Teknologi for datamigrering i store prosjekter. "Mapping" er et nytt LPgenerator-verktøy! Individuelle visningsfiler
Problem
Du har lastet ned en kostnadsregnskapsrapport og ønsker å vise den til ledelsen. For å gjøre dette må du komponere artikkeldataene regnskap- i henhold til forvaltningsregnskapsposter. Du vet hvordan regnskaps- og regnskapsartikler forholder seg til hverandre, men hver gang det tar for mye tid å utarbeide en slik rapport manuelt.
Løsning
Vi vil vurdere denne saken som en fortsettelse av den forrige. La oss forestille oss at du opprettet følgende katalog i Excel:
Fig.2.1. Katalog: kartlegging av BU- og CU-artikler
Til venstre er en kostnadspost (AC), til høyre er en forvaltningsregnskapspost (MA). Det er viktig at kostnadsposten kun vises én gang i første kolonne, ellers vil ikke kartleggingsmekanismen fungere som den skal.
(Forresten, det engelske ordet mapping er oversatt som visning eller korrespondanse, så oppslagsboken i i dette tilfellet- dette er en viss generell regel for hvordan BU-artikler gjenspeiles i OU-artikler).
Fig.2.2. Flat tabell: kostnadsrapport (fra "Kontoomsetning 20")
Vær oppmerksom på at kolonnen «Artikkel TC» har dukket opp i den 7. kolonnen. Overfor hver kostnadspost har vi plassert en administrasjonsregnskapspost. Dette kan gjøres manuelt, men det er mye mer praktisk å bruke dette verktøyet:
Fig.2.3. Flat tabell: kostnadsrapport (fra "Kontoomsetning 20")
Nederst i skjemaet står navnene på sidene: «Hjem» er en flat tabell som inneholder kostnadsdata (fig. 2.2), «spr» er en oppslagsbok (fig. 2.1).
Kolonnenumrene er angitt øverst i skjemaet. Så, i dette tilfellet, hvis dataene i kolonne 1 i katalogen og 3 på hovedsiden faller sammen, kopieres dataene fra 2. kolonne i katalogen til den 7. kolonnen på hovedsiden.
Dette skjemaet har også mange tilleggsalternativer. For eksempel kan du aktivere avmerkingsboksene "Attributt #2" og "Attributt #3", og deretter overføre data fra kolonne 2 i katalogen til kolonne 7 på hovedsiden hvis katalogen og hovedsiden samsvarer med to eller til og med tre detaljer på en gang.
Som et resultat av en så enkel operasjon, ved hjelp av en pivottabell, kan du bygge hele linjen ulike analytiske rapporter, hvor en av seksjonene vil inkludere analytikeren «Artikkel UU». For eksempel slik:
Fig.2.4. Kostnadsrapport for armeringsverksted
Sammenligning av kartlegging med VLOOKUP()
Mange brukere er kjent med og bruker funksjonen VLOOKUP() i denne typen situasjoner. Imidlertid fungerer VLOOKUP()-funksjonen bare bra på små volumer data, mens dette skjemaet gjør en utmerket jobb med å behandle Excel-tabeller, selv om du for eksempel har 5 000 rader i oppslagsboken og 300 000 rader på goav-siden. Prøv å sjekke det og du vil se at VLOOKUP() mislykkes ved slike volumer. I tillegg skaper funksjonen VLOOKUP() en betydelig belastning på Excel, og tvinger den til å utføre store mengder beregninger. Kartleggingsskjemaet unngår denne ulempen: det kjører én gang, varer i noen sekunder (i store mengder minutter) og etter det er det ingen ekstra belastning på Excel-fil er ikke lenger opprettet.
I forrige del så vi på typene relasjoner (en-til-en, en-til-mange, mange-til-mange), samt en klassebok og dens kartleggingsklasse BookMap. I den andre delen vil vi oppdatere bokklassen, lage de resterende klassene og koblinger mellom dem, som ble avbildet i forrige kapittel i databasediagrammet som ligger over underoverskriften 1.3.1 Relasjoner.
Kode for klasser og kartlegginger (Med kommentarer)
Klassebok
Offentlig klasse Bok ( //Unik identifikator offentlig virtuell int Id ( get; sett; ) // Tittel offentlig virtuell streng Navn ( get; sett; ) // Beskrivelse offentlig virtuell streng Beskrivelse ( get; sett; ) // Rating of the World of Fiction public virtual int MfRaiting ( get; set; ) //Sidetall public virtual int PageNumber ( get; set; ) //Link til bildet offentlig virtuell streng Bilde (get; set; ) //Dato for bokankomst (filter av nye elementer!) public virtual DateTime IncomeDate ( get; set; ) //Sjanger (Many-to-Many) //Hvorfor ISet og ikke IList? Bare én samling (IList) kan velges ved å bruke JOIN-henting, hvis du trenger flere enn én samling for JOIN-henting, så er det bedre å konvertere dem til en ISet offentlig virtuell ISet-samling
Offentlig klasse Forfatter ( offentlig virtuell int Id ( get; sett; ) //Navn-Etternavn offentlig virtuell streng Navn ( get; sett; ) //Biografi offentlig virtuell streng Biografi ( get; sett; ) //Bøker offentlig virtuell ISet
Klasse sjanger
Offentlig klasse Genre ( offentlig virtuell int Id ( get; sett; ) //Navn på sjangeren offentlig virtuell streng Navn (get; sett; ) //Engelsk navn på sjangeren offentlig virtuell streng EngName (get; sett; ) //Bøker offentlig virtuell ISet
Klassens mening:
Offentlig klasse Mind ( offentlig virtuell int Id ( get; sett; ) //Min mening offentlig virtuell streng MyMind ( get; sett; ) //Fantlabs mening offentlig virtuell streng MindFantLab ( get; sett; ) //Bestill offentlig virtuell bokbok ( get; set; ) ) //Mapping Mind public class MindMap:ClassMap
Klassesyklus (serie):
Offentlig klasse Series ( public virtual int Id ( get; set; ) public virtual string Name ( get; set; ) //Jeg opprettet en IList, ikke en ISet, fordi annet enn bok, er ikke serie assosiert med noe annet, selv om du kan gjøre og ISet offentlig virtuell IList
En liten forklaring
offentlig virtuell ISet
offentlig virtuell ISet
Hvorfor ISet
Kan ikke hente flere poser samtidig.
I slike tilfeller bruker vi ISet, spesielt siden sett er ment for dette (de ignorerer dupliserte poster).
Mange-til-mange forhold.
NHibernate har konseptet med et "hovedbord". Selv om mange-til-mange-forholdet mellom bok- og forfattertabellene er ekvivalent (En forfatter kan ha mange bøker, en bok kan ha mange forfattere), krever Nhibernate at programmereren spesifiserer tabellen som er lagret som nummer to (har en metode. omvendt ()), det vil si at først vil en post opprettes/oppdateres/slettes i boktabellen, og først deretter i forfattertabellen.
Cascade.All betyr å utføre overlappende operasjoner på lagre, oppdatering og sletting. Det vil si at når et objekt lagres, oppdateres eller slettes, kontrolleres alle avhengige objekter og opprettes/oppdateres/legges til (Ps. Kan skrives i stedet for Cascade.All -> .Cascade.SaveUpdate().Cascade.Delete())
Method.Table("Book_Author"); oppretter en "mellomliggende" tabell "Book_Author" i databasen.
Mange-til-en, en-til-mange forhold.
The.Constrained()-metoden forteller NHibernate at en post fra Book-tabellen må samsvare med en post fra Mind-tabellen (ID-en til Mind-tabellen må være lik ID-en til Book-tabellen)
Hvis du nå kjører prosjektet og ser på Bibilioteca-databasen, vil nye tabeller med allerede dannede koblinger dukke opp.
Deretter fyller du de opprettede tabellene med data...
For å gjøre dette vil vi lage en testapplikasjon som vil lagre data i databasen, oppdatere og slette dem, endre HomeController som følger (vi kommenterer unødvendige deler av koden):
public ActionResult Index() ( bruker (ISession session = NHibernateHelper.OpenSession()) (bruker (ITTransaction transaction = session.BeginTransaction()) ( //Create, add var createBook = new Book(); createBook.Name = "Metro2033" ; createBook.Description = "Post-apokalyptisk mystikk"; createBook.Authors.Add(ny forfatter (Navn = "Glukhovsky")); createBook.Genres.Add(ny sjanger (Navn = "Post-apokalyptisk mystikk")); createBook .Series = new Series ( Navn = "Metro" ); createBook.Mind = new Mind ( MyMind = "Post-apokalyptisk mystikk" ); session.SaveOrUpdate(createBook); //Update (By ID) //var series = session .Få
En liten forklaring
- var bøker = session.QueryOver
() Velg * Fra bok; - .JoinAlias(p => p.Sjangre, () => genreAl, JoinType.LeftOuterJoin)- ligner på å kjøre et SQL-skript:
VELG *FRA bok
indre JOIN Book_Genre PÅ book.id = Book_Genre.Book_id
VENSTRE JOIN Sjanger PÅ Book_Genre.Genre_id = Genre.id - .TransformUsing(Transformers.DistinctRootEntity)- Ligner på å kjøre et SQL-skript: VELG distinkt Book.Id..., (fjerner dupliserte poster med samme id)
Typer assosiasjoner
.JoinAlias(p => p.Sjangre, () => genreAl, JoinType.LeftOuterJoin)
- LeftOuterJoin - velger alle poster fra venstre tabell ( Bok), og legger deretter til de riktige tabellpostene til dem ( Sjanger). Hvis en tilsvarende oppføring ikke finnes i den høyre tabellen, vises den som Null
- RightOuterJoin er det motsatte av LEFT JOIN - den velger alle poster fra høyre tabell ( Sjanger), og legger deretter til venstre tabellposter til dem ( Bok)
- InnerJoin - velger bare de postene fra de venstre tabellene ( Bok) som har en tilsvarende oppføring fra høyre tabell ( Sjanger), og føyer dem deretter sammen med poster fra høyre tabell
La oss endre representasjonen som følger:
Indeksvisning
@modell IEnumerable @Html.ActionLink("Opprett ny", "Opprett")
@foreach (var element i modell) ( @Html.DisplayNameFor(modell => modell.navn)
@Html.DisplayNameFor(modell => modell.Mind)
@Html.DisplayNameFor(modell => modell.Serie)
@Html.DisplayNameFor(modell => modell.Forfattere)
@Html.DisplayNameFor(modell => modell.Sjangre)
Drift
}
@Html.DisplayFor(modelItem => item.Name)
@Html.DisplayFor(modelItem => item.Mind.MyMind) @(streng strSeries = item.Series != null ? item.Series.Name: null;) @Html.DisplayFor(modelItem => strSeries)
@foreach (var forfatter i item.Authors) ( string strAuthor = forfatter != null ? author.Name: null; @Html.DisplayFor(modelItem => strAuthor)
}
@foreach (var sjanger i item.Genres) ( string strGenre = genre!= null ? genre.Name: null; @Html.DisplayFor(modelItem => strGenre)
}
@Html.ActionLink("Rediger", "Rediger", ny ( id = item.Id )) | @Html.ActionLink("Detaljer", "Detaljer", ny ( id = item.Id )) | @Html.ActionLink("Slett", "Slett", ny ( id = item.Id ))
Etter å ha sjekket alle operasjonene én etter én, vil vi legge merke til at:
- Under Opprett- og Oppdater-operasjonene oppdateres alle data knyttet til boktabellen (fjern Cascade="save-update" eller cascade="all" og de tilknyttede dataene vil ikke bli lagret)
- Ved sletting slettes data fra Book, Mind, Book_Author-tabellene, men de resterende dataene slettes ikke fordi de har Cascade="save-update"
Kartlegging for klasser som har arv.
Hvordan kartlegge klasser som har arv? La oss si at vi har dette eksemplet:
//Klasse av todimensjonale former offentlig klasse TwoDShape ( //Width public virtual int Width ( get; set; ) // Høyde public virtual int Høyde ( get; set; ) ) // Class Triangle public class Triangle: TwoDShape ( / /Identifikasjonsnummer public virtual int Id ( get; set; ) //Type triangel public virtual string Style ( get; set; ) )
I prinsippet er det ikke noe komplisert i denne tilordningen; vi vil ganske enkelt lage en tilordning for den avledede klassen, det vil si Triangle-tabellen.
//Triangelkartlegging offentlig klasse TriangleMap: ClassMap
Etter oppstart av applikasjonen vil følgende (tomme) tabell vises i Biblioteca-databasen 
Tagger:
- asp.net mvc 4
- dvale
- sql server
Rask beslutningstaking av høy kvalitet fra bedriftsledelsen avhenger av et godt bygget regnskapssystem i selskapet. Økonomistyring her i henhold til allment akseptert praksis dette semesteret betyr bruk av regnskaps- og økonomistyringsprinsipper for å løse problemer på følgende områder av virksomheten:
- utvikling og implementering av forretningsstrategi;
- gjennomføring av planlegging og kontroll;
- effektiv bruk av ressurser;
- øke operasjonell effektivitet;
- bevaring av materielle og immaterielle eiendeler;
- styring av forretningsprosesser i bedrifter og internt i selskapet
I alle fall utføres tilgang til kontoinformasjon vha forskjellige typer rapporter.
Siden innsamling og lagring av data om en bedrifts økonomiske aktiviteter er en ganske arbeidskrevende og kostbar prosess, blir effektiv bruk av denne informasjonen en viktig oppgave og konkurransefordel. Mengden informasjon som samles inn bestemmes av selskapets ledelse som en kompromissløsning mellom statens og tilsynsmyndighetenes krav til informasjonsavsløring og det maksimale volumet av informasjon (finansiell, teknologisk, statistisk) som oppstår i prosessen med virksomheten til virksomheten. .
Den mest effektive måten å bruke informasjonen som genereres i aktivitetsprosessen er å lage et datavarehus (datewarehouse), på grunnlag av hvilket, ved hjelp av OLAP-teknologier, enhver bedriftsleder kan generere en rapport for å analysere data i den analytiske konteksten han trenger og gi seg selv informasjon for beslutningstaking.
Men for tiden er det vanligste alternativet å lage et informasjonssystem der data samles, og som regel er det en tilpasset rapportgenerator som utfyller standardrapportene levert av systemutvikleren.
Vanligvis utviklere programvare tilby brukere regelmessig oppdaterte former for ekstern (for tilsynsmyndigheter) rapportering (regnskap og skatt) og annonsere muligheten for å lage alle typer ledelsesrapporter som kreves av virksomheten. Den genererte rapporten er imidlertid ikke nødvendigvis godt utformet.
Bedriften står alene med problemet med å generere (fylle ut) rapporter på riktig måte.
Behovet for en virksomhet å generere rapportering i henhold til internasjonale standarder kan bare forverre situasjonen.
Det sentrale i rapporteringen i alle saker er behovet for å skape en sammenheng mellom legitimasjon i informasjonssystemer og tilsvarende felt i rapporteringsskjemaer.
Følgende alternativer for å organisere forholdet er mulige:
- I form av en tabell som beskriver sammenhenger eller samsvar mellom rapportfelt og data i systemet (etterfulgt av å skrive en algoritme for automatisk rapportgenerering).
- Ved å manuelt velge nødvendig informasjon (med fullstendig mangel på evne til å automatisere rapporten).
- En blandet versjon, som krever tilstedeværelse av interrelasjonstabeller og manuell dekoding og justeringer ved generering av rapporter.
Det første alternativet for å organisere forholdet mellom informasjonsregnskapssystemer med rapporteringsskjemaer (gjennom tabeller som beskriver relasjoner) kalles " kartlegging".
Kartlegging (i vid forstand) er transformasjon av data fra en form til en annen. For regnskap er kartlegging sammenstillingen av en tabell over samsvar mellom regnskapskontoer fra forskjellige kontoplaner, for eksempel den russiske kontoplanen og GAAP (IFRS) kontoplan (eller kontoplan for ledelsesregnskap).
Eksempel 1. Blandet versjon av organiseringen av kommunikasjon.
De fleste selskaper utarbeider rapporter, for eksempel under IFRS, gjennom transformasjon. Metoden er basert på en tilnærming der informasjon generert i henhold til russiske standarder analyseres og justeres for å bringe den i samsvar med IFRS.
Rapportering transformeres i minst fire trinn ved hjelp av kartleggingstabeller og manuelle justeringer.
1. trinn. Strukturell transformasjon av balanse og resultatregnskap. Resultatet er en omgruppering og aggregering av enkeltposter i regnskapet for å utarbeide en database for etterfølgende justering av posteringer. Samtidig inneholder kartleggingstabellen finansiell rapporteringsindikatorer under RAS og deres refleksjon i delårsrapportering under IFRS.
2. trinn. Gjennomføre justering av posteringer med sikte på å eliminere kvalitative forskjeller mellom russisk rapportering og rapportering under IFRS. Utført for hånd av en transformasjonsspesialist.
3. trinn. Utarbeidelse av rapportering etter IFRS basert på transformerte balanser, resultatregnskap og andre former. Kartleggingstabellen inkluderer delårsrapporteringstall under IFRS og en beskrivelse av justeringene gjort av transformasjonsspesialisten.
4. trinn. Utarbeidelse av den beskrivende delen av rapporten.
Tabell 1. Illustrasjon av sammenhengen mellom den russiske kontoplanen og GAAP-kontoplanen (utdrag)
Salg – hovedaktivitet |
Salg/inntekter – hovedaktivitet |
||
Salgskostnader |
|||
Bruttofortjeneste |
Netto salg |
||
Generelt, kommersiell og Administrative kostnader |
Salg av generelle og administrative utgifter |
||
Kartleggingstabeller brukes også i genereringen av konsernledelsesrapportering (vanligvis i holdingselskaper og selskaper med filialer).
Grunnlaget for å sette opp kartlegging er å gruppere regnskapsdata på en bestemt måte (i henhold til selskapsstandarder).
Enkelt sagt, når vi oppretter en bedriftsrapporteringslinje, angir vi nøyaktig hvilke omsetninger (eller kontosaldo (underkontoer)) og i hvilken rekkefølge som skal brukes automatisk system regnskap for å danne denne linjen.
Kartlegging er reglene du har fastsatt, som rapportene du trenger blir generert etter. De tekniske prinsippene for å generere kartlinjer er de samme for alle rapporteringsskjemaer, den eneste forskjellen er innholdet.
I denne forbindelse bør det bemerkes at kartlegging må konfigureres av kvalifiserte spesialister og, viktigere, på en enhetlig metodisk måte. Kartleggingsprosedyren krever ganske mye tid.
Grunnlaget for ledelsesregnskap (samt regnskap) er: kontoplan, budsjettposter og ulike analytiske oppslagsverk.
Imidlertid skiller styringskontoplanen seg vesentlig fra standard kontoplan, som brukes for regnskap for regnskap, siden noen av kontoene til styringskontoplanen (heretter kalt MCA) kan ha mer detaljerte analyser, og den andre delen kan ha mer omfattende analyser (alt avhenger av de spesifikke foretakene). Strukturen i analytiske oppslagsverk er også annerledes, siden ledelsesrapporter krever presentasjon av regnskapsinformasjon i en helt annen sammenheng enn for regnskapsrapporter.
Selvfølgelig, i praksis, kobler indikatorer ( kartlegging) ledelse, skatt og regnskap (finansiell) regnskap forårsaker mange problemer.
La oss se på noen av dem.
1. Mangel på analyser i arbeidskontoplanen (heretter kalt WCA) til selskapet.
Dette er forståelig, siden bedrifter som ble opprettet for en dag, ikke alltid hadde en langsiktig strategi, og aksjonærenes interesser ikke alltid ble respektert. I dag har selve forretningskulturen endret seg. Aksjonærer, inkludert staten, viser økende interesse for hvor kompetent og dyktig ledere på alle nivåer styrer virksomheten.
Løsningen på dette problemet er å utvide og supplere selskapets eksisterende kassesystem og gradvis akkumulere informasjon på nyinnførte kontoer (underkonti).
Å forstå hovedtilnærmingene til å konstruere en kontoplan, så vel som de tre komponentene (økonomi, skatt, ledelse) i et enhetlig regnskapssystem i et selskap, forhåndsbestemmer behovet for å fremheve tre grunnleggende komponenter i en systematisk tilnærming til det finansielle regnskapssystemet av en kommersiell organisasjon, nemlig:
- finansregnskap);
- avgift;
- ledelsesmessig.
Mulige tolkninger av de økonomiske, skattemessige og ledelsesmessige komponentene i en systematisk tilnærming til RPS er presentert nedenfor.
Økonomisk (regnskapsmessig) komponent. Bruken av RPS bør sikre muligheten for å generere alle (uten unntak) resulterende regnskapsmessige og analytiske indikatorer for ekstern finansiell rapportering og forklarende notater i sammenheng med hovedbokregnskapet på rapporteringsdatoen. Blokken med regnskapskontoer til RPS som er involvert i dannelsen av eksterne regnskapsrapporter, er finansregnskap. I sin tur er finansregnskap delt inn i analytiske og syntetiske. Underkontoer finansregnskap RPS er mellomliggende mellom analytisk og syntetisk. Dessuten kan finansanalytiske og syntetiske kontoer, så vel som underkontoer, representere en integrert del av styringskomponenten i RPS. Så for eksempel dataene reflektert i separate underkontoer til finanskonto 90 "Salg". viktig for å ta ledelsesbeslutninger.
Når du danner en gruppe finanskontoer til RPS, må følgende krav oppfylles:
- mellom eksterne regnskapsrapporteringsposter og finanskontosaldoer må det etableres en korrespondanse som ikke krever ytterligere logiske operasjoner for å bestemme typen rapporteringspost;
- det minste mulige settet med finansielle kontoer til RPS må være målrettet utformet basert på sammensetningen av indikatorer for ekstern finansiell rapportering;
- hver ekstern finansiell rapporteringsindikator må hentes fra finansregnskapsdata ved bruk av RPS uten ytterligere dekoding eller justeringer.
Skattekomponent. Bruk av RPS i regnskapssystemet gir mulighet til å beregne skattegrunnlag og skattemessig overskuddsbeløp i henhold til kravene i kap. 25 Skattekode for den russiske føderasjonen. Implementeringen av skattekomponenten i en systematisk tilnærming til RPS innebærer:
- organisering av analytisk finansiell og skattemessig regnskapsføring av utgifter og inntekter for å identifisere deres innvirkning på mengden av skattegrunnlaget for beregning av overskuddsskatten til en kommersiell organisasjon ved å detaljere finansregnskapet (01 - 99) RPS;
- utvikling av en liste over skattekontoer (for eksempel 101–199). Implementeringen deres vil gjøre det mulig å føre registreringer av avvik i regnskapsdataene til finans- og skatteregnskapsobjekter for å opprette skatteregnskap og skatterapportering;
- utvikling av regler som gjør det mulig å justere effekten av skattekomponenten på den enhetlige integrerte regnskapsrapporteringen for å eliminere duplisering av rapportering (resulterende) regnskaps- og analytiske indikatorer.
Ledelseskomponent. I RPS, for å få de resulterende regnskaps- og analytiske indikatorene for ledelsens interne rapportering og ledelsesregnskap, tildeles en blokk med ledelseskontoer (for eksempel 201–299). På disse forvaltningskontiene foretas det dobbelte justeringer av finansregnskap 01–99 basert på brukernes krav til intern styringsrapportering. I fremtiden vil dataene om forvaltningskonto 201–299, ved bruk av visse regler, supplere (korrigere) dataene på finansregnskap 01–99. Resultatet av slike handlinger er indikatorer på intern ledelsesrapportering.
Implementeringen av ledelsesaspektet i en systematisk tilnærming til dannelsen av RPS innebærer utvikling av:
- bestemmelser regnskapsprinsipper(ekstern og intern), klargjøring av kriteriene for anerkjennelse av regnskapsobjekter, vurdering av dem, samt avsløring av innholdet i ledelsesrapporteringsposter;
- undersystem av administrasjonskontoer til den forente RPS, nødvendig for å registrere og oppsummere avvik fra administrasjonsregnskapsdata fra finansregnskapsdata;
- alternativ finansiell rapporteringssammensetning av ledelsesrapporteringsskjemaer.
I tillegg, når du danner en blokk med administrasjonskontoer for RPS, er det nødvendig å utvikle en tabell "Relasjon (kartlegging) mellom undersystemene til finans- og styringskontoer med indikatorer for alternativ ledelsesrapportering."
Tabell 2. Kartlegging av russiske (finansielle) regnskapsoperasjoner for å generere linjer i selskapsrapporteringsskjemaet "Saldo" (utdrag)
Balanselinje |
Regnskapskonto |
Utvalg etter subconto 1 |
Corr. regnskapskonto |
Utvalg etter subconto 1 |
Utvalgsformel |
||
Utvalg etter subconto 2 |
Utvalg etter subconto 2 |
Inverter tegn |
|||||
Utvalg etter subconto 3 |
Utvalg etter subconto 3 |
MVA regnskap |
|||||
Utvalg etter subconto 4 |
Utvalg etter subconto 4 |
Utvid med |
|||||
Utvalg etter subconto 5 |
Utvalg etter subconto 5 |
Deltakelse i en gruppekonto |
|||||
BL00102 Sett i drift (+) |
|||||||
Sett i drift (+) |
|||||||
Sett i drift (+) |
|||||||
Sett i drift (+) |
|||||||
Sett i drift (+) |
|||||||
Sett i drift (+) |
|||||||
Utvilsomt er beslutningen om å opprette et integrert regnskapssystem (økonomi, skatt og styring) i en kommersiell organisasjon og å utvikle en enhetlig arbeidskontoplan for et slikt system basert på en standard kontoplan ikke entydig. Teoretisk sett kan følgende tilnærminger brukes for å konstruere en fungerende kontoplan for en kommersiell organisasjon (i tilfelle bruk av kontoplaner for tre typer regnskap):
- en enkelt integrert kontoplan for finans-, skatte- og ledelsesregnskap;
- integrert kontoplan for finans- og skatteregnskap, autonom kontoplan for ledelsesregnskap;
- integrert kontoplan for finans- og ledelsesregnskap; autonom kontoplan for skatteregnskap;
- integrert kontoplan for skatt og ledelsesregnskap; autonom kontoplan for finansregnskap;
- autonome kontoplaner for finans-, skatte- og ledelsesregnskap.
2. Problemer med å konstruere oppslagsverk og klassifiserere, hvorav de viktigste er:
- duplisering av informasjon i kataloger;
- Feil koding av termkataloger.
Det hender for eksempel ofte at det ikke er noen enhetlig prosedyre for å tildele koder og navn; samme motpart kan være oppført i katalogen to ganger (Romashka LLC og Romashka LLC, andre alternativer og kombinasjoner) eller under forskjellige navn (for eksempel under full og under forkortet). Å søke etter de nødvendige dataene i et informasjonssystem ved å bruke ustrukturerte kataloger er ganske komplisert og upraktisk. I tillegg forårsaker rot i oppslagsverk feil i rapporteringen.
For eksempel opprettholder hvert foretak som er en del av beholdningen, til en viss grad, uavhengig primærregistrering, utvikler og oppdaterer sine egne kataloger. Dette arbeidet ved bedrifter utføres vanligvis av forskjellige tjenester: finansavdelinger, markedsavdeling, Justisdepartementet etc. Alt dette lar deg ta optimale ledelsesbeslutninger innenfor en spesifikk virksomhet. Forståelse og evne til å analysere den nåværende tilstanden til bedriften som helhet er imidlertid svært vanskelig på grunn av informasjonens ustrukturerte og enhetlige natur.
En annen vanlig situasjon: i et av selskapene, på grunn av jevnlige forespørsler fra markedsavdelingen til regnskapsavdelingen om salgsstrukturen, måtte regnskapsførere manuelt samle informasjon i de nødvendige informasjonsseksjonene. Dette skyldtes det faktum at salgsavdelingen ikke alltid la inn de nødvendige dataene i katalogen for automatisk generering av de nødvendige rapportene.
– Inkompatibilitet av deler automatisert system regnskap.
For eksempel vedlikeholder forsyningsavdelingen registre og kataloger for ITC i Cache-programmet, og regnskaps- (økonomi-) og ledelsesregistre og kataloger vedlikeholdes i SAP R3, og selskapsrapportering genereres også der. Datapresentasjonsformatene i disse programmene er forskjellige, så konvertering av data mellom dem er vanskelig, og i noen tilfeller direkte umulig.
Når du utvikler oppslagsverk, bør følgende prinsipper følges.
– Detaljen og strukturen til kataloger bør være slik at det er mulig å raskt behandle data og generere de nødvendige rapportene.
Dersom oppslagsboken ikke er detaljert nok, vil dette gjøre det vanskelig å skaffe nødvendig informasjon. For eksempel, hvis du i midten av året trenger å vite om kostnadene ved produksjon reklamebrosjyrer etter ordre fra markedsavdelingen, og før det ble tatt hensyn til alle markedsføringskostnader samlet, vil det være nødvendig å foreta et ekstra utvalg av informasjon basert på indirekte indikatorer (for eksempel ved trykkerier). (For beholdninger eller grupper av selskaper vil detaljene i katalogene avhenge av kravene til strukturering av informasjon, ikke bare for et enkelt foretak, men også for hele beholdningen.)
Hvis oppslagsboken er veldig detaljert, er det vanskelig å fylle den med informasjon og bruke den i arbeidet ditt. For eksempel kan "Cash Flow"-katalogen inneholde mer enn tusen ulike formål innbetaling. Utarbeidelse av kontantstrømoppstilling for grunnbetalinger vedr daglig leder vil kreve mye tid, siden du må utføre den nødvendige grupperingen (sammenslåing av indikatorer eller valg av nødvendig informasjon fra en rekke overflødig informasjon). I tillegg, når du legger inn informasjon, kan det hende at brukeren ikke vet hvor en bestemt betaling skal inkluderes. Dette vil uunngåelig føre til feil valg av varer fra katalogen eller klassifisering av betalingen som "annet". Det kan anbefales å beskrive i detalj hvilke regnskapsobjekter som kan reflekteres for hver linje i katalogen.
– Koding av katalogelementer bør eliminere duplisering av informasjon og bidra til å fremskynde arbeidet med katalogen. Før du koder data, er det nødvendig å bestemme i hvilket av bedriftsinformasjonssystemene referansekatalogene skal lagres. Muligheten for å bruke visse koder vil i stor grad avhenge av systemets muligheter. Et slikt system kan være et regnskapsprogram, hvorfra informasjon automatisk overføres til andre systemer som bruker samme kataloger.
– Du bør unngå å bruke lignende kodinger i forskjellige kataloger.
For eksempel, hvis markedsavdelingen, når den analyserer salg, identifiserer kjøpergrupper ikke etter region, men etter by og region, bør gruppene for analyse ikke falle sammen med kodene til føderale regioner. Ellers vil dette føre til feil ved inntasting av informasjon. Dermed er koden "77" satt for Moskva, og Belgorod-regionen er oppført under denne koden på bedriften. Som et resultat kan den ansatte tilskrive bestemt type salg ikke til regionen, men til Moskva, og informasjonen vil bli forvrengt. I dette tilfellet anbefales det å lage koder med forskjellige lengder, for eksempel for å kode markedsføringsgrupper, bruk tre sifre (kode "770" for kunder i Belgorod-regionen);
– Ideelt sett Katalogkoden må ikke overstige 8 tegn. Ellers er data vanskelig å legge inn da kodene ikke lett kan skilles fra hverandre.
– Når du oppretter sammenkoblede kataloger, bør duplisering elimineres. For å unngå feil i kataloger (på grunn av den usystematiske og kaotiske naturen ved å fylle dem ut), er det nødvendig å analysere informasjonen i dem for å identifisere data som kan genereres av individuelle kataloger.
– Har utviklet seg enhetlig system kataloger, er det nødvendig å sikre beskyttelsen mot uautoriserte endringer. Tilstrekkelig høy sikkerhet kan vanligvis oppnås både ved bruk av brukeridentifikasjonsmetoder og gjennom avgrensning av brukerrettigheter til informasjon. Oftest, for å opprette og vedlikeholde kataloger, utvikler selskaper forskrifter som bestemmer hvem som er ansvarlige for å legge inn informasjon i kataloger og endre den.
Avslutningsvis skal det sies at det er nødvendig å løse ovennevnte problemer før man setter opp kartlegging. Ellers er det lite sannsynlig at ledelsesrapportering kan genereres. Selv om det genereres rapportering, er sannsynligheten for at den blir korrekt praktisk talt null. Årsakene er åpenbare:
- Feil som vil dukke opp på grunn av tidligere beskrevne problemer.
- Regnskapsfeil (både metodiske og regnskapsmessige). Folk fører opptegnelser, ikke glem det.
- Deretter bør vi gi en lang liste over ulike typer feil, hvor kilden vil være resultatene av overlagringen av paragraf 1 og 2. Etter vår mening er dette imidlertid unødvendig.
Selskaper som bruker Excel tilål får konkrete besparelser når de utarbeider regnskap i henhold til IFRS. Hvis transaksjonsvolumer tillater at legitimasjon kan behandles regneark, er det tilrådelig å bruke Excel
12.01.2016Excel-tabeller, i tillegg til aritmetisk nøyaktighet og klarhet i transformasjonsprosedyrer, lar deg generere data for økonomisk analyse finansielle aktiviteter basert på IFRS-resultater, som gjør rapporteringsmodellen til et styringsverktøy.
Forberedende fase av rapporteringstransformasjon
På forberedende stadium Det gjennomføres en analyse av spesifikke forskjeller mellom IFRS gjeldende for et gitt selskap og regnskapspraksis under RAS. Det skal bemerkes at det er upassende å starte fra reglene for russisk regnskap, siden det i dette tilfellet vil være vanskelig å komme vekk fra "prioriteringen av form fremfor innhold" - du bør starte med en analyse av selskapet som helhet og dets aktiviteter fra IFRS-synspunkt.
Internasjonale standarder som er relevante for hver spesifikk virksomhet må inkluderes i regnskapsprinsippene under IFRS. For eksempel er det usannsynlig at en handelsenhet vil bruke komplekse finansielle instrumenter eller bestemmelsene i IAS 41 Landbruk, og et privat selskap er ikke pålagt å opplyse om resultat per aksje i henhold til IAS 33 Resultat per aksje. Prosedyren for å utvikle en regnskapsprinsipp bør ikke bare være rettet mot å lage regnskapsregler og notater i samsvar med IFRS, men også på å utarbeide en noteblokk direkte til IFRS-uttalelsene, som inneholder hovedaspektene ved regnskapsprinsippene som skal opplyses i i samsvar med IAS 1 «Presentasjonsregnskap».
Basert på innhentede regnskapsprinsipper under IFRS, er det nødvendig å identifisere avvik i estimatene og prinsippene som brukes i RAS, og lage en liste og regler for beregning av de viktigste transformasjonsjusteringene, samt en liste over tilleggsinformasjon som er nødvendig for IFRS-formål, men ikke tatt i betraktning i samsvar med kravene i russisk lovgivning.
Når du bruker internasjonale standarder for første gang i henhold til IFRS 1, bør du være klar over unntakene og forenklingene som standarden tillater, og at disse lettelsene ikke lenger gjelder.
Prosessen med å oppdatere regnskapsprinsipper under IFRS, listen over justeringer og listen over tilleggsinformasjon må være konstant, siden kravene i IFRS og russisk lovgivning kontinuerlig oppdateres.
Kontoplanskartlegging for rapporteringstransformasjon
Kartlegging - fra engelsk mapping (korrespondanse, samt transformasjon) - er en prosedyre for å bokføre data i flere koordinatsystemer, i vårt tilfelle konvertere saldoer og omsetning generert i henhold til RAS kontoplanen til strukturen til oversikten over regnskap etter IFRS (tabell 1).
Tabell 1. Eksempel på kontoplankartlegging
Noen ord om å utarbeide selve kontoplanen etter IFRS.
- Hver IFRS-indikator må ha en unik digital kode, i ekstreme tilfeller alfanumerisk, i et strengt definert format. Oppsummering av indikatorer i moderne Excel-versjoner det er mulig selv basert på tekstkarakteristikker, men i dette tilfellet øker risikoen for dataforvrengning ved en enkel skrivefeil. For å minimere feil brukes kataloger og nedtrekkslister med koder og navn på kontoer og analyser, samt "SUMMIF" og "VLOOKUP" formler som oppsummerer data med spesifiserte egenskaper, nemlig unike koder.
- Hierarkiet til kontoplanen skal tillate deg å gruppere data ikke bare etter elementer, men også etter linjer i rapporteringsskjemaet og notater. La oss si at artikkelen "Bygninger og konstruksjoner - Startkostnad", i tillegg til sin egen kode, også bør inneholde blant analysene linjekoden for balansen (heretter referert til som balansen) og koden for notattabell, som lar deg fylle ut skjemaer og rapporteringsnotater i tabellform ved hjelp av Excel-formler.
- Hver del av rapporteringsskjemaene i kontoplanen skal inneholde reservedeler tomme linjer- dette gjør det mulig å fleksibelt justere kontoplanen uten å rekonfigurere formler, og lar deg også ikke bryte prinsippet om datasammenlignbarhet. Det er tilrådelig å gi plass til nye seksjoner, for eksempel hvis selskapet ikke tidligere har eid investeringseiendom, men ledelsen planlegger å opprette eller anskaffe eiendom for utleie. I dette tilfellet fyller du ganske enkelt ut de tomme radene og skriver inn rapporteringskoder, og Excel samler automatisk indikatorene.
- Det er nødvendig å lagre historikken for endringer i kartleggingen (vanligvis på grunnlag av et notat eller annet administrativt metodologisk dokument) som angir årsaken, den ansvarlige og tidspunktet for at endringene trer i kraft. Dette er viktig både for å generere sammenlignbare data fra periode til periode og for å bestå en revisjon.
Det skal bemerkes at jo mer analytikeren inneholder den russiske kontoplanen, desto lettere er det å gjennomføre kartleggings- og omklassifiseringsjusteringer som er nødvendige ifm. ulike prinsipper dataaggregering i RAS og IFRS. Derfor, hvis mulig, bør RAS-kontoplanen og dens analyser bringes så nært som mulig til behovene til IFRS for å øke effektiviteten i transformasjonsprosessen og redusere kostnadene.
Innsamling av nødvendig informasjon for å fylle ut transformasjonsmodellen. På dette stadiet samles data om balansekontosaldo og omsetning av inntekts- og kostnadskontoer for rapporteringsperioden, den første balansen og resultatregnskapet fylles ut.
Sammen med denne prosessen gjennomgås betydelige transaksjoner, rettssaker, store nye kontrakter og tilleggsopplysninger. Det bør utarbeides en regulert liste over tilleggsinformasjon, samt at de som er ansvarlige for utarbeidelsen av de relevante dataene bør tildeles og tidsfrister bør fastsettes.
Listen som er presentert i tabell 2 kan enten forkortes dersom bedriften ikke har bestemte virksomheter, eller utvides vesentlig. Som regel skjer det sjelden endringer i virksomhetens aktiviteter som medfører ytterligere tilpasninger til IFRS. Derfor gjøres den mest grundige analysen under det første bekjentskapet med virksomheten, og først da overvåkes betydelige endringer. Derfor bør selskaper i de fleste tilfeller foreta rundt ti til tjue transformasjonsjusteringer, som kan reguleres av hensiktsmessige metodiske instruksjoner og er nedfelt i dokumentet "Prosedyre for regnskapsføring av transformasjonsjusteringer".
Tabell 2. Eksempelliste med tilleggsinformasjon
Alle justeringer bør gjøres i form av et arbeidsdokument som ligner på en regnskapsoppgave. Arbeidsdokumentet skal inneholde metodisk grunnlag og de faktiske premissene som ble foretatt visse justeringer på grunnlag av, og selve beregningene. Det er også nødvendig å etablere kontrollprosedyrer som tar sikte på å kontrollere korrektheten av beregninger, avstemming av data fra arbeidsdokumenter og transformasjonsmodeller, samt riktigheten av transaksjoner.
Stadium av dannelsen av innkommende justeringer. Inngående justeringer genereres ved første gangs anvendelse av IFRS, samt ved transaksjoner som involverer oppkjøp av nye selskaper, som skal måles til virkelig verdi.
Til å begynne med er balanse- og resultatpostene omgruppert. Dette er såkalte omklassifiseringsjusteringer. Større reklassifiseringsjusteringer inkluderer reversering eller reversering av kundefordringer, gjeld og forskudd, reklassifisering av utsatte utgifter, separasjon av omløps- og langsiktige eiendeler og gjeld, overføring av innskudd med løpetid på mindre enn 90 dager til kontanter, og en mer detaljert bokføring av inntekter og utgifter til tilhørende konti, dersom slikt arbeid ikke ble utført på kartleggingsstadiet (tabell 3).
Tabell 3. Eksempel på omklassifiseringstabell
Neste blokk med justeringer er korreksjoner som påvirker mengden av balanseposter, samt inntekter og kostnader. De skal ikke forveksles med reklassifiseringsjusteringer, siden bare estimerte justeringer påvirker beløpet av utsatt skatt under IFRS.
I praksis er de vesentligste justeringsbeløpene knyttet til måling av eiendeler til virkelig verdi - anleggsmidler (særlig i tilfeller hvor selskapet eier gamle eiendeler) og immaterielle eiendeler. Det er umulig å beregne slike justeringer på egen hånd, siden dette krever data fra en undersøkelsesrapport utført av en kvalifisert takstmann. For eksempel uten spesiell kunnskap og erfaring er det umulig å bestemme kostnaden kundebase, som ved kjøp av et selskap skal regnskapsføres som en immateriell eiendel under IFRS. Bare etter å ha mottatt verdsettelsesdata om det virkelige beløpet av opprinnelig kostnad, grad av avskrivning, gjenstår nyttig liv bruk, registre over anleggsmidler og immaterielle eiendeler dannes i henhold til IFRS. Regnskap for anleggsmidler og immaterielle eiendeler kan utføres som i eget program, og i regneark, når det føres register over anleggsmidler i Excel, reflekteres mottak, moderniseringer, avhending av objekter, avskrivninger beregnes til kostnadsført i henhold til IFRS.
Den enkleste måten å beregne justeringer på er å sammenligne RAS- og IFRS-data og bestemme avviket mellom dem. Disse beløpene utgjør endringen (tabell 4).
Tabell 4. Beregning av justeringer for omvurdering av anleggsmidler til virkelig verdi
I tillegg til å reflektere omvurderingen, kan det for anleggsmidler og immaterielle eiendeler være nødvendig å omberegne beløpet for kapitaliserte renter, siden RAS og IFRS inneholder ulike tilnærminger til å bestemme størrelsen på kapitalisering.
Bestemmelsene i IAS 36 Nedskrivning av eiendeler fokuserer også mer på testing av eiendom, anlegg og utstyr og immaterielle eiendeler, hvis verdi må justeres når det er bevis på verdifall.
Dersom et selskap bruker finansielle leieavtaler i sin virksomhet (som tolket av IFRS), kan endringene også påvirke mengden av eiendom, anlegg og utstyr og avskrivningskostnader, i samsvar med finansielle leieforpliktelser og rentefordringer for bruk av lånemidler.
Spesiell oppmerksomhet bør rettes mot justeringer knyttet til diskontering (som for eksempel ved langsiktige finansielle leieavtaler, hvor både kostnaden for anleggsmidler og gjelden under finansielle leieavtaler estimeres på grunnlag av diskontering). IFRS krever neddiskontering av alle langsiktige eiendeler og forpliktelser:
- inntektsbeløpet når betalingen er utsatt i tide;
- beløpet til en langsiktig reserve eller avsetning i samsvar med IAS 37 «Avsetninger, betingede forpliktelser og betingede eiendeler»;
- kostnadene ved å investere i et datterselskap når det gis utsatt betaling for aksjer;
- gjeldskomponent i langsiktige konvertible obligasjoner;
- gjenvinnbart beløp for en finansiell eiendel regnskapsført til amortisert kost ved testing for verdifall osv.
Blant de vanligste justeringene kan vi også merke oss:
- for varelager (avskrive illikvide varelager som tap, opprette en reserve for avskrivning av varelager, avskrive mangler og tap fra skade på verdisaker, samt visse typer utsatte utgifter);
- for oppgjør med personell (justeringer av reserver for ferier, opprettelse av en reserve for fremtidig godtgjørelse, oppgjør under pensjonsplaner);
- Cutoff-justeringer (avskriving av utsatt inntekt, ytterligere periodisering eller avskrivning av inntekter og utgifter i rapporteringsperioden som ikke ble reflektert i RAS på grunn av mangel på dokumenter eller forskjeller i tilnærmingen til å anerkjenne tidspunktet for overføring av risiko og fordeler, i korrespondanse med kontoer for oppgjør med motparter);
- for kundefordringer og -gjeld, samt lån og innlån (refleksjon til amortisert kost ved bruk av effektiv rentemetode, justering av reserver for tapsutsatte fordringer);
- på finansielle investeringer (innregning av andel i resultatet i tilknyttede selskaper, verdijusteringer av finansielle investeringer som kan fastsette dagens markedsverdi mv.).
Etter at alle estimerte justeringer er generert, fastsettes beløpet for utsatt skattejustering.
Selvfølgelig er ikke alle mulige justeringer listet opp, siden målet er å demonstrere hvordan poolen av innkommende justeringer dannes og hvordan justeringer skal overføres fra år til år (tabell 5).
Tabell 5. Dannelse av liste over innkommende justeringer
Deretter utarbeides det, med hensyn til inngående justeringer, balanse, resultatregnskap, kapitalendringer, kontantstrømoppstilling i IFRS-format, og det utarbeides også forklaringer til oppgavene.
Primære justeringer brukes til å overføre til rapportering av påfølgende perioder som inngående justeringer. Det er to overføringsmetoder:
- justeringer av balansekonti tas i betraktning i samsvar med kontoen for tilbakeholdt overskudd;
- justeringer av inntekts-/kostnadskontoer reverseres i samsvar med opptjent egenkapital.
Valg av overføringsmetode påvirker kun teknikken for å beregne løpende justeringer for påfølgende rapporteringsperioder, sluttresultatet blir det samme, men det vil ikke lenger være mulig å endre modell for beregning av justeringer, så du bør bestemme på forhånd mest praktisk metode og hold deg til den.
Stadium for dannelse av justeringer for påfølgende rapporteringsperioder. Typiske justeringer i følgende rapporteringsperioder skal utarbeides under hensyntagen til innkommende justeringer. Mekanismen for å generere IFRS-data er som følger: Excel-tabeller fylt ut side for side:
- kartlegge saldoer og omsetning etter RAS til saldoer og omsetning etter IFRS;
- omklassifiseringsjusteringer;
- innkommende justeringer (unntatt omklassifiseringer fra forrige periode);
- justeringer for inneværende periode (beregnet i egne arbeidsdokumenter med hensyn til akkumulerte inngående justeringer).
Deretter, ved hjelp av "SUMIF"-formlene, trekkes dataene opp på sammendragsarket (se tabell 6).
Tabell 6. Dannelse av IFRS-data i transformasjonsmodellen
IFRS-data (kolonne 8) innhentes ved å summere de opprinnelige RAS-dataene, reklassifiseringer, inngående og aktuelle justeringer. På neste trinn, også ved bruk av "SUMMIF"-formelen, aggregeres ferdige IFRS-indikatorer på rapportsidene (balanse, resultatregnskap) etter linjekoder for rapporteringsskjemaer i samsvar med den tildelte rapporteringsskjemakoden (tabell 7). . På samme måte fylles tabellform av noter ut, kontroll- og avstemmingsformler skrives mellom transformasjonstabellen, rapporteringsskjemaer og noter, og endringen i opptjent overskudd for perioden sammenlignes med åpnings- og utgående balanse for indikatoren ( avvik i mengden av påløpte utbytter er mulig).
Tabell 7. Eksempel på bruk av Excel "SUMIF"-funksjonen
Som vi kan se, lar Excel deg ganske enkelt og tydelig generere IFRS-data gjennom transformasjon. I praksis brukes også andre tilnærminger til å fylle ut transformasjonstabeller, for eksempel som et klassisk sjakksett. Men hvis det er mange justeringer, vil de resulterende filene være store og risikoen øke. tekniske feil Dessuten blir det vanskelig å analysere endringer akkumulert over flere perioder. Uansett hvilken transformasjonsmodell som brukes, er det universelle anbefalinger for å jobbe med Excel: data bør lagres på pålitelige servere beskyttet mot uautorisert tilgang, automatisk opprettelse av sikkerhetskopier av hovedarbeidsfilene og automatisk lagring under arbeid, regelmessig arkivering av begge primære. data og endelige modeller, sporing av endringer i filer og vedlikehold av en oppsummerende statusfil (sjekkliste) som inneholder informasjon om nødvendige stadier av transformasjon og fullføringsgrad av etablerte prosedyrer.
Kjære venner!
I dag er vi glade for å informere deg om at våre utviklere har implementert muligheten til å transportere data via URL (mapping) utover målsiden.
Ved å bruke denne funksjonen kan du overføre all data fra skjemafeltene til siden som brukeren går til når han sender deg et kundeemne. Takket være dette kommer leadet ikke bare inn i , men kan også umiddelbart komme inn i databasen din hvis han blir "møtt" av det tilsvarende skriptet på omdirigeringssiden.
Nå er det ikke nødvendig å eksportere data fra lead-behandlingssystemet! Du kan sende og behandle dem umiddelbart i din egen database!
Takket være denne funksjonen blir det også mulig å gratulere eller takke brukeren som ga kontaktinformasjonen sin personlig.
Hvordan fungerer kartlegging?
Essensen av kartlegging er at når du sender data fra skjemafelt, blir innholdet deres lagt til lenken som omdirigeringen skjer til. Nettadressen blir: //my_site.com/?name=NAME&email=EMAIL_ADDRESS&phone=PHONE_NUMBER&lead_id=225298.
Viktig! I tillegg til alle feltdata sendes lead-ID-en alltid i lead_id-parameteren.
På siden som overgangen gjøres til, blir denne informasjonen "mottatt" av et spesielt skript, som igjen distribuerer dataene til de riktige "cellene".
Få oppmerksomheten din til! Kartlegging fungerer bare hvis "Skjemaresultat" er "Gå til URL"!
Hvordan kan jeg sette opp «transport» av et potensielt kundeemne etter URL (mapping) på landingssiden min?
1. Logg inn.
2. Velg siden med kundeemneskjemaet du skal «kringkaste» dataene fra.
3. I redigeringsprogrammet gjør du Dobbeltklikk etter skjema.

4. I vinduet som vises fyller du ut «Mapping»-kolonnen med de tilsvarende feltnavnene på engelsk. For eksempel navn - navn, telefon - telefon osv.

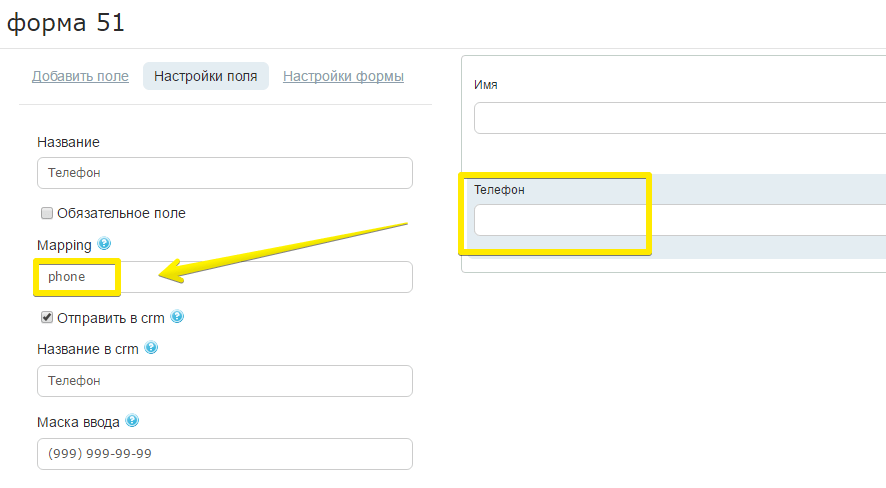
5. Lagre endringene.
6. I skjemaegenskapene konfigurerer du omdirigeringen til ønsket side- Dette kan være en side på nettstedet ditt der JavaScript er innebygd, som vil behandle dataene fra feltene mottatt fra URL-en.
Merk av for "Passskjemafelt".

7. Lagre endringer i hovedredigeringsmenyen.

Det er alt! :-)
Nå vil dataene fra skjemafeltene dine bli overført til siden du omdirigerer brukeren til. Du trenger ikke å eksportere kundeemner fra CRM LPgenerator - de kan "transporteres" til din CRM direkte via URL. Mulighetene for kartlegging for transport av data er virkelig ubegrensede.