det er noder i treet dannet av de rekursive prosedyrene. Hva som skal gjøres på hvert trinn, bør bestemmes av trinnnummeret. Match trinnnummeret og nødvendige handlinger– Oppgaven er ikke triviell, og i hvert tilfelle må den løses separat. For eksempel, la oss si at du vil gjøre k nestede løkker n trinn i hver: For i1:= 0 til n-1 gjør for i2:= 0 til n-1 gjør for i3:= 0 til n-1 gjør … Hvis k er ukjent på forhånd, er det umulig å skrive dem eksplisitt, som vist ovenfor. Ved å bruke teknikken demonstrert i avsnitt 6.5, kan du få det nødvendige antallet nestede løkker ved å bruke en rekursiv prosedyre: Prosedyre NestedCycles(Indekser: rekke av heltall; n, k, dybde: heltall); var i: heltall; begynne hvis dybde For å bli kvitt rekursjon og redusere alt til én syklus, merk at hvis du nummererer trinnene i radix-tallsystemet n, så har hvert trinn et tall som består av tallene i1, i2, i3, ... eller de tilsvarende verdiene fra indeksene. Det vil si at tallene tilsvarer verdiene til syklustellerne. Trinnnummer i vanlig desimalnotasjon: Det vil være totalt trinn n k. Ved å gå gjennom tallene deres i desimaltallsystemet og konvertere hvert av dem til radikssystemet n, får vi indeksverdiene: M:= round(IntPower(n, k)); for i:= 0 til M-1 begynner Nummer:= i; for p:= 0 til k-1 begynner Indekser:= Antall mod n; Antall:= Antall div n; slutt; Gjøre noe (indekser); slutt; Kontrollspørsmål 1. Bestem hva følgende rekursive prosedyrer og funksjoner vil gjøre. (a) Hva vil følgende prosedyre skrives ut når Rec(4) kalles? Prosedyre Rec(a: heltall); begynne å skriveln(a); hvis a>0 så Rec(a-1); skrivln(a); slutt; (b) Hva blir verdien av funksjonen Nod(78, 26)? Funksjon Nod(a, b: heltall): heltall; begynne hvis a > b så Nikk:= Nikk(a – b, b) ellers hvis b > a så Nikk:= Nikk(a, b – a) annet Nikk:= a; slutt; (c) Hva vil bli skrevet ut av prosedyrene nedenfor når A(1) kalles? Prosedyre A(n: heltall); prosedyre B(n: heltall); prosedyre A(n: heltall); begynne å skriveln(n); B(n-1); slutt; prosedyre B(n: heltall); begynne å skriveln(n); hvis n (d) Hva vil prosedyren nedenfor skrives ut når du kaller BT(0, 1, 3)? Prosedyre BT(x: reell; D, MaksD: heltall); begynne hvis D = MaksD så skrivln(x) ellers begynner BT(x – 1, D + 1, MaksD); BT(x + 1, D + 1, MaksD); slutt; slutt; 2. Ouroboros - en slange som sluker sin egen hale (fig. 14) når den er utfoldet har en lengde L , diameter rundt hodet D , bukveggtykkelse d . Bestem hvor mye hale han kan presse inn i seg selv og hvor mange lag skal halen legges i etter det? Ris. 14. Utvidede ouroboros. 3. For treet i fig. 10a indikerer sekvensen av besøksnoder i forover-, revers- og endegjennomløpsrekkefølge. 4. Vis treet definert grafisk ved hjelp av nestede parenteser: (A(B(C, D), E), F, G). 5. Vis grafisk syntakstreet for følgende aritmetiske uttrykk: Skriv dette uttrykket i omvendt polsk notasjon. Oppgaver 1. Etter å ha beregnet faktoren tilstrekkelig ganger (en million eller mer), sammenligne effektiviteten til rekursive og iterative algoritmer. Hvor mange ganger vil utførelsestiden avvike, og hvordan vil dette forholdet avhenge av tallet hvis faktorial beregnes? 2. Skriv en rekursiv funksjon som kontrollerer riktig plassering av parenteser i en streng. Hvis ordningen er riktig, er følgende betingelser oppfylt: (a) antall åpnings- og lukkeparenteser er likt. Eksempler på feil plassering:)(, ())(, ())((), osv. 3. Linjen kan inneholde både parentes og firkantede parenteser. Hver åpningsparentes har en tilsvarende avsluttende parentes av samme type (runde - runde, firkantet - firkantet). Skriv en rekursiv funksjon som sjekker om parentesene er plassert riktig i dette tilfellet. Eksempel på feil plassering: ([) ]. 4. Antall vanlige brakettstrukturer med lengde 6 er 5: ()()(), (())(), ()(()), ((())), (()()). Merk: Riktig parentesstruktur med minimumslengde "()". Strukturer med lengre lengde oppnås fra strukturer med kortere lengde på to måter: (a) hvis den mindre strukturen er tatt i parentes, 5. Lag en prosedyre som skriver ut alle mulige permutasjoner for heltall fra 1 til N. 6. Lag en prosedyre som skriver ut alle delsett av settet (1, 2, ..., N). 7. Lag en prosedyre som skriver ut alle mulige representasjoner av det naturlige tallet N som summen av andre naturlige tall. 8. Lag en funksjon som beregner summen av matriseelementene ved hjelp av følgende algoritme: matrisen deles i to, summene av elementene i hver halvdel beregnes og legges til. Summen av elementene i halve matrisen beregnes ved hjelp av samme algoritme, det vil si igjen ved å dele i to. Divisjoner skjer til de resulterende delene av matrisen inneholder ett element hver, og beregning av summen blir derfor triviell. Kommentar: Denne algoritmen er et alternativ. Når det gjelder matriser med reell verdi, tillater det vanligvis mindre avrundingsfeil. 10. Lag en prosedyre som tegner Koch-kurven (Figur 12). 11. Gjengi figuren. 16. På figuren, ved hver neste iterasjon er sirkelen 2,5 ganger mindre (denne koeffisienten kan gjøres til en parameter). 1. D. Knuth. Kunsten å programmere data. v. 1. (avsnitt 2.3. «Trær»). Rekursjoner er interessante hendelser i seg selv, men i programmering er de spesielt viktige i spesifikke tilfeller. Når de møter dem for første gang, har et ganske betydelig antall mennesker problemer med å forstå dem. Dette skyldes det enorme feltet av potensielle anvendelser av selve begrepet, avhengig av konteksten som "rekursjon" brukes i. Men vi kan håpe at denne artikkelen vil bidra til å unngå mulige misforståelser eller misforståelser. Ordet "rekursjon" har en hel rekke betydninger, som avhenger av feltet det brukes i. Den universelle betegnelsen er som følger: rekursjoner er definisjoner, bilder, beskrivelser av objekter eller prosesser i selve objektene. De er bare mulige i tilfeller der objektet er en del av seg selv. Matematikk, fysikk, programmering og en rekke andre vitenskapelige disipliner definerer rekursjon på hver sin måte. Praktisk bruk hun fant det på jobben informasjonssystemer og fysiske eksperimenter. Rekursive situasjoner, eller rekursjon i programmering, er øyeblikk når en programprosedyre eller funksjon kaller seg selv. Uansett hvor rart det kan høres ut for de som begynte å lære programmering, er det ikke noe rart her. Det bør huskes at rekursjoner ikke er vanskelige, og i noen tilfeller erstatter de løkker. Hvis datamaskinen er riktig instruert til å kalle en prosedyre eller funksjon, vil den ganske enkelt begynne å utføre den. Rekursjon kan være endelig eller uendelig. For at den første skal slutte å forårsake seg selv, må den også inneholde vilkår for oppsigelse. Dette kan være å redusere verdien av en variabel og, når en viss verdi er nådd, å stoppe samtalen og avslutte programmet / gå videre til påfølgende kode, avhengig av behovene for å oppnå bestemte mål. Med uendelig rekursjon mener vi at den vil bli kalt så lenge datamaskinen eller programmet den kjører i kjører. Det er også mulig å organisere kompleks rekursjon ved å bruke to funksjoner. La oss si at det er A og B. Funksjon A har et kall til B i koden sin, og B indikerer på sin side for datamaskinen behovet for å utføre A. Komplekse rekursjoner er en vei ut av en rekke komplekse logiske situasjoner for datamaskiner logikk. Hvis leseren av disse linjene har studert programløkker, har han sannsynligvis allerede lagt merke til likhetene mellom dem og rekursjon. Generelt kan de faktisk utføre lignende eller identiske oppgaver. Ved å bruke rekursjon er det praktisk å simulere driften av en sløyfe. Dette er spesielt nyttig der selve syklusene ikke er veldig praktiske å bruke. Prskiller seg ikke mye mellom ulike programmeringsspråk på høyt nivå. Men likevel har rekursjon i Pascal og rekursjon i C eller et annet språk sine egne kjennetegn. Det kan med hell implementeres på lavnivåspråk som Assembly, men dette er mer problematisk og tidkrevende. Hva er et "tre" i programmering? Dette er et begrenset sett som består av minst én node som: Med andre ord: trær inneholder undertrær, som inneholder flere trær, men i mindre antall enn det forrige treet. Dette fortsetter til en av nodene ikke lenger kan bevege seg fremover, og dette vil markere slutten på rekursjonen. Det er en nyanse til ved den skjematiske representasjonen: vanlige trær vokser fra bunn til topp, men i programmering er de tegnet omvendt. Noder som ikke har noen fortsettelse kalles bladnoder. For enkel betegnelse og bekvemmelighet brukes genealogisk terminologi (forfedre, barn). Rekursjon i programmering har funnet sin anvendelse i å løse en rekke komplekse oppgaver. Hvis det er nødvendig å foreta bare ett anrop, er det lettere å bruke en integrasjonssløyfe, men med to eller flere repetisjoner, for å unngå å bygge en kjede og utføre deres utførelse i form av et tre, brukes rekursive situasjoner. For en bred klasse av oppgaver, organisering databehandling Denne metoden er den mest optimale med tanke på ressursforbruk. Så, rekursjon i Pascal eller noe annet språk på høyt nivå programmering er et anrop til en funksjon eller prosedyre inntil betingelsene er oppfylt, uavhengig av antall eksterne anrop. Med andre ord kan et program bare ha ett anrop til en subrutine, men det vil skje til et forhåndsbestemt øyeblikk. På noen måter er dette en analog av en syklus med sine egne bruksdetaljer. På tross av generell ordning implementeringer og spesifikk applikasjon i hvert enkelt tilfelle, har rekursjon i programmering sine egne egenskaper. Dette kan skape problemer under søk nødvendig materiale. Men du bør alltid huske: hvis et programmeringsspråk kaller funksjoner eller prosedyrer, er det mulig å kalle rekursjon. Men de viktigste forskjellene vises når du bruker lav og høye språk programmering. Dette gjelder spesielt for funksjoner for programvareimplementering. Utførelse avhenger til syvende og sist av hvilken oppgave som stilles, og rekursjon skrives i samsvar med den. Funksjonene og prosedyrene som brukes er forskjellige, men målet deres er alltid det samme - å tvinge dem til å ringe seg selv. For nybegynnere kan det være vanskelig å forstå i begynnelsen, så du trenger eksempler på rekursjon, eller i det minste ett. Derfor bør vi gi et lite eksempel fra hverdagen som vil bidra til å forstå selve essensen av denne mekanismen for å nå mål i programmering. Ta to eller flere speil, plasser dem slik at alle de andre vises i ett. Du kan se at speilene reflekterer seg selv flere ganger, og skaper en uendelig effekt. Rekursjoner er billedlig talt refleksjoner (det vil være mange av dem). Som du kan se, er det ikke vanskelig å forstå, hvis bare du har lysten. Og ved å studere programmeringsmateriell kan du videre forstå at rekursjon også er en veldig enkel oppgave å fullføre. Applikasjonsprogrammering handler alltid om å løse anvendte problemer ved å bruke programmererens innsats for å oppnå resultater under ikke-ideelle forhold. Det er nettopp på grunn av denne verdens ufullkommenhet og de begrensede ressursene at behovet for programmerere oppstår: noen trenger å hjelpe teoretikere med å presse sin harmoniske og vakre teori ut i praksis. Def fib(n): hvis n<0: raise Exception("fib(n) defined for n>=0") hvis n> @memoized def fib(n): hvis n<0: raise Exception("fib(n) defined for n>=0") hvis n>1: returner fib(n-1) + fib(n-2) returner n Def fib(n): hvis n<0: raise Exception("fib(n) defined for n>=0") n0 = 0 n1 = 1 for k i område(n): n0, n1 = n1, n0+n1 returnerer n0 tex \begin(tikzpicture) \node (er-rot) (+) child ( node (2) ) child ( node (2) ); \path (er-root) +(0,+0.5\tikzleveldistance) node (\textit(Tre 1)); \end(tikzpicture) \begin(tikzpicture) \node (er-root) (*) barn ( node (+) child (node(2)) child (node(2)) ) child ( node (+) child (node) (2)) barn (node(2)) ); \path (er-root) +(0,+0.5\tikzleveldistance) node (\textit(Tre 2)); \end(tikzbilde) Som du lett kan se, blir oppgaven til en enkel "dybde-første gjennomgang av treet": for hver node viser vi innholdet til alle barna, hvoretter vi viser selve noden. Det vil si at koden vil være: KlassetreNode(objekt): def __init__(selv, verdi=Ingen, barn=): self.value = verdi self.children = barn def printTree(node): for barn i node.children: printTree(child) print node.value , def main(): tree1 = TreeNode("+", [ TreeNode(2), TreeNode(2) ]) tree2 = TreeNode("*", [ TreeNode("+", [ TreeNode(2), TreeNode(2) ) ]), TreeNode("+", [ TreeNode(2), TreeNode(2) ]) ]) print "Tree1:", printTree(tre1) print print "Tree2:", printTree(tre2) print if __name__ == "__main__": main() Det ser ut til at alt er bra! Koden fungerer fint så lenge treet oppfyller kravene: enhver node har en rekke barn (muligens tomme) og en viss verdi. Hvem kan fortelle hvilke andre krav til dette treet? Jeg vil ikke syte. Krav: ikke veldig dypt tre. Hvordan det? Det er hvordan: Def buildTree(depth): root = TreeNode("1") node = rot for k in range(depth): node = TreeNode("--", [ node ]) return node def depthTest(depth): tree = buildTree( depth) print "Tree of depth", depth, ":", printTree(tre) def main(): for d in range(10000): depthTest(d) La oss mentalt omskrive denne koden 1-i-1 i C++ (jeg overlater denne oppgaven til leseren som en oppvarming), og prøver å finne grensen når applikasjonen treffer en begrensning... for de late #inkludere Def printTree(node): opened = False for child in node.children: hvis ikke åpnet: print "(", opened = True printTree(child) print node.value, if opened: print ")", Ingenting har endret seg, det krasjer fortsatt når du prøver å skrive ut et tre med en dybde på 997. Og nå det samme, men på plussene... Oops. Dybden på stabelen i løpet av høsten er 87327. Stopp. Vi har nettopp lagt til en lokal variabel som ikke på noen måte påvirker algoritmen eller essensen av det som skjer, og den maksimale trestørrelsen ble redusert med 17 %! Og nå den morsomme delen - alt dette avhenger i stor grad av kompilatoralternativene, på hvilken plattform det kjøres på, i hvilket operativsystem og med hvilke innstillinger. Men det er ikke det morsomste. La oss forestille oss at denne funksjonen brukes av en annen funksjon. Alt er bra hvis hun er den eneste - vi kan beregne hvor mange faktiske skritt som er mindre enn maksimal dybde. Hva om denne funksjonen brukes fra en annen rekursiv? Da vil egenskapene til den funksjonen avhenge av dybden til den andre funksjonen. Slik slutter vår vakre enkle algoritme plutselig å passe inn i vår ufullkomne koffert. Jeg overlater til leseren å forestille seg hvor bra det er å ha slike begrensninger i en tjeneste som kjører i produksjon og gir en viss tjeneste til intetanende hackere, som ikke gjør annet enn å pirke på denne tjenesten med sine skitne uklare testere. For det første kan vi ikke vite nøyaktig hvor mye av det som allerede er brukt. For det andre kan vi ikke vite nøyaktig hvor mye som er igjen. For det tredje kan vi ikke garantere tilgjengeligheten av en viss størrelse på denne ressursen for hver samtale. For det fjerde kan vi ikke registrere forbruket av denne ressursen. Dermed blir vi avhengige av en ressurs som er jævla vanskelig å kontrollere og distribuere. Som et resultat kan vi ikke garantere noen ytelse for denne funksjonen/tjenesten. Det er bra hvis tjenesten vår fungerer i en administrert kontekst: java, python, .net, etc. Det er dårlig hvis tjenesten fungerer i et ukontrollert miljø: javascript (som alt er dårlig med). Det er enda verre hvis tjenesten kjører i C++, og dybden av rekursjon avhenger av dataene som sendes av brukeren. Så for å bli kvitt problemene som er skapt av rekursjon, kan du gjøre følgende (fra enkelt til komplekst): Frihetens grenseløse sødme Kanonisk ikke-rekursiv implementering av dybde-første tre-traversering: Her er den samme koden, bare skrevet "head-on", som bevarer konteksten (samtidig med komma mellom elementene): Def printTree(node): stack = [ (node, 0) ] mens len(stack)>0: i = len(stack)-1 node, fase = stack[i] if phase< len(node.children):
child = node.children
if phase == 0:
print "{",
if phase >0: print ",", stack.append((child, 0)) stack[i] = (node, fase+1) else: print node.value, if phase>0: print ")", del stack[i ] Hvorfor bruker du ikke rekursjon?
Hei N 2
…
Hei N 10
…
Hei N 1
…
Hei N 10
Hei N 10
…
Hei N 14. Gjentaksforhold. Rekursjon og iterasjon
5. Trær
5.1. Grunnleggende definisjoner. Måter å skildre trær på
a) Det er en spesiell node som kalles roten til dette treet.
b) De gjenværende nodene (unntatt roten) er inneholdt i parvise usammenhengende delsett, som hver igjen er et tre. Trær kalles undertrær av dette treet.

5.2. Passerende trær
5.3. Representasjon av et tre i datamaskinens minne

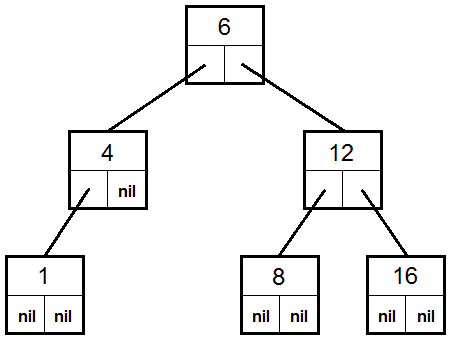
6. Eksempler på rekursive algoritmer
6.1. Tegne et tre

6.2. Hanoi-tårnene
Prosessen krever det større disk aldri funnet meg selv over noe mindre. Munkene er i dilemma: i hvilken rekkefølge skal de gjøre skiftene? Det er nødvendig å gi dem programvare for å beregne denne sekvensen.
2) Skift n disken på den gjenværende ledige pinnen.
3) Vi skifter stabelen fra n-1 disk mottatt i punkt (1) på toppen n-te disken.6.3. Parsing av aritmetiske uttrykk


7.3. Bestemme en trenode etter nummeret
La oss merke nok en gang at metoden ikke er universell, og du må finne på noe forskjellig for hver oppgave.
6. For grafen nedenfor (fig. 15), skriv ned adjacency-matrisen og insidensmatrisen.
(b) innenfor et hvilket som helst par er det en åpning - tilsvarende lukkebrakett, brakettene er plassert riktig.
Skriv et rekursivt program for å generere alle vanlige brakettstrukturer med lengde 2 n.
(b) hvis to mindre strukturer skrives sekvensielt.
Litteratur
2. N. Wirth. Algoritmer og datastrukturer.Hva er "rekursjon" egentlig?
Hva menes med rekursjon i programmering?

Rekursjonstrær

Hvorfor brukes det i programmering?

Forskjeller mellom rekursjon i ulike programmeringsspråk
Rekursjon er lett. Hvor lett er det å huske innholdet i en artikkel?

Rekursjon: Se rekursjon.
Alle programmerere er delt inn i 11 2 kategorier: de som ikke forstår rekursjon, de som allerede forstår, og de som har lært å bruke det. Generelt er jeg ikke annet enn papp, så du, leser, vil fortsatt måtte forstå Tao of Recursion på egen hånd, jeg vil bare prøve å gi ut noen magiske spark i riktig retning. – Hvordan er det bygget?
- Perfekt! Bare hånden stikker litt ut fra kofferten.
Det er nettopp når man prøver å plassere en sammenhengende teori om en algoritme i en hard ryggsekk av virkelige ressurser at man hele tiden må kutte og pakke om, og i stedet for de vakre og sammenhengende definisjonene til Fibonacci:
du må gjerde inn alle slags skitne hacks, alt fra:
Og til slutt slutt:Så hva er rekursjon?
Rekursjon er i hovedsak et bevis ved induksjon. Vi forteller deg hvordan du får et resultat for en bestemt tilstand, forutsatt at vi har et resultat for et annet sett med tilstander, og vi forteller deg også hvordan du får et resultat i de tilstandene som alt glir til på en eller annen måte. Hvis du venter gjester og plutselig legger merke til en flekk på dressen din, ikke bli lei deg. Dette kan fikses.
For eksempel kan flekker fra vegetabilsk olje enkelt fjernes med bensin. Bensinflekker kan enkelt fjernes med en alkalisk løsning.
Alkaliflekker forsvinner med eddikessens. Spor av eddikessens skal gnis med solsikkeolje.
Vel, du vet allerede hvordan du fjerner flekker fra solsikkeolje ...
La oss nå se på et klassisk eksempel: dybde-første tre-traversering. Men nei, la oss se på et annet eksempel: vi må skrive ut et tre med uttrykk i form av omvendt polsk notasjon. Det vil si at for tre 1 vil vi skrive ut "2 2 +" og for tre 2 "2 2 + 2 2 + *". 
Vi lanserer, og vips! "Tree of depth 997: RuntimeError: maksimal rekursjonsdybde overskredet." Vi ser i dokumentasjonen og finner funksjonen sys.getrecursionlimit. La oss nå gå bort fra verden av tolkede språk, og gå inn i verden av språk som kjører direkte på prosessoren. For eksempel i C++.
La oss kjøre ... "Bussfeil (kjernedumpet)". Etter gdb å dømme var stabelen på fallet 104790 bilder dyp. Hva skjer hvis vi ikke bare vil skrive ut fortløpende gjennom mellomrom, men også skrive ut "(" og ")" rundt uttrykk? Vel, det vil si at for tre 1 bør resultatet være (2 2 +) og for tre 2 - ((2 2 +)(2 2 +)*)? La oss skrive om... Så hva er problemet?
Å bruke en rekursiv algoritme innebærer å bruke en praktisk talt ukontrollerbar ressurs: anropsstakken. Hva å gjøre?
Hvis vi ikke jobber med en mikrokontroller, trenger vi ikke å bekymre oss for størrelsen på stabelen: det bør være nok for en normal kjede av samtaler. Forutsatt, selvfølgelig, at vi bryr oss om hygienen til lokale variabler: store objekter og arrays tildeles ved hjelp av minne (ny/malloc). Men bruk av rekursjon betyr at i stedet for et begrenset antall samtaler, vil vi ganske enkelt ha et tellbart antall av dem.
- Begrens maksimal størrelse/format/tall i innkommende data strengt. Hei, zip-bomber og lignende - noen ganger kan til og med en liten innkommende pakke forårsake stor oppstyr.
- Begrens den maksimale samtaledybden strengt til et bestemt nummer. Det er viktig å huske at dette tallet må være SVÆRT lite. Det vil si rundt hundrevis. Og pass på å legge til tester som sjekker at programmet ikke bryter med dette maksimale antallet. Dessuten, med maksimalt antall på alle mulige utførelsesgrener (hei til tildeling av lokale variabler på forespørsel). Og ikke glem å sjekke denne testen på forskjellige kompileringsalternativer og etter hver bygg.
- Begrens mengden stabel som brukes strengt. Ved å bruke komplekse løsninger og kunnskap om den praktiske implementeringen av kjøring i maskinvare, kan du få størrelsen på stabelen som brukes for øyeblikket (for eksempel å ta adressen til en lokal flyktig variabel). I noen tilfeller (for eksempel gjennom libunwind i Linux), kan du også få mengden stack tilgjengelig for gjeldende tråd, og ta forskjellen mellom dem Når du bruker denne metoden, er det viktig å ha tester som sjekker at beskjæring er fungerer garantert for alle typer inndata - for eksempel kan det være morsomt hvis kontrollen utføres i en metode, som er rekursiv gjennom 3-4 andre Og den kan feile i den mellomliggende... Men bare i utløsermodus, for eksempel etter at noen funksjoner er innebygd. Tester for maksimal akseptabel kompleksitet er imidlertid også viktige her, for ikke å ved et uhell kutte av noen av de riktige inndataforespørslene som klienter faktisk bruker.
- Den beste måten: bli kvitt rekursjon.Og ikke lyv at du er fri og hellig - Du er fanget og fanget.
Jeg åpnet himmelhvelvingen før deg!
Tidene endrer kurs - Se på håndflatene...
nekte frihet
Sergey Kalugin
Ja Ja. Etter å ha forstått rekursjonens Tao, forstår du også ikke-rekursjonens Tao. Nesten alle rekursive algoritmer har ikke-rekursive motstykker. Starter fra mer effektive (se Fibonacci ovenfor), og slutter med tilsvarende som bruker en kø i minnet i stedet for en anropsstabel.
def printTree(node): stack = [ (node, False, False) ] mens len(stack)>0: i = len(stack)-1 node, besøkt, åpnet = stack[i] hvis ikke besøkt: for barn i reversed(node.children): hvis ikke åpnet: skriv ut "(", opened = True stack.append((child, False, False)) visited = True stack[i] = (node, besøkt, åpnet) else: print node .value, hvis åpnet: skriv ut ")", del stack[i]
Som det er lett å se, har algoritmen ikke endret seg, men i stedet for å bruke anropsstakken, brukes stackarrayen, plassert i minnet, og lagrer både prosesseringskonteksten (i vårt tilfelle det åpnede flagget) og prosesseringskonteksten ( i vårt tilfelle, før eller etter behandling av barn). I tilfeller der du trenger å gjøre noe mellom hver av de rekursive samtalene, legges begge behandlingsfasene til. Vennligst merk: dette er en allerede optimalisert algoritme som legger alle barn til stabelen samtidig, og det er derfor den legges til i omvendt rekkefølge. Dette sikrer at rekkefølgen holdes den samme som den opprinnelige ikke-rekursive algoritmen.
Ja, overgangen til ikke-rekursive teknologier er ikke helt gratis: vi betaler med jevne mellomrom for dyrere - dynamisk minneallokering for å organisere stabelen. Dette lønner seg imidlertid: ikke alle lokale variabler er lagret i den "manuelle stabelen", men bare den minste nødvendige konteksten, hvis størrelse allerede kan kontrolleres. Den andre kostnadsposten: kodelesbarhet. Kode skrevet i ikke-rekursiv form er noe vanskeligere å forstå på grunn av forgreninger fra dagens tilstand. Løsningen på dette problemet ligger i området kodeorganisering: organisere trinn i separate funksjoner og navngi dem riktig.Ulykke
Til tross for tilstedeværelsen av en viss "ikke-rekursjonsskatt", anser jeg det personlig som obligatorisk å betale ethvert sted der data mottatt fra brukeren behandles på en eller annen måte.